2.2 深度学习环境安装#
在上一节内容中我们详细介绍了深度学习环境中的一些基础知识,在本节内容中我们将进一步来介绍如何分别在Windows平台和Linux平台上安装基于Python的深度学习环境,并完成相关的测试。
2.2.1 Windows环境下#
由于深度学习框架和相关的库通常是在Linux上开发和测试的,因此在Windows上可能会遇到一些兼容性问题。同时,在相同的硬件基础上软件在Linux上的性能通常比在 Windows上更好,并且在Linux上也更容易进行优化。因此通常我们只会在Windows环境下安装CPU版本的PyTorch用于程序编码,然后再放到GPU环境中进行训练。
1. Conda安装
首先在官网 [1]下载最新版Windows平台下的Miniconda3安装包,然后按照如下安装步骤进行即可。
①安装Miniconda
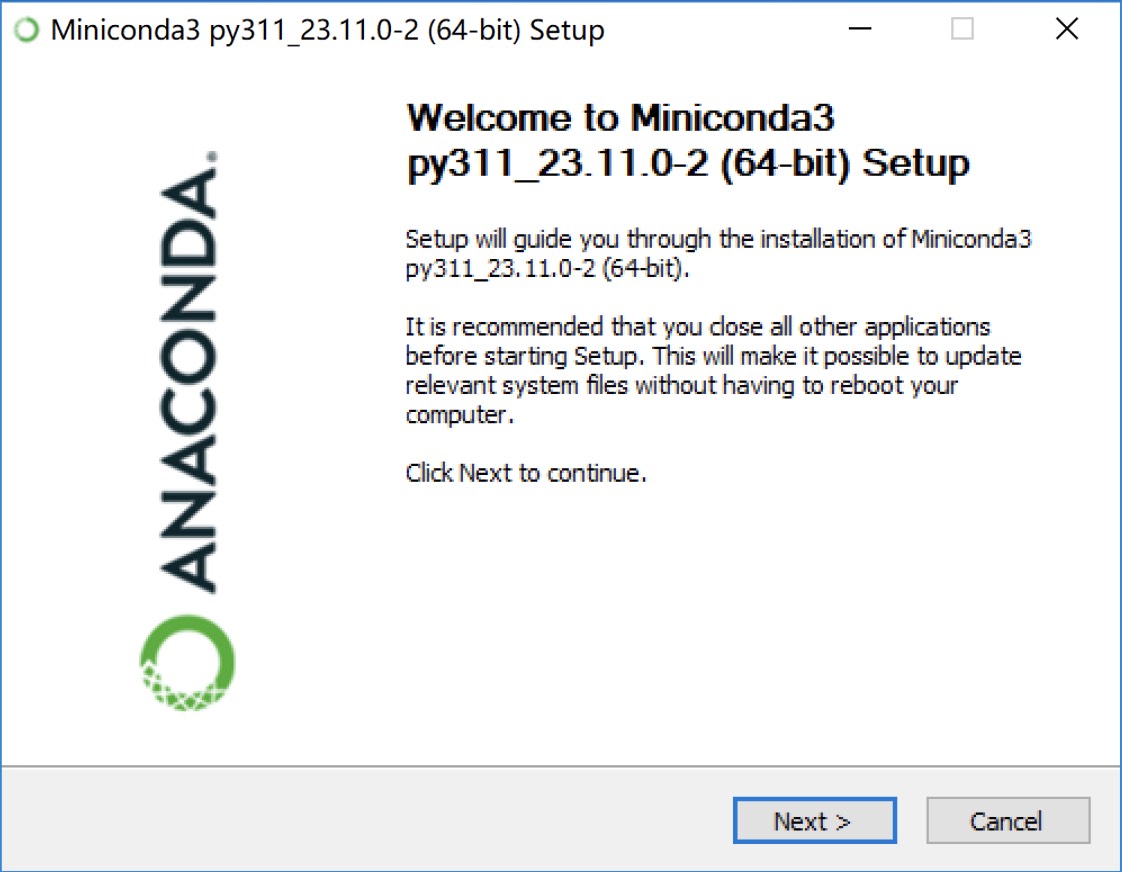
双击扩展名为.exe的安装包进行安装,如果后续无特殊说明,保持默认安装项并直接单击Next按钮即可,如图2-2所示。
②指定安装目录
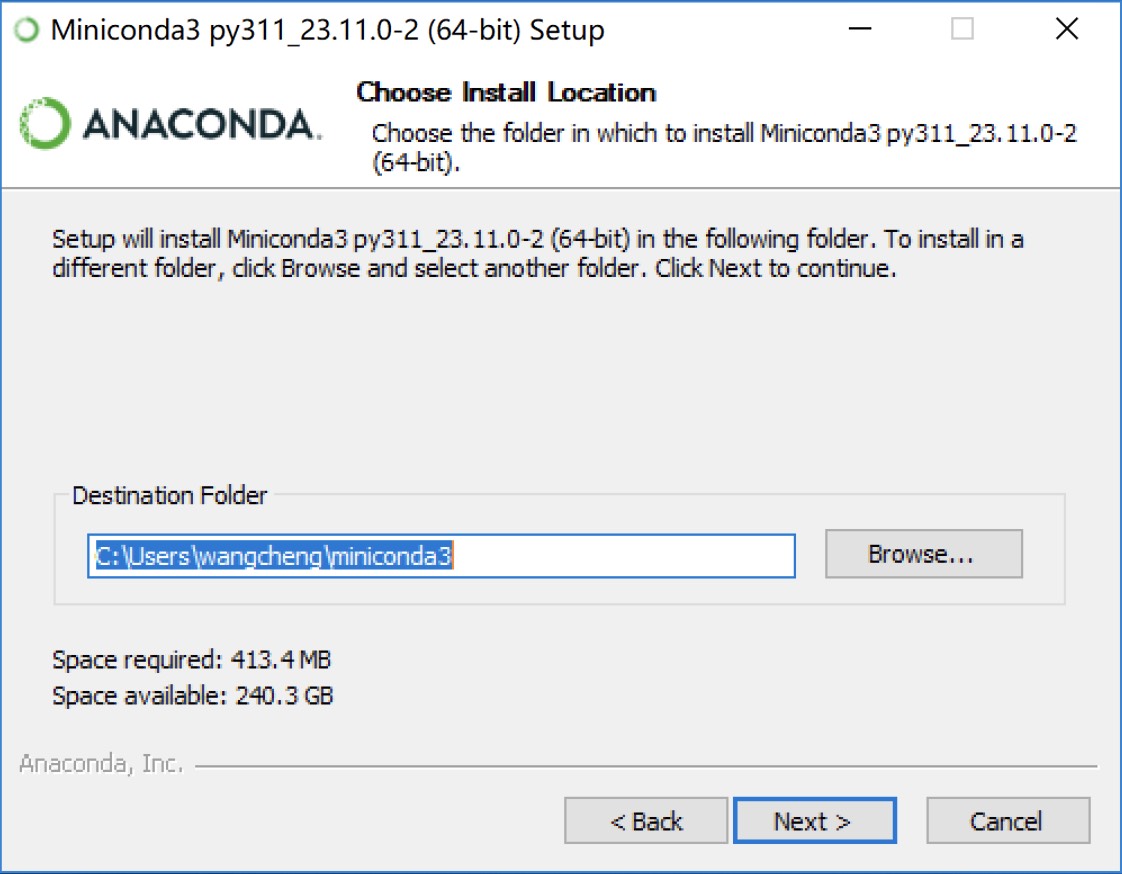
在安装过程中还可以自定义安装路径,但一般情况下保持默认安装路径即可,如图2-3所示。
③高级设置
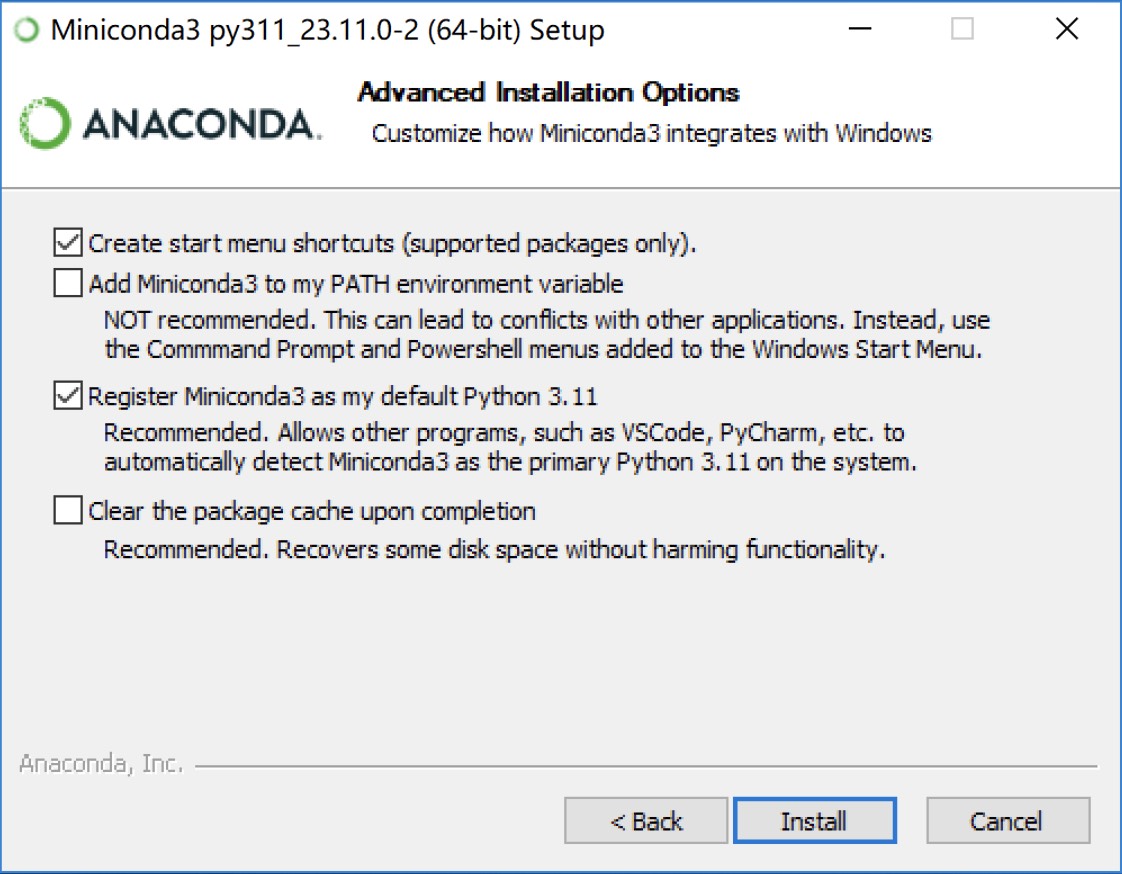
当安装过程执行到这一步时,保持默认直接单击Install按钮即可,如图2-4所示。
④安装完成
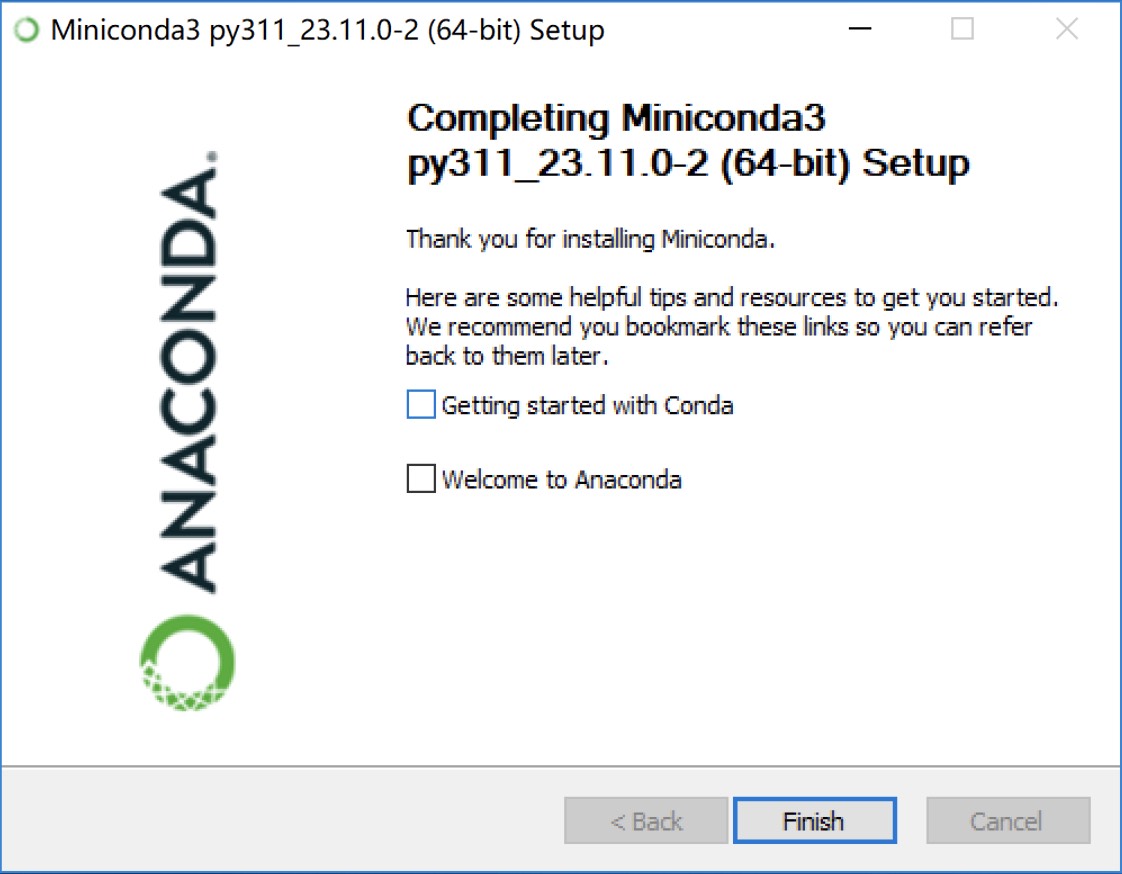
安装完成后,单击Finish按钮,如图2-5所示。接下来可以通过打开命令行,然后输入相关命令来测试是否安装成功。
⑤验证
当完成上述安装后,便可以在“开始”菜单栏中找到Anaconda Prompt(Miniconda)命令行终端,单击此命令行终端,打开后输入conda -V命令,如果出现相关版本信息则表示安装成功,如图2-6所示。

同时,根据图2-6所示在完成Miniconda安装以后会有一个默认名为的base的Python环境。
⑥替换源
在安装完成Miniconda后,这里需要将默认的Conda源替换成清华大学对应的镜像源。我们直接在图2-6所示的界面中继续输入如下两行命令:
1 conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
2 conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/2. Python环境安装
在完成Conda包管理器的安装以后,我们根据2.1.3节中的conda create -n py38 python=3.8命令新建一个名为py38的Python虚拟环境,如图2-7所示。

从图2-7可以看出,新建py38这一虚拟环境时所使用到的Conda源便是我们上面添加的清华Conda源。同时,py38这个虚拟环境的保存路径为C:\Users\wangcheng\miniconda3\envs\py38目录。值得一提的是,对于每个Python虚拟环境来说,通过pip install命令安装的Python包及其安装文件都在虚拟环境下的lib\python3.x\site-packages中,知道该路径便于在需要时查找源码。例如对于py38这个虚拟环境来说,安装文件均在C:\Users\wangcheng\miniconda3\envs\py38\lib\python3.8\site-packages里面。
进一步,在安装完成以后我们便可以通过命令conda activate py38来激活我们新建的Python环境,如图2-8所示。

如图2-8所示,我们激活py38这个虚拟环境以后命令行最前面的(base)已经变成了(py38),而这也是一个有效分别当前终端中所使用Python环境的方法。同时,我们通过conda env list命令也列出了当前Conda中所存在的所有虚拟环境。
最后,我们同样需要将py38这个Python虚拟环境对应的pip源切换为相应的清华镜像源,直接在图2-8所示的界面输入如下命令:
pip config set global.index-URL https://pypi.tuna.tsinghua.edu.cn/simple这样,我们的Python环境就安装好了,下面我们安装对应的PyTorch框架。
3. PyTorch安装
在进入py38这个虚拟环境以后,我们只需要通过命令pip install torch==2.0.1来安装PyTorch框架即可,安装过程如图2-9所示。

在完成PyTorch的安装过程后,我们可以直接在当前命令行中进行验证。首先我们输入python这个命令进入到Python对应的交互式界面,然后通过import torch导入PyTorch并输出对应的版本,如图2-10所示。

如果上述过程没有任何错误提示则表示我们已经成功在Windows环境下完成了PyTorch框架的安装。
2.2.2 Linux环境下#
在Linux环境下的PyTorch安装过程整体上同Windows环境下一致,只是多了一步GPU驱动的安装过程。下面,我们以Linux中的Ubuntu 22.04发行版为例来介绍安装基于GPU加速的深度学习环境。当然,如果仅仅只是在Linux环境下安装CPU版本的PyTorch,则可直接跳过下面的第1步。
1. 驱动安装
在安装驱动之前我们可以通过 lspci | grep -i nvidia命令来查看主机上是否存在GPU设备,如下所示:
lspci | grep -i nvidia
00:07.0 3D controller: NVIDIA Corporation TU104GL [Tesla T4] (rev a1)从反馈结果可以看出,当前主机上有一块型号为Tesla T4的显卡设备。
① CUDA Toolkit安装包下载
根据2.1.2节内容可知,在安装基于PyTorch的GPU环境时我们只需要完成GPU驱动的安装即可。这里,我们首先去官网[2]下载对应版本的CUDA Toolkit包,如图2-11所示。这里需要注意的是,我们下载安装CUDA Toolkit只是为了使用其中所包含的GPU驱动。

如图2-11所示,页面上列出了各个不同版本的CUDA Toolkit。从稳定性来看,一般来说选择版本时尽量不要很新的,也不要很老的。因为CUDA Toolkit版本过低,里面的驱动版本也会偏老会导致后面不能安装更高版本的PyTorch,这里我们选择的11.8进行下载。各位读者到时候也可选择其它版本,这并不会影响后续的安装。
在点击进入相应的版本链接后,我们再根据对应的系统型号选择相应的CUDA Toolki安装包,如图2-12所示。
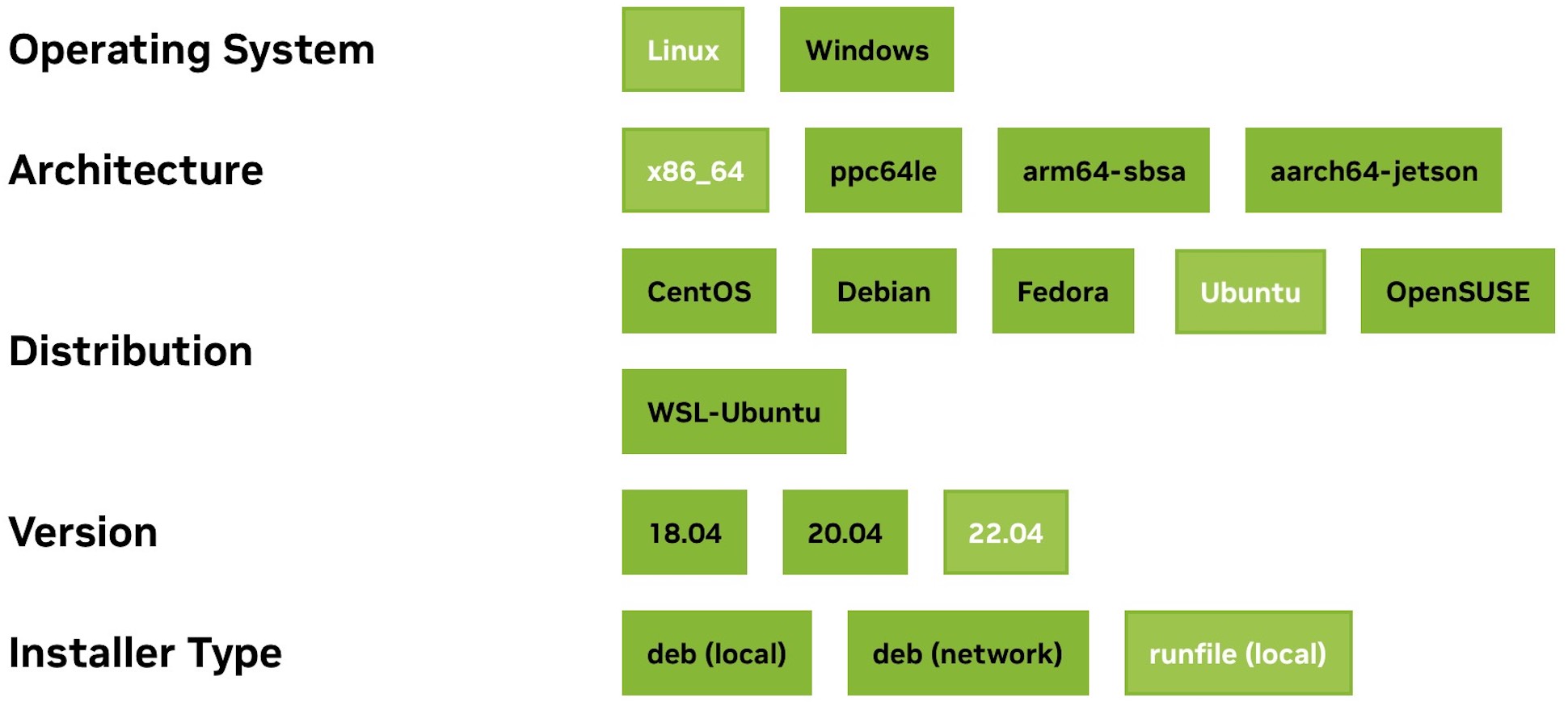
如图2-4所示,从上到下我们依次选择了Linux系统、x86_64架构、Ubuntu 22.04发行版以及runfile的安装类型。在筛选结束后我们便会看到如下所示的按照命令:
1 wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
2 sudo sh cuda_11.8.0_520.61.05_linux.run进一步,我们在Linux主机上通过上述第1条命令来下载CUDA Toolkit安装包,下载完成后将会得到一个名为cuda_11.8.0_520.61.05_linux.run的文件。
② CUDA Toolkit安装
进一步,我们通过上述第2条命令来进行安装。在输入上面命令后,大概30秒左右会看到如图2-13所示的提示内容。
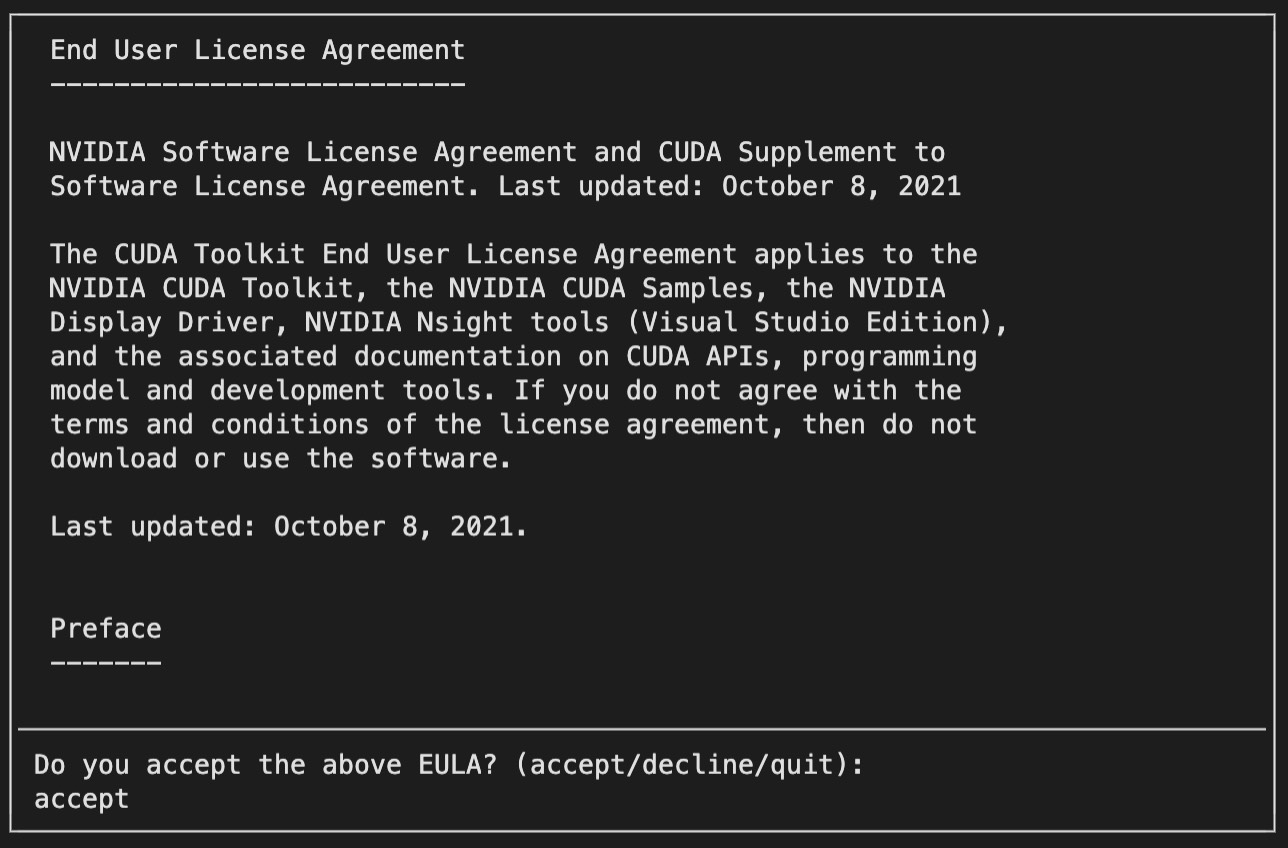
此时,我们输入accept并敲击“回车键”进入下一步,如图2-14所示。
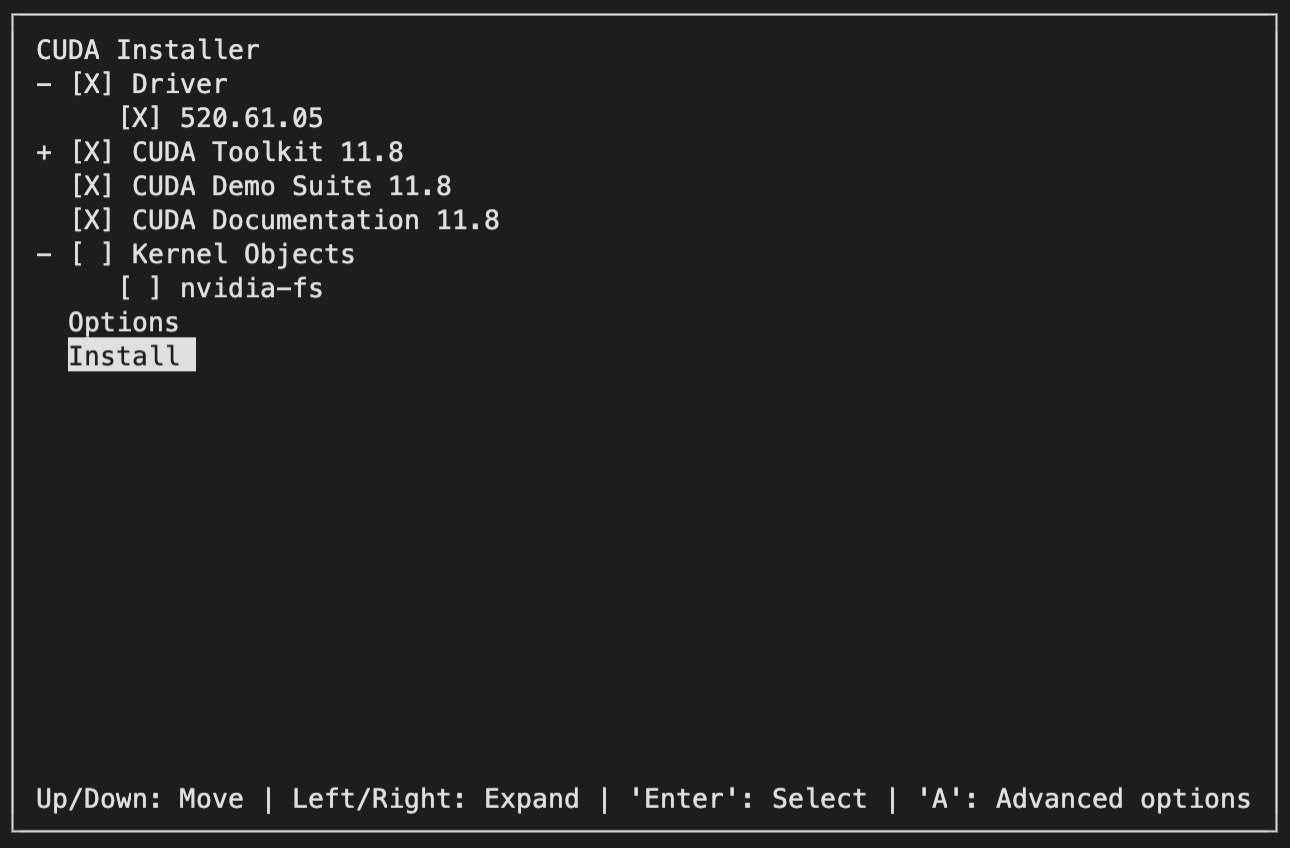
如图2-14所示,保持默认选项,然后按键盘上的“下”键移动至Install选项,并敲击“回车键”进入下一步,如图2-15所示。
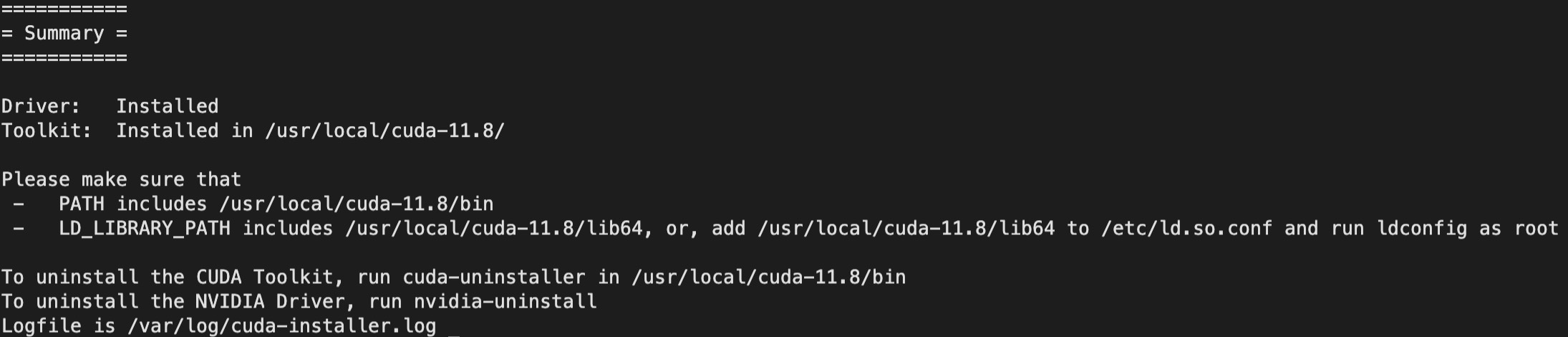
如图2-15所示,我们已经完成了CUDA Toolkit的安装。由于我们后续并不需要使用CUDA Toolkit来编译安装PyTorch,所以我们这里也不需要在PATH和LD_LIBRARY_PAH中加入相关的环境变量。
最后,我们便可以通过nvidia-smi命令来查看主机上的显卡使用信息,如图2-16所示。
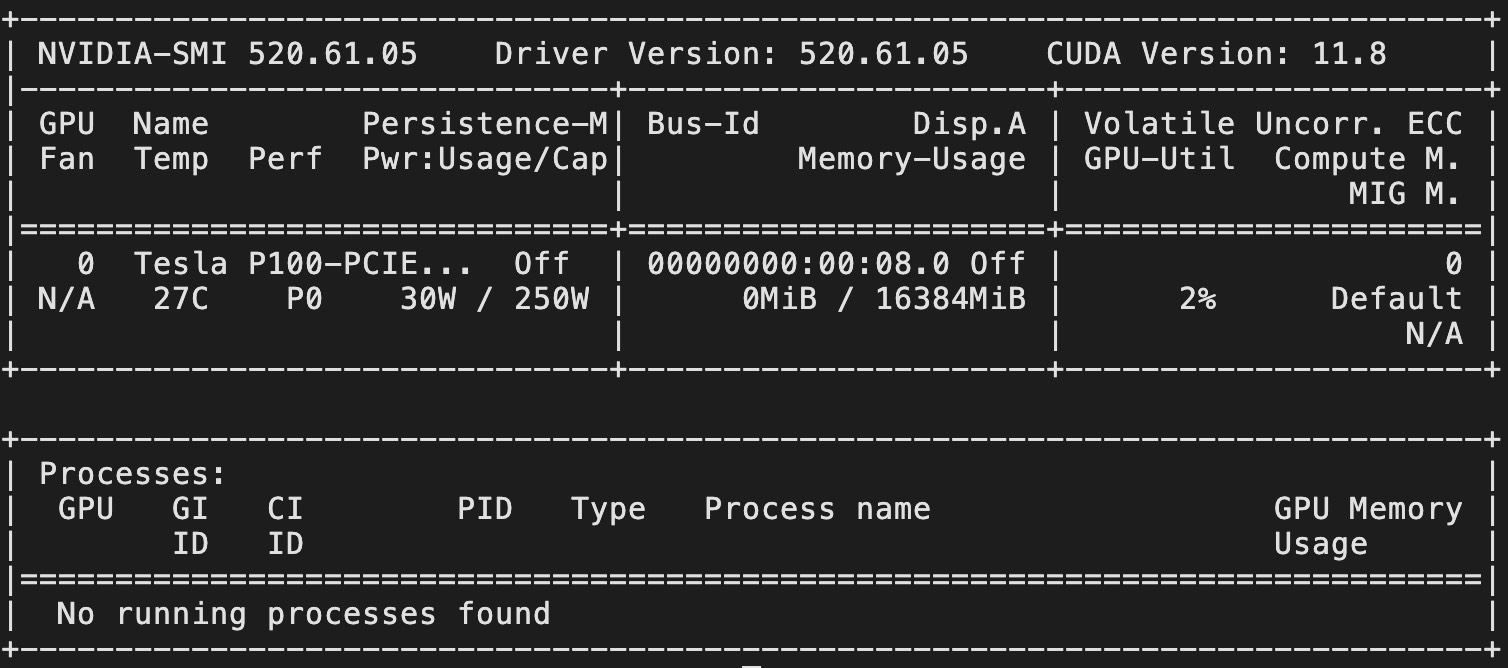
如图2-16所示,我们便可以看到GPU驱动和显卡使用情况的相关信息。
2. Conda安装
在完成GPU驱动的安装以后,我们同样需要安装Conda管理包和Python环境。整体上这一过程同2.2.1节内容一致,只是安装Miniconda过程有所不同。首先同样去官网 [1]查找最版本Linux环境下的安装文件地址,然后在Linux主机上通过如下命令进行下载。
1 wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh在完成下载后我们将会得到一个名为Miniconda3-latest-Linux-x86_64.sh的安装包。进一步,我们通过命令bash Miniconda3-latest-Linux-x86_64.sh进行安装,如图2-17所示。
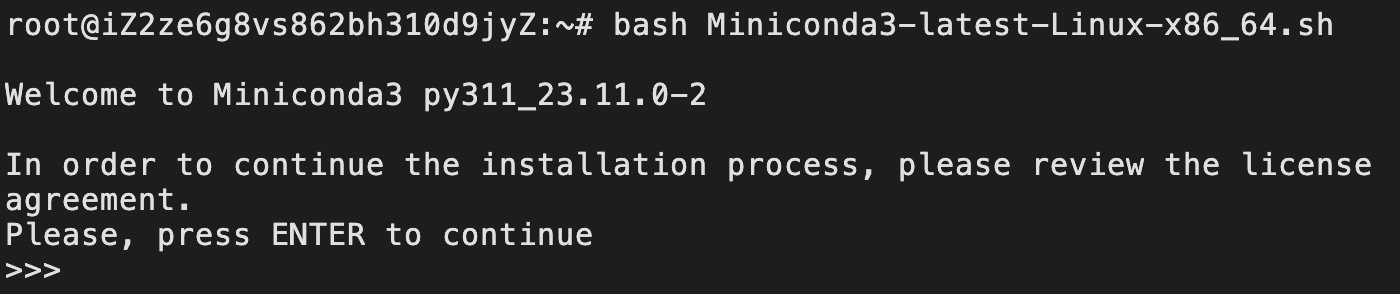
在进入图2-17所示界面以后,我们点击“回车键”进入下一步,如图2-18所示。

如图2-18所示,此时敲击键盘q键退出条款,并在后续输入yes敲击“回车键”接受条款进入下一步,如图2-19所示。
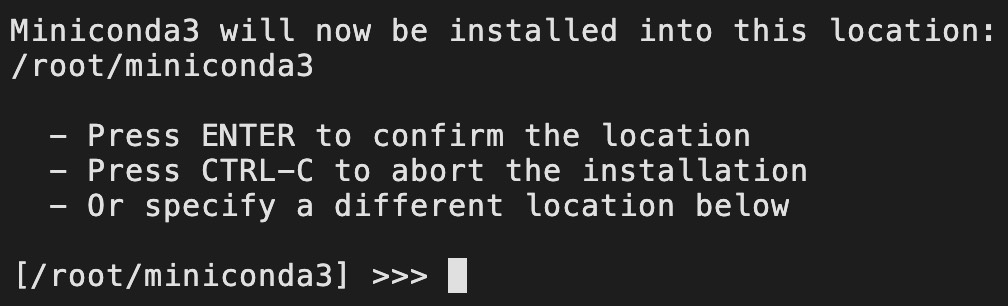
如图2-19所示,我们可以指定Miniconda的安装路径,这里我们直接敲击“回车键”使用默认路径即可,同时进入下一步如图2-20所示。
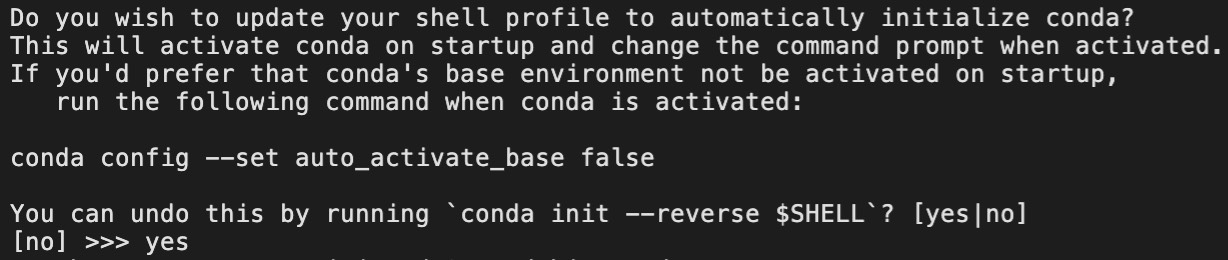
这里提示我们是否要在登录主机以后自动为我们激活默认的Python环境,即base环境,我们选择“yes”直接敲击“回车键”完成最后的安装。
在完成安装以后,我们重新登录Linux主机便可以开始使用Conda管理环境,如图2-21所示。
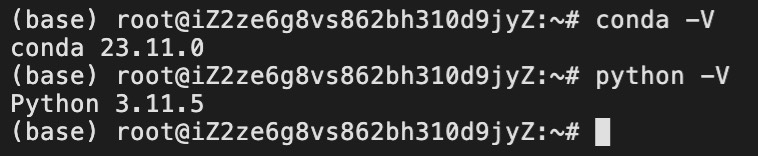
根据图2-21所示,我们已经成功完成了Codna工具的安装,验证结果也同图2-6中一致。最后,我们同样可以根据需要(建议切换)来替换Conda源、创建对应的Python虚拟环境以及替换对应的pip源,过程同2.2.1节内容一致这里就不再赘述。
3. Python安装
在安装完成Conda以后,我们可以开始创建新的Python虚拟环境,这里以Python 3.9的版本为例。首先,我们可以创建一个Python环境,命令如下:
conda create -n py39 python=3.9等待上述过程安装完毕以后,我们切换pip的安装源,命令如下:
pip config set global.index-URL https://pypi.tuna.tsinghua.edu.cn/simple最后,我们可以进入到新的Python环境中,命令如下:
conda activate py39
python -V
# Python 3.9.184. PyTorch安装
在完成Python虚拟环境的安装以后我们便可以激活相应的虚拟环境来安装PyTorch框架。如果是安装CPU版本,则只需要通过命令pip install torch==2.0.1 --index-url https://download.pytorch.org/whl/cpu即可完成安装。下面,我们以3.9版本Python环境为例来安装基于GPU环境的PyTorch框架。
①确定安装版本
首先,我们打开PyTorch官网[1],然会看到如图2-22所示的版本列表情况。

从图2-22中我们可以看出,对于当前最的PyTorch 2.1.2版本来说它支持CUDA 11.8和CUDA 12.1这两个版本的CUDA Toolkit平台。这里需要注意的是,图2-22中的CUDA Toolkit版本和前面我们安装的CUDA Toolkit版本之间没有任何联系,仅仅只是用于筛选我们想要安装由那个CUDA Toolkit平台编译得到的torch安装包。
例如在图2-22中,同样是安装最新版的torch,那么我们既可以通过命令
pip3 install torch 来使用由CUDA Toolkit 12.1平台编译得到的whl安装包进行安装,也可以通过命令
pip3 install torch --index-url https://download.pytorch.org/whl/cu118来使用由CUDA Toolkit 11.8平台编译得到的whl安装包进行安装。在上述命令中,--index-url参数便是用来索引对应平台的安装包。
如果我们需要安装旧版本的PyTorch,可以直接打开网站 [3] 来查找对应版本,如图2-23所示。

不过这里需要注意的是,只有在PyTorch官方网站[4]下载的whl安装包,其中GPU版本里才包含有对应的CUDA和CUDNN库文件,而通过第三方pip源下载的torch安装包并不含有CUDA等库文件,只是额外会通过pip自动安装nvidia-cublas-cu11-11.10.3.66、nvidia-cuda-cupti-cu11-11.7.101、nvidia-cuda-nvrtc-cu11-11.7.99、nvidia-cuda-runtime-cu11-11.7.99和nvidia-cudnn-cu11-8.5.0.96等库文件。所以为了避免出错,建议在安装时指定index-url或者如果网络不好可以手动去网站 [4] 中下载对应的whl安装包上传到服务器手动指定本地文件进行安装。
②安装PyTorch
下面,我们以安装2.0.1版本的PyTorch为例进行演示。从图2-23可知,我们通过如下命令便可以完成基于CUDA 11.8平台编译的PyTorch框架的安装:
1 (py39) root@moon:~# pip install torch==2.0.1 --index-url https://download.pytorch.org/whl/cu118
2 Looking in indexes: https://download.pytorch.org/whl/cu118
3 Collecting torch==2.0.1
4 Downloading https://download.pytorch.org/whl/cu118/torch-2.0.1%2Bcu118-cp38-cp38-linux_x86_64.whl (2267.3 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸━━━━━━━━━━━ 1.6/2.3 GB 22.4 MB/s eta 0:00:29
5 ...
6 Successfully installed MarkupSafe-2.1.3 cmake-3.25.0 filelock-3.9.0 jinja2-3.1.2 lit-15.0.7 mpmath-1.3.0
7 networkx-3.2.1 sympy-1.12 torch-2.0.1+cu118 triton-2.0.0 typing-extensions-4.8.0从上面的输出内容可以看出,这个安装包有2.2G左右,其中的大部分都是CUDA和CUDNN相关的库文件。为此我们可以通过一下方式来进行验证:
1 (py39) root@moon:~# cd /root/miniconda3/envs/py39/lib/python3.9/site-packages/torch
2 (py39) root@moon:~# ll -h lib | grep cud
3 -rwxr-xr-x 1 root root 1.3M Jan 14 15:33 libc10_cuda.so*
4 -rwxr-xr-x 1 root root 680K Jan 14 15:34 libcudart-d0da41ae.so.11.0*
5 -rwxr-xr-x 1 root root 125M Jan 14 15:34 libcudnn_adv_infer.so.8*
6 -rwxr-xr-x 1 root root 116M Jan 14 15:34 libcudnn_adv_train.so.8*
7 -rwxr-xr-x 1 root root 621M Jan 14 15:34 libcudnn_cnn_infer.so.8*
8 -rwxr-xr-x 1 root root 98M Jan 14 15:34 libcudnn_cnn_train.so.8*
9 -rwxr-xr-x 1 root root 94M Jan 14 15:34 libcudnn_ops_infer.so.8*
10 -rwxr-xr-x 1 root root 72M Jan 14 15:34 libcudnn_ops_train.so.8*
11 -rwxr-xr-x 1 root root 147K Jan 14 15:34 libcudnn.so.8*
12 -rwxr-xr-x 1 root root 241M Jan 14 15:34 libtorch_cuda_linalg.so*
13 -rwxr-xr-x 1 root root 1.3G Jan 14 15:34 libtorch_cuda.so*根据上述输出可以看出,在lib这个目录下便存有CUDNN和CUDA相关的库文件。
这里值得注意的是,由于torchvision和torchaudio和torch的版本以及CUDA的编译平台是严格依赖的,所以后续安装这两个包的时候其版本需要根据torch的版本和编译平台来确定。例如上面我们在安装torch后,如果还需要使用到torchvision,根据图2-23可知我们可以通过命令pip install torchvision==0.15.2 --index-url https://download.pytorch.org/whl/cu118来安装。如果直接使用命令pip install torchvision,则会默认安装最新版本的torchvision,但此时由于它的版本与torch==2.0.1不兼容,pip又会自动安装与之匹配的torch版本。如果直接使用命令pip install torchvision==0.15.2,则又因为此时默认安装的是CUDA 11.7编译的版本与我们此处安装的torch不是同一个CUDA编译平台,运行代码时会报错。
③测试PyTorch
在完成PyTorch安装以后,我们可以通过如下脚本来进行测试:
1 import torch
2 device = torch.device('cuda:0')
3 a = torch.randn([2,3,4]).to(device)
4 b = torch.randn([2,3,4]).to(device)
5 c =a+b
6 print(c.device)
7 print("PyTorch版本:",torch.__version__)
8 print("GPU是否可用:",torch.cuda.is_available())
9 print("GPU数量:",torch.cuda.device_count()) # 查看GPU个数
10 print("CUDA版本:",torch.version.cuda) # )
11 print("cuDNN是否启用:",torch.backends.cudnn.enabled)上述代码运行结束以后,我们便可以得到如下输出结果:
1 cuda:0
2 PyTorch版本: 2.0.1+cu118
3 GPU是否可用: True
4 GPU数量: 1
5 CUDA版本: 11.8
6 cuDNN是否启用: True5. 多环境安装
由于不同的深度学习项目通常都会依赖不同的PyTorch版本。作为示例,我们下面再来安装一个基于Python 3.8版本、PyTorch版本为1.12且通过CUDA 11.3编译的环境。首先我们需要创建一个Python版本为3.8的环境,然后激活以后通过如下命令安装PyTorch:
1 (py38) root@moon:~# pip install torch==1.12.0+cu113 --index-url https://download.pytorch.org/whl/cu113安装完成后,我们同样可以通过上述脚本来进行测试,输出结果为:
1 cuda:0
2 PyTorch版本: 1.12.0+cu113
3 GPU是否可用: True
4 GPU数量: 1
5 CUDA版本: 11.3
6 cuDNN是否启用: True这样,如果我们需要使用不同PyTorch版本的深度学习环境,我们只需要切换到对应的Python虚拟环境即可。
2.2.3 实战示例#
为了让各位读者能够更加清晰地掌握PyTorch深度学习环境的安装过程,下面我们再以一个实际的开源项目为例来基于项目给出的requirements.txt文件安装好整个运行环境。同时,这个项目在10.15节内容中还会详细介绍,这里我们只是先让它能够成功运行。
1. 环境依赖
对于任何一个深度学习环境都有对应的依赖包及其相关的版本依赖关系。在Python环境中,通常我们会将一个项目所依赖的包名和版本导出到一个固定的文件中,以便让其他使用的人能够根据这个文件重新安装对应的环境。在进入待导出的Python虚拟环境以后,我们可以通过如下命令来导出:
pip freeze > requirements.txt执行完上述命令后,在当前目录想将会生成一个名为requirements.txt的文件,内容形式如下所示:
aiohttp==3.9.1
aiosignal==1.3.1
async-timeout==4.0.3
attrs==23.2.0
cachetools==5.3.2这些需要注意的是,requirements.txt只是一个约定俗成的名字,可以是其它任意名称。
2. 安装环境
我们在服务器上克隆得到该项目 [5],并把模型文件pytorch_model.bin放到model目录中。然后我们建立一个基于Python 3.8版本的虚拟环境,命令如下所示:
conda create -n gpt2 python=3.8之后激活虚拟环境gpt2,然后安装PyTorch框架。根据项目根目录提供的requirements.txt文件来看,该项目需要安装的PyTorch版本为torch==1.12.0+cu113。从名字还可以看出,它是基于CUDA 11.3平台编译而来的。进一步,我们可以通过如下命令来安装整个环境:
(gpt2) root@moon:~# pip install -r requirements.txt --extra-index-url https://download.pytorch.org/whl/cu113上述命令的含义是,使用pip设定的源自动安装requirements.txt中的每一个依赖包,且同时使用https://download.pytorch.org/whl/cu113 地址中的torch包来安装PyTorch框架。最后,安装成功后将会看到类似如下输出信息:
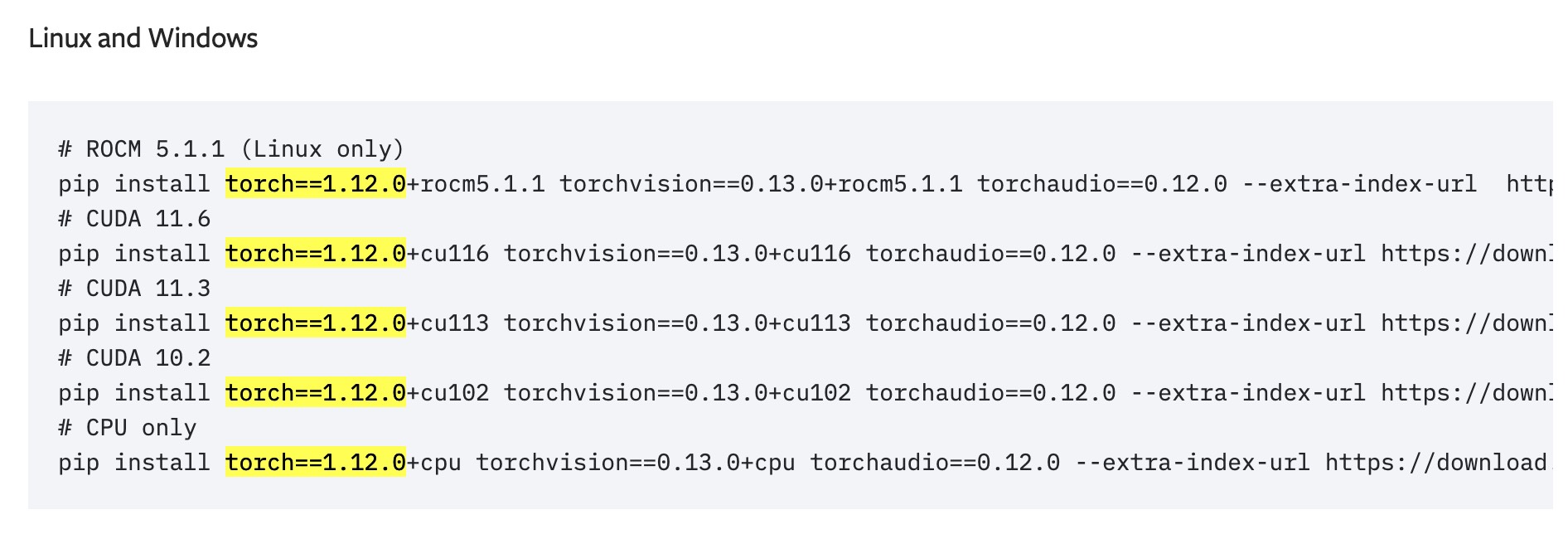
Successfully installed Markdown-3.5.2 PyYAML-6.0.1 Werkzeug-3.0.1 absl-py-2.0.0 aiohttp-3.9.1 aiosignal-1.3.1 async-timeout-4.0.3 attrs-23.2.0 cachetools-5.3.2 certifi-2023.11.17 charset-normalizer-3.3.2 click-8.1.7 filelock-3.13.1 frozenlist-1.4.1 fsspec-2023.12.2 future-0.18.3 google-auth-2.26.2 google-auth-oauthlib-1.0.0 grpcio-1.60.0 huggingface-hub-0.20.2 idna-3.6 importlib-metadata-7.0.1 joblib-1.3.2 multidict-6.0.4 numpy-1.24.4 oauthlib-3.2.2 packaging-23.2 protobuf-4.25.2 pyasn1-0.5.1 pyasn1-modules-0.3.0 pytorch-lightning-1.2.2 regex-2023.12.25 requests-2.31.0 requests-oauthlib-1.3.1 rsa-4.9 sacremoses-0.1.1 six-1.16.0 tensorboard-2.14.0 tensorboard-data-server-0.7.2 tokenizers-0.12.1 torch-1.12.0+cu113 tqdm-4.66.1 transformers-4.18.0 urllib3-2.1.0 yarl-1.9.4 zipp-3.17.0这里需要注意的是,如果requirements.txt文件中的torch版本没有CUDA的版本信息,我们可以去网 [4] 中检索torch版本号,便可以看到对应支持的CUDA平台。例如对于torch==1.12来说,我们可以查询到CUDA11.3是其中的一个编译平台,如图2-24所示。所以链接 https://download.pytorch.org/whl/ 后再拼接上cu113即可。同样,torch==1.12版本还支持cu102和cu116平台编译的版本。
3. 代码运行
在整个环境安装结束以后,我们进入到项目根目录,运行generate.py文件即可进行模型推理,示例代码如下所示:
(gpt2) root@moon:~/GPT2-Chinese# python generate.py 上述代码运行结束后,便会输出类似如下结果:
Namespace(batch_size=1, device='0', fast_pattern=False, length=512, model_config='model/config.json', model_path='model/pytorch_model.bin', n_ctx=1024, no_wordpiece=False, nsamples=10, prefix='先帝创业未半而中道崩殂', repetition_penalty=1.0, save_samples=False, save_samples_path='.', segment=False, temperature=1, tokenizer_path='model/vocab.txt', topk=8, topp=0)
57%|███████████████████████▍ | 293/512 [00:04<00:03, 63.98it/s]
[CLS] 先 帝 创 业 未 半 而 中 道 崩 殂 , 天 下 之 人 痛 悼 流 涕 , 故 以 其 所 居 之 宫 而 奉 之 。 及 其 即 位 , 复 奉 居 于 此 , 其 所 居 宫 , 犹 如 旧 制 。 至 其 子 孙 有 以 其 父 之 丧 而 居 于 此 者 , 则 又 如 旧 制 矣 。 然 其 居 之 者 又 皆 不 过 如 故 事 。 [SEP] 之 于 宫 , 则 不 能 不 为 之 起 居 于 此 也 ; 之 于 宫 , 则 亦 不 能 不 为 之 起 居 于 此 也 。 今 日 之 宫 , 则 又 非 所 谓 居 于 宫 者 矣 , 而 况 其 子 孙 乎 ? [SEP] 之 于 宫 之 为 言 则 不 可 以 不 正 矣 。 故 不 可 曰 宫 , 亦 不 可 曰 宫 , 而 况 其 子 孙 乎 ? [SEP] 子 孙 以 为 子 孙 而 居 于 宫 , 则 非 其 子 孙 而 何 也 ? 是 故 其 居 也 , 则 必 使 居 于 其 宫 ; 其 居 也 , 则 必 使 居 于 其 宫 ; 其 居 也 , 又 必 使 居 于 其 宫 。 不 然 , 则 又 何 为 其 不 正 其 居 之 宫 也 ? 不 然 , 则 不 正 其 居 之 宫 之 宫 也 ......4. 本书项目环境
本书所有的算法内容均提供有完整的示例代码,对于项目中所涉及的数据文件的下载地址可参见项目工程data目录下的README.md说明文件。同时,对于整个工程中的代码来说,各位读者可以创建一个Python版本为3.9的虚拟环境,然后根据提供的requirements_py39.txt文件通过如下命令完成环境的安装:
pip install -r requirements_py39.txt --extra-index-url https://download.pytorch.org/whl/cu118经过我们测试,上述环境可以正常运行第9章及之前所有章节中的示例代码。除此以外,如果工程目录中还提供了额外的requirements.txt,各位读者需自行再按照步骤创建一个新的Python虚拟环境并完成相关依赖包的安装。例如本小节一开始介绍到的GPT2-Chinese项目。
2.2.4 GPU租用#
在学习使用过程中,如果没有或者需要使用更多的GPU设备,那我们还可以租赁的方式来实现。通常,我们可以在阿里云或者腾讯云上租用相关的GPU服务器来训练模型,但此时需要我们自行去安装配置深度学习环境。还有一种方式就是直接租用市面上的GPU算力服务提供商所提供的深度学习平台,例如常见的有AutoDL、矩池云和银汉云等等。在这些平台上,我们可以根据自己的实际需要来选择对应GPU的型号、数量、环境中Python的版本、PyTorch的版本、是否使用集群等等,购买完成后整个深度学习环境就自动完成了安装,我们直接使用即可。各位读者可以根据自己实际的需要和预算选择相应的平台提供商。
2.2.5 小结#
在本节内容中,我们首先介绍了Windows环境下的Conda和Python虚拟环境的安装过程,以及如何安装CPU版本的PyTorch框架;然后详细介绍了Linux系统Ubuntu发行版中CUDA Toolkit工具的安装、Conda和Python虚拟环境的安装以及GPU环境下不同版本PyTorch框架的安装过程;最后以一个实际的项目为例,再次介绍了PyTorch环境的安装过程。
引用#
[1] https://docs.conda.io/projects/miniconda/en/latest
[2] https://developer.nvidia.com/cuda-toolkit-archive
[3] https://pytorch.org/get-started/previous-versions