第 7 章 循环神经网络#
经过第3章和第4章内容的介绍,我们知道深度学习的本质可以总结为通过设计合理的网络结构来对输入进行特征提取,然后再利用提取得到的抽象特征完成后续下游任务。同时,在介绍卷积操作时我们说到,卷积的核心思想是通过共享权重来实现对在相邻空间位置上具有依赖关系的数据进行特征提取,但现实情况中还存在一类在时间维度上具有前后依赖关系的数据,我们称这样的数据为时间序列(Time Serial )数据,也叫做时序数据,如音频信号、文本序列等。因此,在本章内容中我们将介绍一种全新的网络结构——循环神经网络(Recurrent Neural Network, RNN)及其各类变体——来专门对时序数据进行特征提取。
7.1 RNN网络#
在正式介绍循环神经网络之前,我们先简单看一下RNN模型背后的思想和动机,然后再介绍它的相关原理和使用场景。
7.1.1 RNN动机#
尽管在图像处理中卷积神经网络有着广泛的应用,但是它却不适用于对时序类的数据进行特征提取,其原因在于对于时序数据来说当前时刻的状态信息往往会依赖于之前多个时刻的输出结果。例如在语言模型中,一个单词的含义往往会依赖于它前面出现的多个单词。因此我们便需要一种具备“记忆”功能的网络模型来对这类数据进行特征提取。基于这样的想法,1990年埃尔曼(Elman)等人提出了一种具有短期记忆能力网络模型循环神经网络Elman Network [1]。需要指出的是,RNN的概念是逐步发展的,很多研究者对其理论和应用做出了贡献,因此很难将其归功于某一位或几位特定的发明者,这里我们介绍的是现在最常使用的一种RNN模型结构。
7.1.2 RNN原理#
循环神经网络是深度学习中一种典型的反馈神经网络,和前馈神经网络相比较反馈神经网络之所以具有一定的记忆功能,因为反馈神经网络在不同时刻的状态是根据历史所有时刻的信息及当前时刻的输入计算而来。在 RNN 中,神经元不仅可以接受到其他神经元的输出信息,也可以接受自己的输出信息从而形成一个具有环路的网络拓扑结构,因此RNN也成为了处理序列数据的重要工具之一。
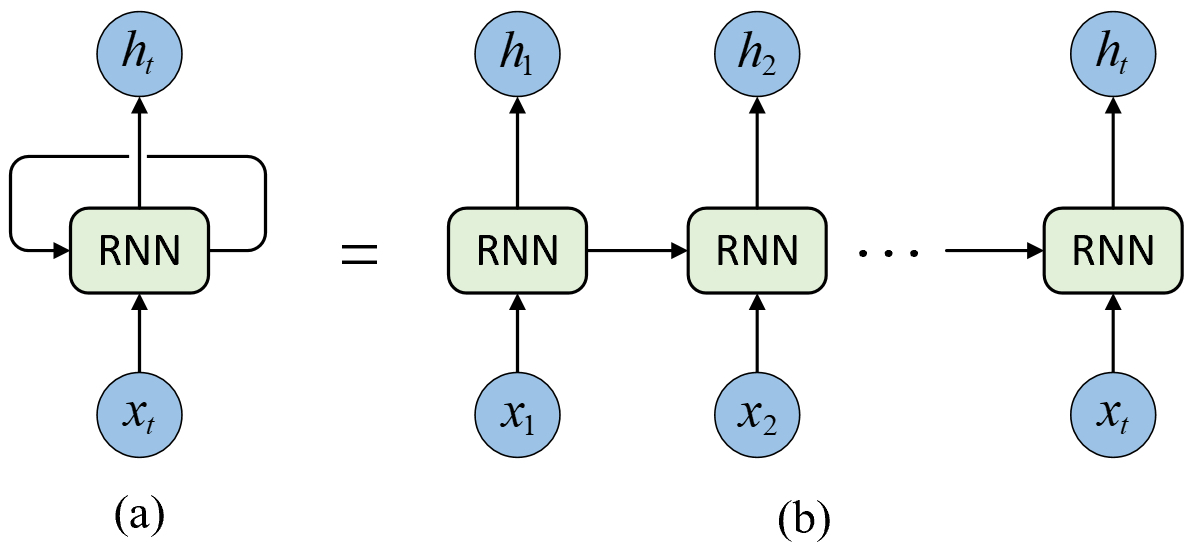
如图7-1(a)所示就是一种最基本的RNN网络结构,可以明显地看到其具有循环结构,而也恰好是这一“闭环”使得 RNN 具有了记忆功能,因为它将历史信息带入到了当前时刻的计算过程中。同时,图7-1(b)为RNN模型在时间维度展开的示意图,每一个时刻称之为一个记忆单元(Cell),其中$x_t$和$h_t$分别表示第$t$个时刻模型的输入和输出,每个时刻在计算时共享同一组模型参数。此时可以看出,第$t$时刻的输出不仅依赖于第$t$时刻的输入$x_t$同时也依赖于第$t-1$时刻的输出结果$h_{t-1}$,而这也揭示了循环神经网络天然地适合用于处理具有时序关系的数据。同时由图7-1可知,对于RNN模型来说其输入应该有3个维度,即批大小、时间步长和输入维度。
进一步,RNN模型的内部详细情况如图7-2所示。
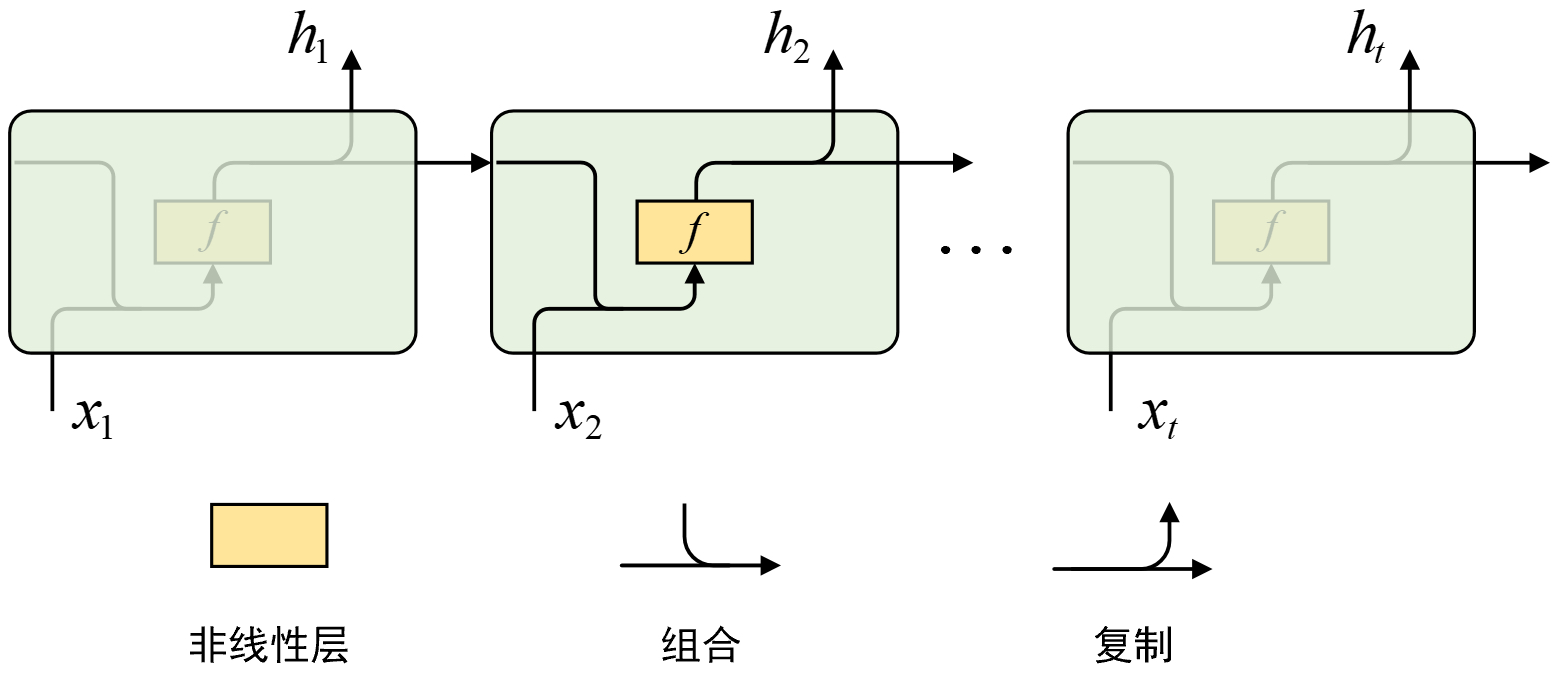
根据图7-2所示,RNN在沿时间维度展开时会先将上一时刻的输出和当前时刻输入分别进行一次线性变换并相加到一起,然后再经过一次非线性变换得到当前时刻的输出结果,具体计算过程如式(7-1)所示
$$ h_t=f(x_tU+h_{t-1}W+b)\tag{7-1} $$
其中$x_t$的形状为[batch_size,input_size],$h_{t-1}$的形状为[batch_size,hidden_size];$U,W,b$分别为模型的3个权重参数,形状分别为 [input_size,hidden_size]、[hidden_size,hidden_size]和[hidden_size]。同时,式(7-1)中的激活函数$f(\cdot)$可以是Tanh或ReLU等,并且这里需要再次提醒的是$U,W,b$这3个参数在每个时刻中共享。对于第1个时刻来说,通常其上一个时刻的输出将会被初始化为全0状态。
7.1.3 RNN计算示例#
在清楚了RNN模型的相关原理后,我们来通过一个实际的示例来体会RNN的计算过程。假定现在某个序列样本一共有3个时刻,每个时刻为一个4维向量,即
$$ X= \begin{bmatrix} x_1\\x_2\\x_3 \end{bmatrix}= \begin{bmatrix} 0.4&0.2&0.5&0.1\\ 0.1&0.3&0.2&0.0\\ 0.0&0.2&0.4&0.2 \end{bmatrix}_{1\times3\times4}\tag{7-2} $$同时设隐含状态的向量维度为2,初始状态$h_0$,权重参数$U,W$和$b$分别为
$$ \begin{aligned} h_0=\begin{bmatrix} 0.0&0.0 \end{bmatrix}_{1\times2}, \; \; U=\begin{bmatrix} 0.2&0.5\\ 0.1&0.1\\ 0.0&0.2\\ 0.3&0.3\\ \end{bmatrix}_{4\times2}, \; \; W=\begin{bmatrix} 0.1&0.1\\ 0.0&0.2 \end{bmatrix}_{2\times2},\;\;b=\begin{bmatrix} 0.5&0.5 \end{bmatrix}_{1\times2} \end{aligned}\tag{7-3} $$根据式(7-1)~式(7-3)可得
$$ \begin{aligned} h_1=&\tanh\left(\begin{bmatrix} 0.4&0.2&0.5&0.1 \end{bmatrix} \begin{bmatrix} 0.2&0.5\\ 0.1&0.1\\ 0.0&0.2\\ 0.3&0.3\\ \end{bmatrix}+ \begin{bmatrix} 0.0&0.0 \end{bmatrix} \begin{bmatrix} 0.1&0.1\\ 0.0&0.2 \end{bmatrix}+\begin{bmatrix} 0.5&0.5 \end{bmatrix} \right)\\[2ex] =&\tanh(\begin{bmatrix} 0.63&0.85 \end{bmatrix})=\begin{bmatrix} 0.558&0.691 \end{bmatrix} \end{aligned}\tag{7-4} $$进一步
$$ \begin{aligned} h_2=&\tanh\left(\begin{bmatrix} 0.1&0.3&0.2&0.0 \end{bmatrix} \begin{bmatrix} 0.2&0.5\\ 0.1&0.1\\ 0.0&0.2\\ 0.3&0.3\\ \end{bmatrix}+ \begin{bmatrix} 0.558&0.691 \end{bmatrix} \begin{bmatrix} 0.1&0.1\\ 0.0&0.2 \end{bmatrix}+\begin{bmatrix} 0.5&0.5 \end{bmatrix} \right)\\[2ex]=&\begin{bmatrix} 0.541&0.672 \end{bmatrix} \end{aligned}\tag{7-5} $$同理可得$h_3=[0.561\;\;0.690]$。
到此便完成了3个时刻的迭代计算过程。上述完整计算示例代码可参见Code/Chapter07/C01_RNN/main.py文件。
7.1.4 RNN类型#
在清楚了RNN模型的基本原理之后,我们再来总结一下通过RNN可以完成哪些任务。通常来说在利用RNN模型对时序数据进行特征提取后除了可以完成前面已经介绍过的分类任务之外,还可以完成各类序列生成的任务。如图7-3所示便是4种常见的RNN网络结构。
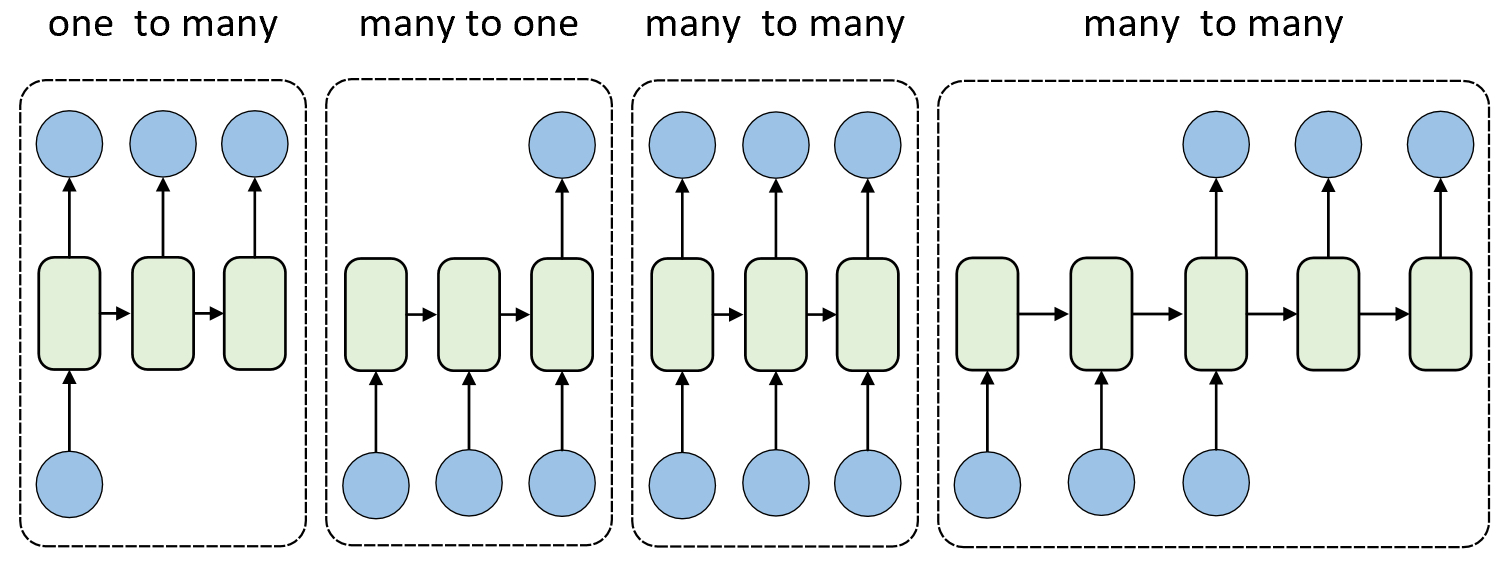
如图7-3所示,第1种基于RNN的便是一对多网络结构,它通常是将一个固定形状的样本作为输入,然后生成一段序列作为输出,例如在图像描述(Image Caption)任务中模型以一张图片作为输入,然后生成一段关于该图像的文本描述。第2种是多对一的网络结构,它是将一段序列作为输入,然后输出一个向量表示,例如在文本分类任务中模型以一句话作为输入,然后取最后一个时刻的输出作为整个文本的向量表示进行分类。第3种和第4种都是多对多的网络结构,它是将一段序列作为输入并同时输出一段序列,例如第3种可以用于完成命名体识别任务即对每个时刻的输出进行分类,第4种结构则可用于机器翻译或文本摘要等任务。在后面的章节中,我们将会结合具体的例子逐一对后面3种网络结构使用进行介绍。
7.1.5 多层RNN#
在实际情况中,为了提高模型的表达能力和捕获时间序列中更为复杂的特征关系,通常我们还可以通过在时间维度上堆叠多层RNN或者是进一步在层与层之间加入残差连接来对时序数据进行特征提取,如图7-4所示便是两种RNN的网络结构图。
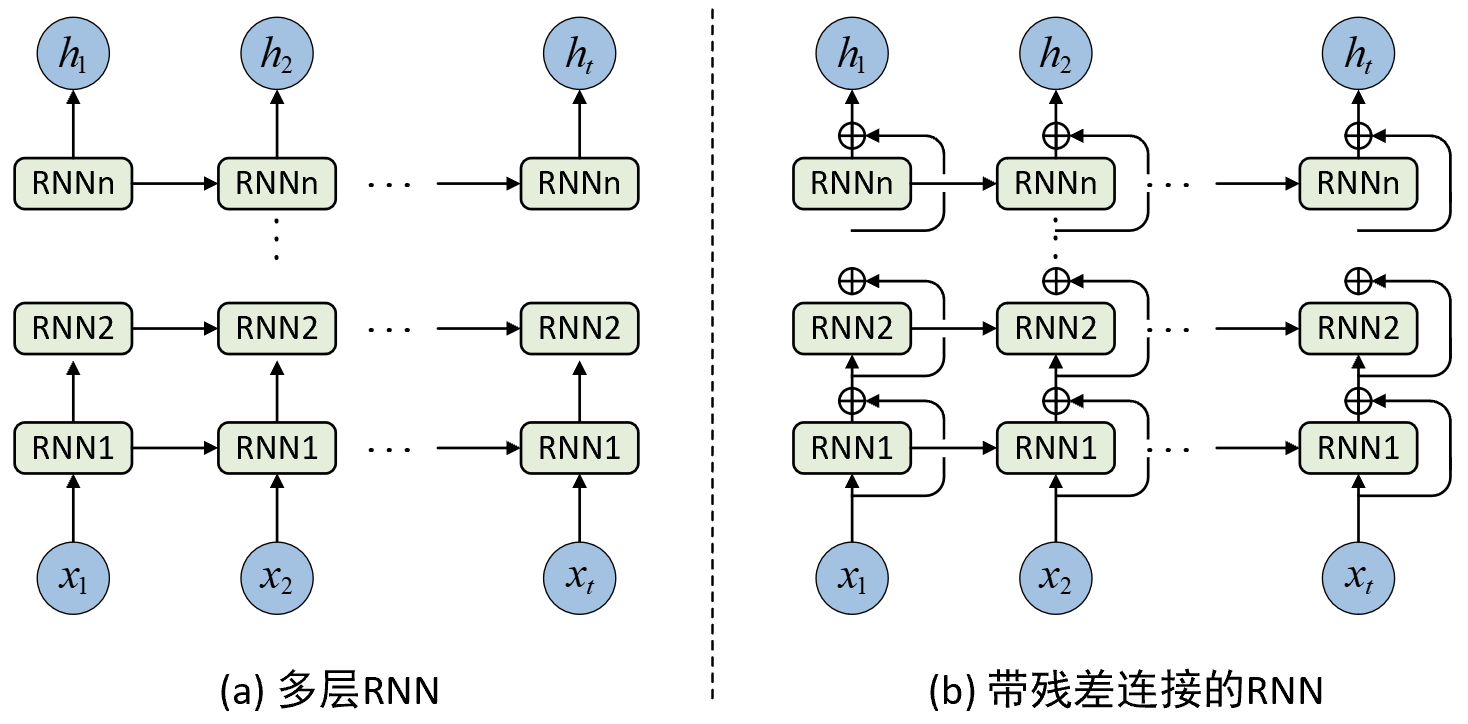
在图7-4(a)中,每一个RNN层可以看做是一个新的网络层,层与层之间拥有不同的权重参数。同时,每个RNN层处理前一层的输出结果并将其作为当前层对应时刻的输入,这样上一层的输出便可以在下一层中进一步进行特征提取,从而提高模型的表达能力。此外,在多层RNN中还可以通过对不同层使用不同的激活函数来捕获时间序列中更复杂的关系。
尽管我们可以通过多层RNN来提高模型的特征提取能力,但是如同深度卷积神经网络一样,当RNN的层数过深时越是靠近输入部分的网络层越有可能出现梯度消失的情况,因此我们也可以通过在多层RNN中引入残差连接[3]来解决这一问题。如图7-4(b)所示便是一个包含有残差连接的多层RNN网络结构示意图,我们只需要在多层RNN中对每个时刻的输入输出添加残差连接即可。在10.1节内容中,我们将会通过一个真实的案例来介绍如何实现带残差连接的RNN模型。
7.1.6 RNN示例代码#
在清楚RNN模型的原理及相关计算过程后,我们再来看如何借助PyTorch快速实现RNN模型,示例代码如下所示:
1 def test_RNN():
2 batch_size, time_step = 2, 3
3 input_size, hidden_size = 4, 5
4 x = torch.rand([batch_size, time_step, input_size])
5 rnn = nn.RNN(input_size, hidden_size,num_layers=2, batch_first=True)
6 output, hn = rnn(x)
7 print(output)
8 print(hn)在上述代码中,第2~3行用来指定输入数据的形状和RNN模型的相关参数。第4行用来随机生成2个样本,其形状为[batch_size, time_step, input_size],即每个时刻输入的形状为[batch_size, input_size]。第5行用来实例化一个RNN模型,其中num_layers用来指定堆叠RNN的层数,batch_first=True用来指定输入样本x的第1个维度是batch_size,如果输入样本x的形状为[time_step, batch_size, input_size],则batch_first=False。第6行则是前向传播计算后的结果,其中output是每个时刻的输出结果,形状为[batch_size, time_step, hidden_size],hn为每一层最后一个时刻的输出结果,形状为[num_layer, batch_size, hidden_size]。
在上述代码运行结束后便可得到如下所示结果:
1 tensor([[[-0.4105, -0.1765, -0.1841, -0.3735, 0.7065],
2 [-0.3786, -0.4841, -0.0448, -0.5592, 0.8887],
3 [-0.4521, -0.7022, 0.1086, -0.6730, 0.9050]],
4 [[-0.4229, -0.2368, -0.1486, -0.5219, 0.6402],
5 [-0.3374, -0.4731, -0.0064, -0.4605, 0.9147],
6 [-0.3468, -0.6689, -0.0019, -0.6433, 0.9181]]],
7 grad_fn=<TransposeBackward1>)
8 tensor([[[-0.8943, 0.1773, 0.0726, 0.7661, 0.0699],
9 [-0.8431, -0.3275, -0.0161, 0.7653, -0.0130]],
10 [[-0.4521, -0.7022, 0.1086, -0.6730, 0.9050],
11 [-0.3468, -0.6689, -0.0019, -0.6433, 0.9181]]],
12 grad_fn=<StackBackward0>)以上完整示例代码可以参见Code/Chapter07/C01_RNN/main.py文件。
7.1.7 BPTT原理#
在清楚RNN模型相关原理之后我们再来看一下如何求解模型中权重参数的梯度。在循环神经网络中,我们依旧需要使用到3.3节中介绍的反向传播算法来求解权重参数的梯度,只是在求解的过程中需要沿着时间的维度来依次进行展开,因此这里也称之为基于时间的反向传播(Back Propagation Through Time, BPTT)算法 [4] [5] [6]。以图7-2所示为例,假定RNN第$t$个时刻的输出为$h_t$,真实标签为$y_t$,误差为$E(h_t,y_t)$,此时整体损失为
$$ J=\frac{1}{T}\sum_{t=1}^TE(h_t,y_t)\tag{7-6} $$根据式(7-1)可得,目标函数$J$关于参数$W$的梯度为
$$ \frac{\partial J}{\partial W}=\frac{1}{T}\sum_{t=1}^T\frac{\partial E}{\partial h_t}\frac{\partial h_t}{\partial W}\tag{7-7} $$从式(7-7)可知,对于第1项的梯度来说容易求得,较为复杂的为第2项$h_t$关于$W$的梯度,因为$h_t$与$h_{t-1},h_{t-2},...,h_{1}$都有依赖关系。
此时根据链式法则有
$$ \begin{aligned} \frac{\partial h_t}{\partial W}&=\frac{\partial h_t}{\partial W}+\frac{\partial h_t}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial W}+ \frac{\partial h_t}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial h_{t-2}}\frac{\partial h_{t-2}}{\partial W}+\cdots+ \frac{\partial h_t}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial h_{t-2}}\cdots\frac{\partial h_{2}}{\partial h_{1}}\frac{\partial h_{1}}{\partial W}\\[3ex] &=\frac{\partial h_t}{\partial W}+\sum_{i=1}^{t-1}\left(\prod_{j=i+1}^t\frac{\partial h_{j}}{\partial h_{j-1}}\right)\frac{\partial h_{i}}{\partial W} \end{aligned} \tag{7-8} $$由此可知,虽然我们可以直接根据式(7-7)和式(7-8)来计算得到$J$关于$W$的梯度,但是当$t$很大,即序列过长时,越是靠近起始时刻的地方越是容易出现梯度爆炸或消失的情况,这也使得RNN模型很难学到输入序列中长距离的依赖关系。具体来说,因为RNN模型中存在循环结构,每个时间单元的输出会被作用于下一个时间单元的输入,这种循环结构导致反向传播在计算梯度时会出现多次相乘的情况,因此容易产生梯度消失或爆炸的现象,而这也类似于第4章中介绍到的普通深度卷积神经网络。所以,在实际情况中一个可行的办法是对式(7-8)中的梯度进行截断处理来得到其近似梯度[2]。
7.1.8 小结#
在本节内容中,我们首先介绍了RNN模型出现的动机及原理,并通过一个实际的计算示例来介绍了RNN的内部细节;然后介绍了多层RNN的构建原理并通过一个简单的示例介绍了如何在PyTorch框架中使用RNN模型;最后详细介绍了RNN中用于求解目标函数梯度的BPTT算法。到此,对于整个RNN的原理及详细计算过程就介绍完了,在下节内容中我们将开始介绍如何使用RNN模型来完成相关时序数据的分类任务。
引用#
[1] Elman J L. Finding structure in time[J]. Cognitive science, 1990, 14(2): 179-211.
[2] 阿斯顿·张、李沐、扎卡里 C. 立顿等,动手学深度学习[M],2版. 北京:人民邮电出版社, 2019.
[3] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint, 2014, arXiv:1409.0473.
[4] Werbos P J. Generalization of backpropagation with application to a recurrent gas market model [J]. Neural networks, 1988, 1(4): 339-356.
[5] Werbos P J. Backpropagation through time: what it does and how to do it [J]. Proceedings of the IEEE, 1990, (78)10:1550-1560.
[6] Rumelhart D E, Hinton G E, Williams R J. Learning Internal Representations by Error Propagation [J], Parallel Distributed Processing, 1986, (1)71: 599-607.