2.7 目标函数推导#
经过前面几节内容的介绍,我们知道了什么是线性回归、怎样转换求解问题、如何通过sklearn进行建模求解及梯度下降法的原理与推导。同时,在2.6节中还通过一个故事来讲解了最小二乘法的来历,以及误差服从高斯分布的事实。下面,我们就来完成线性回归中的最后两个任务,线性回归的推导及Python代码的实现。
2.7.1 目标函数#
根据前面的介绍,现在我们对线性回归的目标函数做如下定义: 设样本为$(x^{(i)},y^{(i)})$,对样本的观测(预测)值记为${{\hat{y}}^{(i)}}={{W}^{T}}{{x}^{(i)}}+b$,则有
$$ {{y}^{(i)}}={{\hat{y}}^{(i)}}+{{e}^{(i)}}\tag{2-23} $$其中$e^{(i)}$表示第$i$个样本预测值与真实值之间的误差,$W$和$x^{(i)}$均为一个列向量,$b$为一个标量,同时由于误差$e^{(i)}$独立同分布于均值为0的高斯分布[3],于是有
$$ f({{e}^{(i)}})=\frac{1}{\sqrt{2\pi }\sigma }\exp \left( -\frac{{{({{e}^{(i)}}-0)}^{2}}}{2{{\sigma }^{2}}} \right)\tag{2-24} $$接着将式(2-23)代入式(2-24)有
$$ f({{e}^{(i)}})=\frac{1}{\sqrt{2\pi }\sigma }\exp \left( -\frac{{{({{y}^{(i)}}-{{{\hat{y}}}^{(i)}})}^{2}}}{2{{\sigma }^{2}}} \right)\tag{2-25} $$此时需要注意式(2-25)的右边部分(从右往左看),站在$y^{(i)}$的角度看显然是随机变量$y^{(i)}$服从于以$\hat{y}^{(i)}$为均值的正态分布[4] 。又由于此时的密度函数与参数$W$、$b$和$x^{(i)}$有关(随机变量$y^{(i)}$是$x^{(i)}$、$W$和$b$下的条件分布),于是有
$$ p({{y}^{(i)}}|{{x}^{(i)}};W,b)=\frac{1}{\sqrt{2\pi }\sigma }\exp \left( -\frac{{{({{y}^{(i)}}-{{{\hat{y}}}^{(i)}})}^{2}}}{2{{\sigma }^{2}}} \right)\tag{2-26} $$到目前为止,也就是说此时真实值$y^{(i)}$服从于均值为$\hat{y}^{(i)}$,方差为$\sigma^2$的正态分布。同时,由于$y^{(i)}$是依赖于参数$W$和$b$的变量,那么什么样的一组参数$W$和$b$能够使已知的真实值最容易发生呢?此时就需要用到极大似然估计进行参数估计
$$ L(\theta )=\prod\limits_{i=1}^{m}{p}({{y}^{(i)}}|{{x}^{(i)}};W,b)=\prod\limits_{i=1}^{m}{\frac{1}{\sqrt{2\pi }\sigma }}\exp \left( -\frac{{{({{y}^{(i)}}-{{{\hat{y}}}^{(i)}})}^{2}}}{2{{\sigma }^{2}}} \right)\tag{2-27} $$为了便于求解,可以在等式(2-27)的两边同时取自然对数
$$ \begin{aligned} & \log L(W,b)=\log \left\{\prod\limits_{i=1}^{m}{\frac{1}{\sqrt{2\pi }\sigma }}\exp \left( -\frac{{{(y^{(i)}-{\hat{y}}^{(i)})}^{2}}}{2{{\sigma }^{2}}} \right) \right\} \\[2ex] & =\sum\limits_{i=1}^{m}{\log }\left\{ \frac{1}{\sqrt{2\pi }\sigma }\exp \left( -\frac{{{({{y}^{(i)}}-{{{\hat{y}}}^{(i)}})}^{2}}}{2{{\sigma }^{2}}} \right) \right\} \\[2ex] & =\sum\limits_{i=1}^{m}{\left\{ \log \frac{1}{\sqrt{2\pi }\sigma }-\frac{{{({{y}^{(i)}}-{{{\hat{y}}}^{(i)}})}^{2}}}{2{{\sigma }^{2}}} \right\}} \\[2ex] & =m\cdot \log \frac{1}{\sqrt{2\pi }\sigma }-\frac{1}{{{\sigma }^{2}}}\frac{1}{2}\sum\limits_{i=1}^{m}{{{\left( {{y}^{(i)}}-{{{\hat{y}}}^{(i)}} \right)}^{2}}} \end{aligned}\tag{2-28} $$由于$\max L(W,b)$ 等价于$\max\log L(W,b)$,所以
$$ \begin{aligned} & \max \log L(W,b)\Leftrightarrow \min \frac{1}{{{\sigma }^{2}}}\frac{1}{2}\sum\limits_{i=1}^{m}{{{\left( {{y}^{(i)}}-{{{\hat{y}}}^{(i)}} \right)}^{2}}} \\[2ex] & \Leftrightarrow \min \frac{1}{2}\sum\limits_{i=1}^{m}{{{\left( {{y}^{(i)}}-{{{\hat{y}}}^{(i)}} \right)}^{2}}} \end{aligned}\tag{2-29} $$于是得到目标函数
$$ J(W,b)=\frac{1}{2m}\sum\limits_{i=1}^{m}{{{\left( {{y}^{(i)}}-{{{\hat{y}}}^{(i)}} \right)}^{2}}}\tag{2-30} $$2.7.2 求解梯度#
设$y^{(i)}$表示第$i$个样本的真实值; $\hat{y}^{(i)}$表示第$i$个样本的预测值;$W$表示权重(列)向量,$W_j$表示其中的一个分量;$X$表示数据集,形状为$m\times n$,$m$为样本个数,$n$为特征维度; $x^{(i)}$为一个(列)向量,表示第$i$个样本,$x^{(i)}_j$为第$j$维特征。
由此可以写出目标函数为
$$ J(W,b)=\frac{1}{2m}\sum\limits_{i=1}^{m}{{{\left( {{y}^{(i)}}-{{{\hat{y}}}^{(i)}} \right)}^{2}}}=\frac{1}{2m}\sum\limits_{i=1}^{m}{{{\left( {{y}^{(i)}}-({{W}^{T}}{{x}^{(i)}}+b) \right)}^{2}}}\tag{2-31} $$目标函数关于$W_j$的梯度求解过程为
$$ \begin{aligned} & \frac{\partial J}{\partial W_{j}}=\frac{\partial }{\partial W_{j}}\frac{1}{2m}\sum\limits_{i=1}^{m}\left( y^{(i)}-(W_{1}x_{1}^{(i)}+W_{2}x_{2}^{(i)}\cdots W_{n}x_{n}^{(i)}+b) \right)^{2} \\[2ex] & =\frac{1}{m}\sum\limits_{i=1}^{m}{\left( y^{(i)}-(W_{1}x_{1}^{(i)}+W_{2}x_{2}^{(i)}\cdots W_{n}x_{n}^{(i)}+b) \right)}\cdot (-x_{j}^{(i)}) \\[2ex] & =\frac{1}{m}\sum\limits_{i=1}^{m}{\left( y^{(i)}-(W^{T}x^{(i)}+b) \right)}\cdot (-x_{j}^{(i)}) \end{aligned}\tag{2-32} $$目标函数关于$b$的梯度求解过程为
$$ \begin{aligned} & \frac{\partial J}{\partial b}=\frac{\partial }{\partial b}\frac{1}{2m}\sum\limits_{i=1}^{m}{{{\left( {{y}^{(i)}}-({{W}^{T}}{{x}^{(i)}}+b) \right)}^{2}}} \\[2ex] & =-\frac{1}{m}\sum\limits_{i=1}^{m}{\left( {{y}^{(i)}}-({{W}^{T}}{{x}^{(i)}}+b) \right)} \end{aligned}\tag{2-33} $$此时便得到了目标函数关于参数的梯度计算公式
$$ J(W,b)=\frac{1}{2m}\sum\limits_{i=1}^{m}{{{\left( {{y}^{(i)}}-({{W}^{T}}{{x}^{(i)}}+b) \right)}^{2}}} \tag{2-34} $$$$ \frac{\partial J}{\partial {{W}_{j}}}=\frac{1}{m}\sum\limits_{i=1}^{m}{\left( {{y}^{(i)}}-({{W}^{T}}{{x}^{(i)}}+b) \right)}\cdot (-x_{j}^{(i)}) \tag{2-35} $$$$ \frac{\partial J}{\partial b}=-\frac{1}{m}\sum\limits_{i=1}^{m}{\left( {{y}^{(i)}}-({{W}^{T}}{{x}^{(i)}}+b) \right)}\tag{2-36} $$在推导得到每个参数的梯度更新公式后,就能根据梯度下降算法来对迭代的对参数值进行更新,直到目标函数收敛。到此,对于整个线性回归部分阶段二的内容就介绍完了,下面继续来看最后一个阶段的内容。
2.7.3 矢量化计算#
为了在编程时高效地计算,需要对式(2-34)~式(2-36)进行矢量化,代码如下:
1 y_hat=np.matmul(X, W) + b
2 J(W,b)= 0.5 * (1 / m) * np.sum((y – y_hat) ** 2)
3 grad_w=-1/m*np.matmul(X.T,(y-y_hat))
4 grad_b=-1/m*np.sum(y-y_hat)同时,这里有一个小技巧值得分享。当我们在矢量化公式时,如果不知道哪个变量该放在哪个位置或者要不要进行转置,则可带上变量的维度一起进行计算。例如根据式(2-34)~式(2-36)可以看出$W_j$的梯度计算公式大致的格式,所以矢量化后的结果也差不多是那种格式。同时$W$的形状是[$n,1$],而真实值减去预测值后的形状为[$m,1$],因此在和$X$计算后为了得到$W$的形状,只能是一个[$n,m$]的矩阵乘以[$m,1$]的矩阵才可能得到那样的结果。故,应该把$X$的转置放在前面。
2.7.4 从零实现线性回归#
下面我们依旧以波士顿房价预测模型为例,通过手动编写代码进行模型的建模与求解,完整代码见 AllBookCode/Chapter02/C10_boston_price_train.py 文件。
1. 定义预测函数
首先需要定义一个预测函数,也就是2.2节内容中所介绍的$y={{w}_{1}}{{x}_{1}}+{{w}_{2}}{{x}_{2}}\cdots {{w}_{n}}{{x}_{n}}+b$。为了同时对输入的所有样本进行计算,一般以两个矩阵相乘的方式进行,代码如下:
1 def prediction(X, W, bias):#预测
2 return np.matmul(X, W) + bias # [m,n] @ [n,1] = [m,1]2. 定义目标函数
为了方便在训练结束后(或者训练时)观察目标函数的收敛情况,所以通常会计算每一次参数更新后的损失值,代码如下:
1 def cost_function(X, y, W, bias): # 代价函数
2 m, n = X.shape
3 y_hat = prediction(X, W, bias)
4 return 0.5 * (1 / m) * np.sum((y - y_hat) ** 2)3. 定义梯度下降
在这里,需要完成模型训练时的核心部分,也就是整个梯度下降的过程,代码如下:
1 def gradient_descent(X, y, W, bias, alpha):
2 m, n = X.shape
3 y_hat = prediction(X, W, bias)
4 grad_w = -(1 / m) * np.matmul(X.T, (y - y_hat))
5 grad_b = -(1 / m) * np.sum(y - y_hat)
6 W = W - alpha * grad_w
7 bias = bias - alpha * grad_b
8 return W, bias可以看到,对于梯度的求解就是式(2-34)~式(2-36)矢量化后的形式,然后运用梯度下降算法对参数更新即可。
4. 训练模型
在定义完训练过程中所需要的相关函数后,接着就可以初始化相关权重和变量并通过梯度下降算法进行参数的更新,代码如下:
1 def train(X, y, ite=200):
2 m, n = X.shape # 506,13
3 W, b, alpha, costs = np.random.randn(n, 1),0.1,0.2
4 for i in range(ite):
5 costs.append(cost_function(X, y, W, b))
6 W, b = gradient_descent(X, y, W, b, alpha)
7 y_pre = prediction(X, W, b)
8 return costs最后,可以通过如下所示的过程来完成整个模型的训练,代码如下:
1 if __name__ == '__main__':
2 x, y = load_data()
3 train_by_sklearn(x, y)
4 costs = train(x, y)
5 #输出结果:
6 #MSE: 21.894
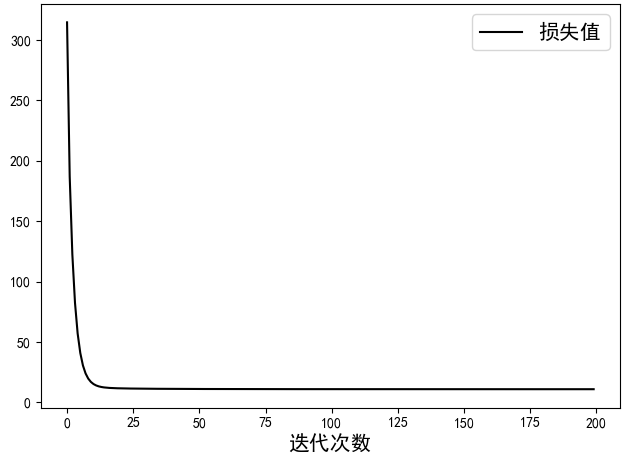
7 #MSE: 21.901同时,我们在这里也加入了通过sklearn训练后的模型的MSE评估值。可以看出,我们自己实现的模型与sklearn中的线性回归模型在MSE上几乎没有任何差别。大约在25次迭代后目标函数就开始进入收敛状态,如图2-16所示。
2.7.5 小结#
通过本节内容的学习,对于线性回归的主要内容就此结束了。对于其他细枝末节的地方(例如学习率的选择、特征标准化等),将在后续模型改善部分再进行介绍。
总结一下,如图2-17所示,在本章中我们首先介绍了线性回归模型第一阶段的主要内容,至此可以大致知道得到一个问题后应如何通过开源的sklearn库进行线性回归建模。虽然阶段一的内容并没有从数学的角度来完成对于线性回归的论证,但是其包含了学习一个算法并快速入门的路线及方法,然后我们接着介绍了梯度下降算法、误差的正态分布特性和目标函数的推导,完成了线性回归第二阶段的学习。这个阶段一般是算法从数学层面上的理论依据,尤其是统计机器学习更依赖于这个过程,但是这部分内容通常来讲有一定的难度,例如第9章SVM的求解过程。最后,我们通过本节的内容完成了线性回归模型源码的实现,也就是第三阶段的学习内容。
引用#
[1] PEDREGOSA.scikitlearn: Machine Learning in Python[J].JMLR 12,2011: 28252830.
[2] 靳志辉.数学文化.4(2013),3647.
[3] Andrew Ng,Machine Learning, Stanford University,CS229,Spring 2019.
[4] Kanade, Varun. Machine Learning – MT 2016. University of Oxford, 17 Oct. 2016.