4.3 填充和池化#
在前面两节内容中,我们分别介绍了卷积的思想与原理以及卷积操作在各类场景下的具体计算过程。在本节内容中,我们将主要围绕着卷积后形状的计算、卷积中的池化操作以及PyTorch中卷积操作的用法这三方面来进行介绍。在介绍完本节内容后,对于卷积的基础知识就算介绍完了,后面我们将开始对一些经典的卷积网络进行介绍。
4.3.1 填充操作#
在4.2节内容中,我们详细介绍了卷积操作中的卷积计算过程,可以发现原始输入在经过卷积操作之后形状都不约而同地变小了,如果我们不想在卷积之后改变特征图的大小又该怎么做呢?为了保持卷积后特征图的大小与输入时一致,通常来说可以通过填充(Padding)输入特征图的方式实现,也就是把输入的形状变大,这样卷积后的大小便可以与原始输入的特征图保持一致。
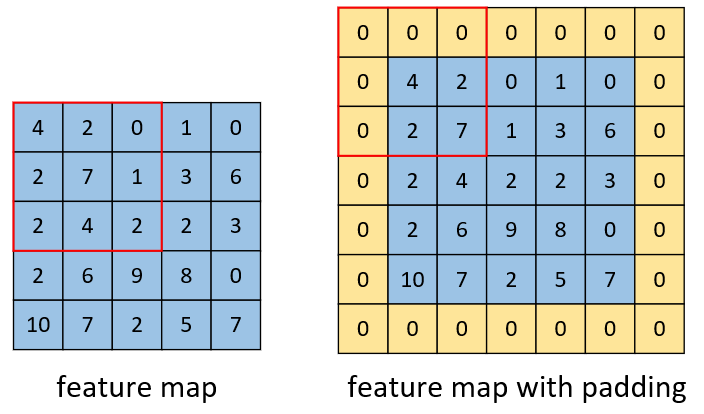
如图4-26所示,左边是形状为$[5,5]$的原始特征图 ,右边为填充后的特征图,其大小变成了$[7,7]$。对左右两边均用大小为$[3,3]$的卷积核进行卷积操作,那么卷积后左边的大小为$[3,3]$,右边的大小为$[5,5]$。可以发现,经过填充处理后便能够使得卷积后特征图的大小与输入时的大小保持一致。同时,根据图4-26可以看出,如果使用越大的卷积核进行卷积操作那么将会得到越小的输出特征图,最终则需要对原始输入填充更大的范围来保持输出特征图的大小不变。当然,如果是多通道的话,则对应在每个通道都这样填充即可。
进一步,对于卷积后特征图的形状该如何计算呢?
4.3.2 形状计算#
现在用$W$来表示输入特征图的宽度,$F$表示卷积核的宽度,$S$表示卷积核每移动一次的步长,$P$表示填充的范围(即多少圈),那么此时卷积后特征图的宽度为
$$ H=\lceil\frac{W+2P-F+1}{S}\rceil=\lfloor\frac{W+2P-F}{S}\rfloor+1\tag{4-4} $$其中$\lceil x\rceil$表示对$x$向上取整, $\lfloor x\rfloor$表示对$x$向下取整。公式(4-4)中的两种计算方法都行,记住其中一种即可。
例如,对于图4-26中的示例来说,$W=5$,$F=3$,$S=1$,$P=1$,则卷积后输出特征图的大小为
$$ H=\lceil\frac{5+2\cdot1-3+1}{1}\rceil=5\tag{4-5} $$如果有输入形状为$[32,32,3]$的特征图,卷积核的形状为$[5,5,3,64]$,步长为$S=2$,$P=2$那么卷积后的形状则为
$$ H=\lceil\frac{32+2\cdot2-5+1}{2}\rceil=16\tag{4-6} $$即$[16,16,64]$的特征图。
当然,这里有一个快速计算的技巧,如果输入$W=w$,填充范围$P=p$,卷积核的宽度$F=2p+1$,步长$S=s$,则输出$H=\lfloor\frac{w}{s}\rfloor$。
4.3.3 卷积示例代码#
在PyTorch中,我们可以借助卷积层nn.Conv2d()模块来快速完成一次卷积操作的计算过程,示例代码如下所示:
1 import torch
2 import torch.nn as nn
3 if __name__ == '__main__':
4 inputs = torch.randn([5, 3, 32, 32], dtype=torch.float32)
5 cnn_op = nn.Conv2d(in_channels=3, out_channels=10,
6 kernel_size=3, stride=1, padding=1)
7 result = cnn_op(inputs)
8 print("输入数据的形状为:", inputs.shape)
9 print("结果的形状:", result.shape) # width: 32/1在上述代码中,第4行是定义一个4维输入张量,形状为[batch_size,in_channels,high,width],其中in_channels表示输入特征图的通道数。这里需要注意的是,对于不同的深度学习框架来说类似Conv2d这样操作其接受的输入的形状可能不尽相同,例如TensorFlow中Conv2d所模型的形状便是[batch_size,high,width,in_channels],即将通道数放到了最后一个维度。第5~6行则是指定相应的参数来实例化类Conv2d,其中out_channels表示卷积核的个数,kernel_size表示卷积核的大小(也可以通过[high,width]来分别指定卷积核的高和宽),stride表示步长,padding表示填充范围。
最后上述代码运行结束后便可以得到如下所示结果:
1 输入数据的形状为: torch.Size([5, 3, 32, 32])
2 结果的形状: torch.Size([5, 10, 32, 32])根据上述输出结果可知,原始数量5、宽度为32、通道数为3的输入特征图,经过卷积操作后变成了数量5、宽度为32、通道数为10的输入特征图。
以上完整示例代码可以参见Code/Chapter04/C02_PaddingPooling/main.py文件。
4.3.4 池化操作#
池化操作对于卷积神经网络来说可以算得上是一个必不可少的步骤,几乎绝大多数卷积网络都用到了池化来提升网络模型的精度,而所谓池化可以将其看作是一个信息筛选或者过滤的操作。 池化操作可以看作是使用某一位置的相邻输出的总体统计特征来代替网络在该位置的输出。例如最大池化(Max Pooling)会给出相邻矩形区域内的最大值作为该位置的输出。除此之外还有最小池化(Min Pooling)和平均池化(Average Pooling)等。下面我们来对池化操作的具体计算步骤进行介绍。
如图4-27所示,左边为输入的特征图,右边为经过最大池化后的结果。
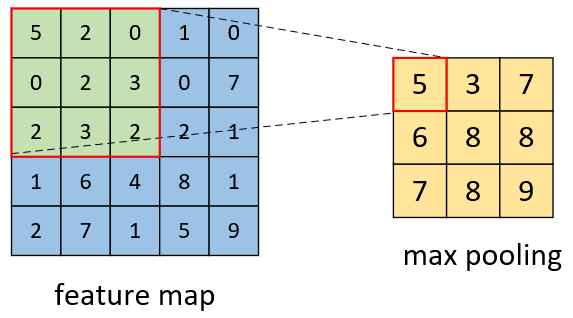
从图4-27可以看出,最大池化就是给定一个固定大小的滑动窗口,然后选择窗口中的最大值来代替整个区域作为输出,最后再依次对整个特征图进行池化操作就得到池化后的特征输出。同时可以发现,池化操作输出维度的计算同卷积操作一样,但对于池化操作来说其并没有权重参数。
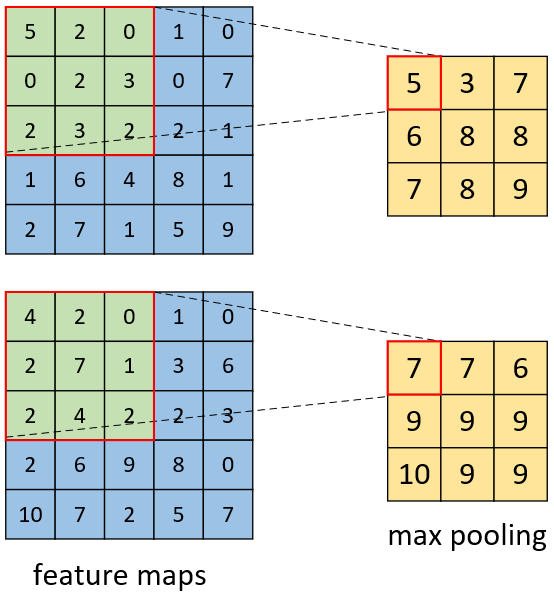
如图4-28所示为多通道的池化操作,左边为输入的特征图,右边为池化后的特征图。可以发现,所谓多通道的池化操作也 就是在每个特征通道上各自进行池化操作,它并没有改变特征的通道数(这一点不同于多通道卷积)。
同理,对于最小池化和平均池化来说,其与最大池化的不同点仅仅在于计算方式上的不同。最小池化和平均池化分别会选择滑动窗口中的最小值和平均值来代替整个区域作为输出,其它地方并没有什么不同,因此不再赘述。下面我们来看看为什么需要池化操作。
4.3.5 池化的作用#
通常来说深度学习中的每一个操作都有着其对应的作用,而池化操作的作用主要体现在两个方面:减少参数量和防止过拟合。
1. 减少参数量
由于在图像处理中输入的图片像素普遍较大,同时在采取深度卷积后也会得到多个特征通道(在有的网络中,这一数字可能是1024或者更大),因此最终得到的特征图在进行后续其它操作(例如全连接)时就会对应有大量权重参数。以输入形状为$[256,256,3]$的图片为例,在经过形状为$[5,5,3,512]$的卷积核卷积处理后,将会得到形状为$[252,252,512]$的特征图。如果后续再通过一个包含有$256$个神经元的全连接层来对其进行分类,那么此时该网络层将会有$252\times252\times512\times256\approx8\times10^{9}$个权重参数。但是,如果先对特征图进行池化处理$(F=3,S=2)$,那么这一数字就可能变成$125\times125\times512\times256\approx2\times10^{9}$,缩小了4倍。
同时值得注意的是,在实际的操作中一般会选择窗口大小为3步长为2,或者是窗口大小为2步长为2的配置进行最大池化操作[2],并且更常见是第2种配置。
2. 防止过拟合
由于在卷积网络中输入的特征图都具有较高的像素,以实现对某一类特征元素的精确刻画。但是这样一来也会带来一个弊端,即容易造成模型的过拟合现象。原因在于如果某些层的特征图分辨率很高,那么就会造成这些层的特征容错能力降低低。因此,如果只用一个像素值来表示该像素值周围的值,那么理论上便能够缓解模型过拟合现象。

如图4-29所示,左边为一张正常的图片,右边为该图片经过最大池化后的结果。可以看到,虽然右边的图片在一定程度上变得更加模糊了,但是依旧能够大致区分里面的物体。同时,这个模糊的程度取决于池化窗口的大小,窗口越大得到的结果也就会更加的模糊,当然网络最后就会呈现出欠拟合的状态。因此,可以通过调节池化窗户大小这个超参数来找到网络在过拟合与欠拟合之间的平衡点。
当然,也有学者认为完全没有必要使用池化层来进行处理,只需要使用深层的卷积操作即可[2]。因此对于到底使用还是不使用池化操作就不是一个必要选择了,不过主流的做法还是会使用池化层。
4.3.6 池化示例代码#
在PyTorch中,我们可以借助nn.MaxPool2d()模块来快速完成一次池化操作的计算过程,示例代码如下所示:
1 if __name__ == '__main__':
2 inputs = torch.randn([5, 3, 32, 32], dtype=torch.float32) # [batch_size,in_channels,high,width]
3 net = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=10,
4 kernel_size=3, stride=1, padding=1), # width: 32/1 = 32
5 nn.MaxPool2d(kernel_size=2, stride=2, ), # (32-2+1) /2 = 16
6 nn.AvgPool2d(kernel_size=2, stride=1) # (16-2+1)/1 = 15
7 )
8 result = net(inputs)
9 print("输入数据的形状为: ", inputs.shape)
10 print("池化后结果的形状:", result.shape)在上述代码中,第5行便是定义一个最大池化层,窗口大小为2,移动步长为2。第6行是定义一个平均池化层。
最终,上述代码运行结束后便会得到如下结果:
1 输入数据的形状为: torch.Size([5, 3, 32, 32])
2 池化后结果的形状: torch.Size([5, 10, 15, 15])对于上述示例来说,其输入特征的形状为[5,3,32,32]。在经过第1层卷积操作后特征图的形状为[5,10,32,32],经过最大池化后特征图的形状为[5,10,16,16],经过平均池化后最终输出结果的形状为[5,10,15,15]。
以上完整示例代码可以参见Code/Chapter04/C02_PaddingPooling/pooling.py文件。
4.3.7 小结#
在本节内容中,我们首先介绍了什么是填充操作及其作用;然后详细介绍了卷积操作之后特征图形状的计算方法;接着介绍了什么是池化操作以及为什么需要池化操作等;最后分别介绍了如何借助PyTorch框架来快速完成卷积和池化操作的计算过程。
引用#
[1] 赵申剑, 黎彧君, 符天凡, 李凯 译,深度学习 [M]. 北京:人民邮电出版社, 2017.