7.4 GRU网络#
在上一节内容中,我们详细介绍了LSTM模型的相关原理,其动机主要是为了解决RNN模型中的长期依赖以及梯度消失或爆炸的问题。在接下来的这篇文章中我们将继续介绍另外一个同样是为了解决上述两个问题的基于门控循环单元(Gated Recurrent Unit, GRU)的时序模型[1]。
7.4.1 GRU动机#
如同LSTM一样,GRU提出的动机同样是为了解决传统RNN的长距离依赖等问题。同时,受到LSTM中门控机制的启发曹庆贤等人在2014年也提出了一种基于门控循环单元的循环结构。与LSTM相比,GRU通过精简LSTM中输入门和输出门减少了模型的参数量从而使得计算速度更快,并同时使用了更新门和重置门来控制信息的流动。GRU既解决了LSTM中的复杂性和计算成本问题,同时又保留了LSTM在处理长序列数据时对梯度消失问题的有效应对,是一种更加简化和高效的RNN变体。
7.4.2 GRU结构#
经过7.3节对LSTM模型的介绍,GRU模型理解起来就十分容易了。在LSTM门中,每个记忆单元通过3个不同的门控结构来对输入当前时刻的信息进行筛选,而在GRU模型中则是将其精简到了两个门控结构,并通过一种巧妙的方式实现了对历史信息和当前信息的互补结合。如图7-10所示便是GRU模型的结构示意图。
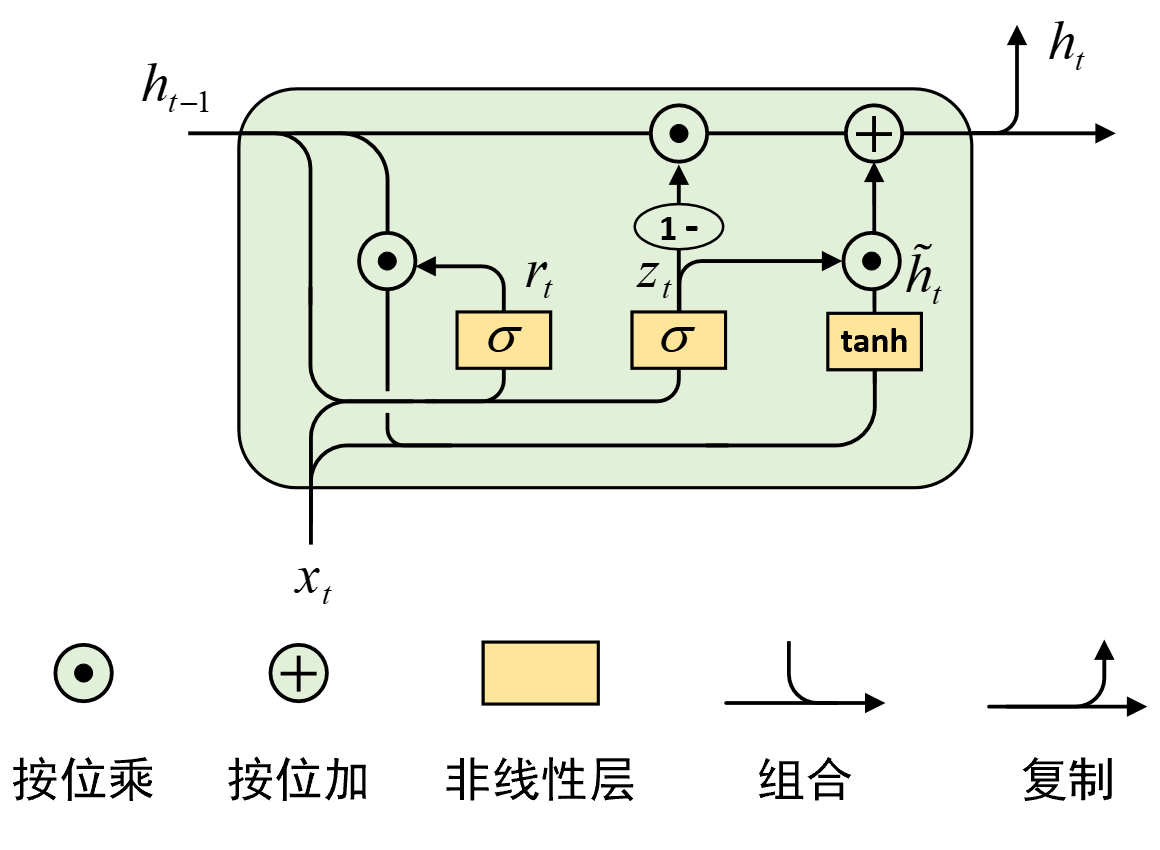
从图7-10可以一眼看出GRU中去掉了LSTM中存在的隐含状态,转而只留下了直接贯穿所有时刻的记忆状态。在GRU中,首先是根据当前时刻的输入$x_t$和历史记忆状态$h_{t-1}$计算得到重置门$r_t$,并用于后续对历史记忆状态进行筛选,其具体计算过程为
$$ r_t=\sigma([h_{t-1},x_t]W_r) \tag{7-14} $$其中$\sigma$为Sigmoid函数,$[a,b]$示将$a,b$两个向量进行堆叠组合,$x_t$的形状为[batch_size,input_size],$h_{t-1}$的形状为[batch_size,hidden_size],$[h_{t-1},x_t]$的形状为[batch_size,input_size+hidden_size],$W_r$的形状为[input_size+hidden_size,hidden_size]。
接着,同样根据当前时刻的输入$x_t$和历史记忆状态$h_{t-1}$计算得到更新门$z_t$。可以看出,此时更新门的输出结果将同时作用于对历史信息和当前时刻信息的筛选,只是两者为互补关系,即$z_t$将直接作用于输出$\tilde{h}_t$,而$1-z_t$作用于历史记忆状态$h_{t-1}$。这样的设计也十分巧妙,一部占比分来自于历史状态,而另一部分占比则来自于当前状态,但总的信息占比量固定为1。当然,这里我们还可以把$z_t$看做是输出门,而$1-z_t$看作是遗忘门,详见第7.4.4节内容。进一步,更新门的具体计算过程为
$$ z_t=\sigma([h_{t-1},x_t]W_z) \tag{7-15} $$
其中$W_z$的形状为[input_size+hidden_size,hidden_size]。
最后,当前时刻的输入同经过重置门处理后的历史记忆状态组合,经过一个$\text{tanh}$非线性层后便得到了当前时刻的新输入信息;进一步再将更新门作用后的两个结果相加便得到了当前时刻GRU的输出$h_t$,其具体计算过程为
$$ \begin{aligned} \tilde{h}_t=\tanh([r_t\odot h_{t-1},x_t]W)\\[2ex] h_t=z_t\odot\tilde{h}_t+(1-z_t)\odot h_{t-1} \end{aligned}\tag{7-16} $$
其中$W$的形状为[input_size+hidden_size,hidden_size],$h_t$的形状为[batch_size,hidden_size]。
7.4.3 GRU实现#
在清楚GRU模型的相关原理之后,我们再来看如何借助PyTorch快速实现GRU模型,示例代码如下所示:
1 def test_GRU():
2 batch_size, time_step = 2, 3
3 input_size, hidden_size = 4, 5
4 x = torch.rand([batch_size, time_step, input_size])
5 gru = nn.GRU(input_size, hidden_size, num_layers=2, batch_first=True)
6 output, hn = gru(x)
7 print(output)
8 print(hn)从上述代码可以看出,PyTorch中GRU的使用方式和7.1.6节中介绍的RNN的使用方式一致,因此这里我们就不再赘述。以上完整示例代码可以参见Code/Chapter07/C05_GRU/main.py内容。
7.4.4 GRU与LSTM对比#
在介绍完GRU的相关原理及在PyTorch中的使用方法以后,我们再来将其与LSTM模型对比一下,看看两者有何异同之处。为了更好地从直观上来将两者进行对比,我们将图7-10中的结构换了一种绘制方式,如图7-11所示。
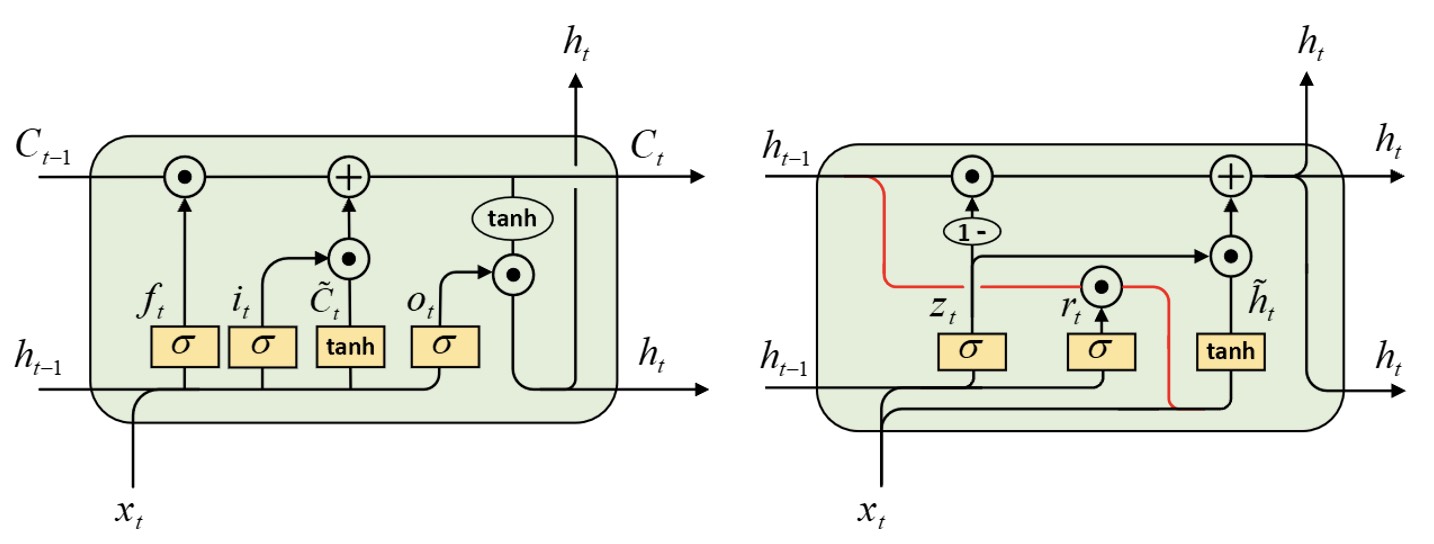
如图7-11所示,左侧为LSTM的网络结构图,右侧则为重新绘制的GRU网络结构图,各位读者可以先对比其与图7-10的差别,然后再回过头来看这里的内容。首先,在LSTM中记忆状态$C_t$经非线性变换$\text{tanh}$作用后,再经过输出门作用后便得到当前时刻的输出$h_t$;而在GRU中,融入新信息后的记忆状态就直接作为了当前时刻的输出$h_t$。因此在LSTM中输出$h_t$可以看成是对记忆状态$C_t$的再次筛选,而在GRU中去掉了这一步。其次,虽然在LSTM和GRU中遗忘门(GRU中的$1-z_t$)都是通过第$t-1$时刻的输出$h_{t-1}$与当前时刻的输入$x_t$训练得到,但是不同点在于LSTM