经过前面一系列的介绍,我们已经接触了多种回归和分类算法,并且这些算法有一个共同的特点,也就是它们都是有监督的学习算法。接下来,我们将开始学习一类经典的无监督机器学习算法——聚类算法。如图11-1所示便是本章内容的学习路线图,整体包含有5种聚类算法的原理及实现过程以及聚类算法中的两类评价指标和K值的选取与分析。同时,对于每个算法的分阶段学习路线将在各小节中进行说明。
11.1 聚类算法的思想#
在正式介绍聚类之前,我们先从感性上认识一下什么是聚类。聚类算法的核心思想就是将具有相似特征的事物“聚”在一起,也就是说“聚”是一个动词。俗话说: 人以群分,物以类聚,说的就是这个道理。
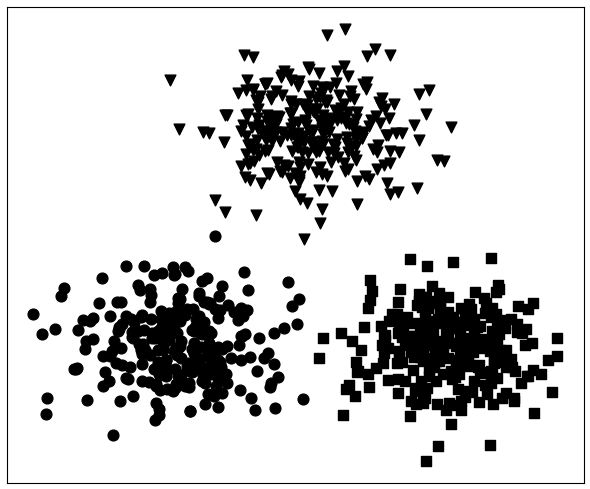
如图11-2所示,此图为3种类别的数据样本图,其中每种形状表示一个类别。聚类算法的目的就是将各个类别的样本点分开,也就是将同一种类别的样本点聚在一起。此时可能有人会问: 这不是和分类模型一样吗?刚刚接触聚类的读者难免会有这样一个疑问,即聚类和分类的区别在哪儿?聚类算法的核心思想是将具有相似特征的事物聚在一起。也就是说,聚类算法最终只能告诉我们哪些样本属于同一个类别,而不能告诉我们这些样本具体属于什么类别。因此,聚类算法在训练过程中并不需要每个样本所对应的真实标签,而分类算法却不行。
假如这里有100个样本的病例数据(包含正样本和负样本),并且通过聚类算法聚类后可以将原始数据划分成两堆,其中一堆里面有40个样本且均为一个类别,而剩下的一堆里面有60个样本且也为同一个类别,但现在这两堆究竟哪一个代表正样例,哪一个代表负样例,这是聚类算法无法告诉我们的。同时,在聚类算法中这“堆”就被称为聚类后所得到的簇(Cluster)。
同时,由于不同领域的数据样本通常存在着不同的簇结构,因此也就衍生得到了不同的聚类算法。因此,除了图11-2中这种最为常见的簇结构以外,还有图11-24和图11-31所示的簇结构,其分别对应的就是在11.10和11.11节将要介绍的基于密度和层次的聚类算法。
至此,我们相信读者已经明白了聚类算法的核心思想。那么,聚类算法是如何完成这一过程的呢?