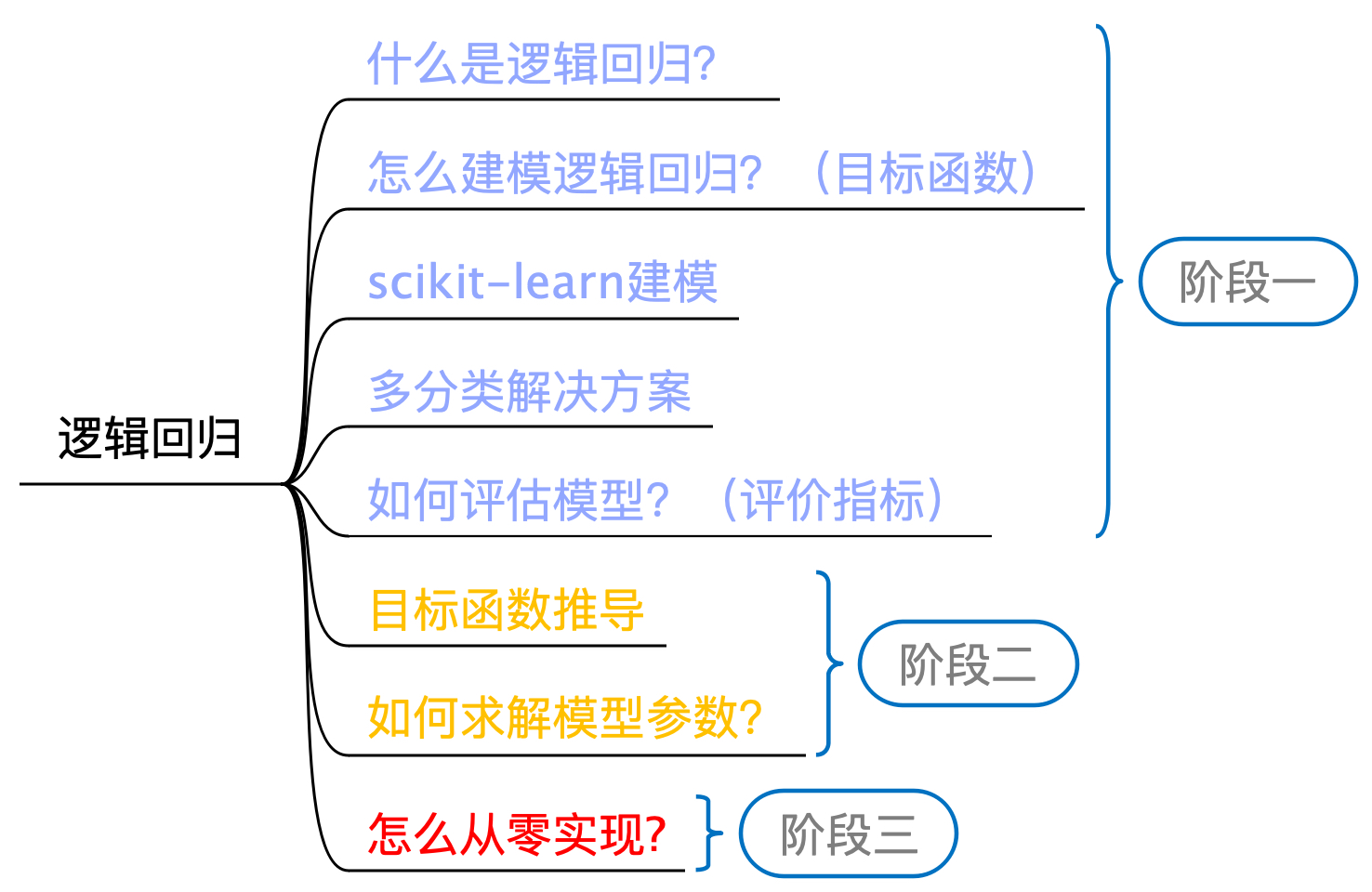
在第2章中,我们详细地介绍了线性回归模型,从本章开始将继续介绍下一个经典的机器学习算法——逻辑回归(Logistic Regression)。如图3-1所示,此图为逻辑回归模型学习的大致路线,其同样也分为3个阶段。在第1个阶段结束后,我们也就大致掌握了逻辑回归的基本原理。下面就开始正式进入逻辑回归模型的学习。
3.1 模型的建立与求解#
3.1.1 理解逻辑回归模型#
通常来讲,一个新算法的诞生要么用来改善已有的算法模型,要么就是首次提出用来解决一个新的问题,而逻辑回归模型恰恰属于后者,它是用来解决一类新的问题——分类(Classification)。什么是分类问题呢?
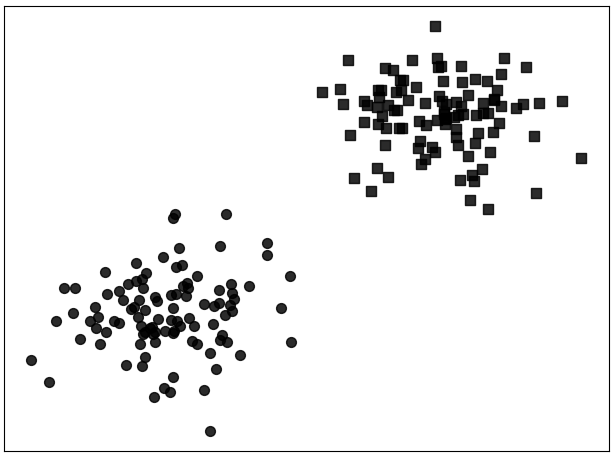
现在有两堆样本点,需要建立一个模型来对新输入的样本进行预测,判断其应该属于哪个类别,即二分类问题(Binary Classification),如图3-2所示。对于这个问题的描述用线性回归来解决肯定是不行的,因为两者本就属于不同类型的问题。退一步讲,即使用线性回归来建模得到的估计也就是一条向右倾斜的直线,而我们这里需要的却是一条向左倾斜的且位于两堆样本点之间的直线。同时,回归模型的预测值都位于预测曲线附近,而无法做到区分直线两边的东西。既然用已有的线性回归解决不了,那么我们可不可以在此基础上做一点改进以实现分类的目的呢?答案是当然可以。
3.1.2 建立逻辑回归模型#
既然是解决分类问题,那么完全可以通过建立一个模型用来预测每个样本点$(x_1,y_2)$属于其中一个类别的概率$p$,如果$p>0.5$,我们就可以认为该样本点属于这个类别,这样就能解决上述的二分类问题了。该怎样建立这个模型呢?
在前面的线性回归中,通过建模$h(x)=wx+b$来对新样本进行预测,其输出值为可能的任意实数,但此处既然要得到一个样本所属类别的概率,那最直接的办法就是通过一个函数$g(z$),将$x_1$和$x_2$这两个特征的线性组合映射至[0,1]的范围即可。由此,便得到了逻辑回归中的预测模型
$$ \hat{y}=h(x)=g(w_1x_1+w_2x_2+b)\tag{3-1} $$其中,$w_1$、$w_2$和$b$为未知参数; $h(x)$称为假设函数(Hypothesis)。当$h(x)$大于某个值(通常设为0.5)时,便可以认为样本$x$属于正类,反之则认为属于负类。同时,也将$w_1x_1+w_2x_2+b=0$称为两个类别间的决策边界(Decision Boundary)。当求解得到$w_1$、$w_2$和$b$后,也就意味着得到了这个分类模型。
当然,如果该数据集有$n$个特征维度,那么同样只需要将所有特征的线性组合映射至区间[0,1]即可
$$ \hat{y}=h(x)=g({{w}_{1}}{{x}_{1}}+{{w}_{2}}{{x}_{2}}+\cdots +{{w}_{n}}{{x}_{n}}+b)\tag{3-2} $$注意: 回归模型一般来讲是指对连续值进行预测的一类模型,而分类模型则是指对离散值(类标)预测的一类模型,但是由于历史的原因虽然逻辑回归被称为回归,但它却是一个分类模型,这算是一个例外。
3.1.3 求解逻辑回归模型#
当建立好模型之后就需要找到一种方法来求解模型中的未知参数。同线性回归一样,此时也需要通过一种间接的方式,即通过目标函数来刻画预测标签(Label)与真实标签之间的差距。当最小化目标函数后,便可以得到需要求解的参数$w$和b。
同样,我们先给出逻辑回归中的目标函数(第二阶段再讲解来历):
$$ \begin{aligned} & J(w,b)=-\frac{1}{m}\left[ \sum\limits_{i=1}^{m}{{{y}^{(i)}}}\log h({{x}^{(i)}})+(1-{{y}^{(i)}})\log (1-h({{x}^{(i)}})) \right] \\[2ex] & h({{x}^{(i)}})=g(w{{x}^{(i)}}+b) \end{aligned}\tag{3-3} $$其中,$m$表示样本总数,$x^{(i)}$表示第$i$个样本,$y^{(i)}$表示第$i$个样本的真实标签,取值为0或1,$h(x^{(i)})$表示第$i$个样本为正类的预测概率。
由式(3-3)可以知道,当函数$J(w,b)$取得最小值的参数$\hat{w}$和$\hat{b}$,也就是我们要求的目标参数。原因在于,当$J(w,b)$取得最小值时就意味着此时所有样本的预测标签与真实标签之间的差距最小,这同时也是最小化目标函数的意义,因此,对于如何求解模型$h(x)$的问题就转化为如何最小化目标函数$J(w,b)$的问题。
至此,对逻辑回归算法第1阶段核心内容的学习也就只差一步之遥了,也就是评价指标及通过开源的框架来建模并进行预测。
3.1.4 逻辑回归示例代码#
首先,为了便于后续的可视化过程及了解分类的实质,我们这里首先采用人为的方式来构造一个数据集并以此进行模型的训练,然后通过sklearn中的LogisticRegression来完成模型的求解。完整代码见 AllBookCode/Chapter03/C02_decision_boundary.py 文件。
1. 构造数据集
这里需要用到sklearn中的make_blobs()方法来构造数据集,代码如下:
1 from sklearn.datasets import make_blobs
2 def make_data():
3 centers = [[1, 1], [2, 2]] # 指定中心
4 x, y = make_blobs(n_samples=200, centers=centers,
5 cluster_std=0.2, random_state=np.random.seed(10))
6 index_pos, index_neg = (y == 1), (y == 0)
7 x_pos, x_neg = x[index_pos], x[index_neg]
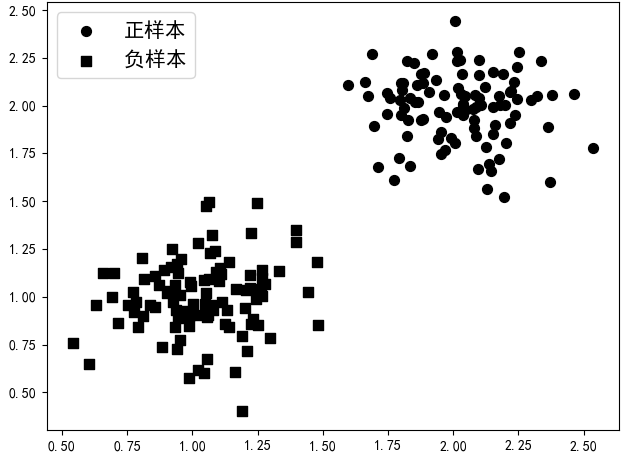
8 return x, y在上述代码中,第2行用来指定生成两个样本堆的中心,第3~4行则是根据指定的中心点生成两个不同类别的样本堆,其中n_samples表示样本的数量,cluster_std表示样本间的标准差(值越小,样本点分布就越集中),random_state表示用来指定一个固定的随机种子,以使每次产生相同的样本点。
在这之后,就能生成一个数据集了,如图3-3所示。
2. 训练模型
接着通过LogisticRegression来完成模型的训练和预测,代码如下:
1 from sklearn.linear_model import LogisticRegression
2 def decision_boundary(x, y):
3 model = LogisticRegression()
4 model.fit(x, y)
5 pred = model.predict([[1, 0.5], [3, 1.5]])
6 print("样本点(1,0.5)所属的类标为{}\n"
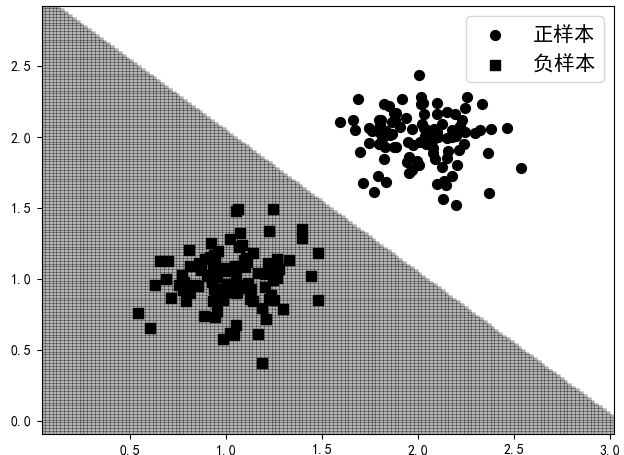
7 "样本点(3,1.5)所属的类标为{}".format(pred[0], pred[1]))在完成模型的训练之后,便可以绘制出模型训练得到的决策面,用于样本点的分类,如图3-4所示。
3.1.5 小结#
在本节中,我们首先通过一个例子引入了什么是分类,然后介绍了为什么不能用线性回归模型进行建模的原因。其次,通过对线性回归的改进得到逻辑回归模型,并直接地给出了逻辑回归模型的目标函数。最后通过开源的sklearn框架搭建了一个简单的逻辑回归模型,并对决策面进行了可视化。虽然内容不多,也不复杂但却包含了逻辑回归算法的核心思想。同时,余下的内容也会在后续的章节中进行介绍。