第 8 章 时序与模型融合#
经过第4章和第7章内容的介绍,我们对于深度学习中常见的两种网络结构CNN和RNN已经有了清晰的认识。CNN主要应用于处理在空间位置上具有相互依关系的特征数据,而RNN则主要应用于处理在时间维度上具有前后依赖的特征数据。可尽管如此,我们依旧可以根据CNN或者其与RNN的相应结合体来完成时序数据的特征提取过程。在本章内容中,我们将会介绍多种基于CNN和RNN的变体模型以及相应的应用案例。
8.1 TextCNN网络#
虽然CNN主要用于对输入矩阵相邻空间位置上的信息进行特征编码,但是其同样可以通过多尺度的卷积窗口来刻画时序数据在序列上的特征信息,例如比较经典的TextCNN[1]文本分类模型。TextCNN的核心思想便是基于词的粒度将每个词通过一个固定长度的向量来表示(即词向量,相关内容将在9.2节内容中进行介绍);然后再将一个句子中所有词的词向量垂直堆叠构成一个$n\times d$的矩阵,其中$n$表示该句中词的个数,$d$表示词向量的维度;最后再采用固定宽度的多尺度卷积核($m\times d$)进行特征提取并完成后续任务。
8.1.1 TextCNN结构#
TextCNN利用卷积操作对文本进行局部特征提取,通过不同大小的卷积核捕捉不同长度的局部特征,从而识别出文本中的关键信息。在TextCNN中,整个网络模型总体上分为3层,卷积层、池化层和全连接分类层,网络结构如图8-1所示。
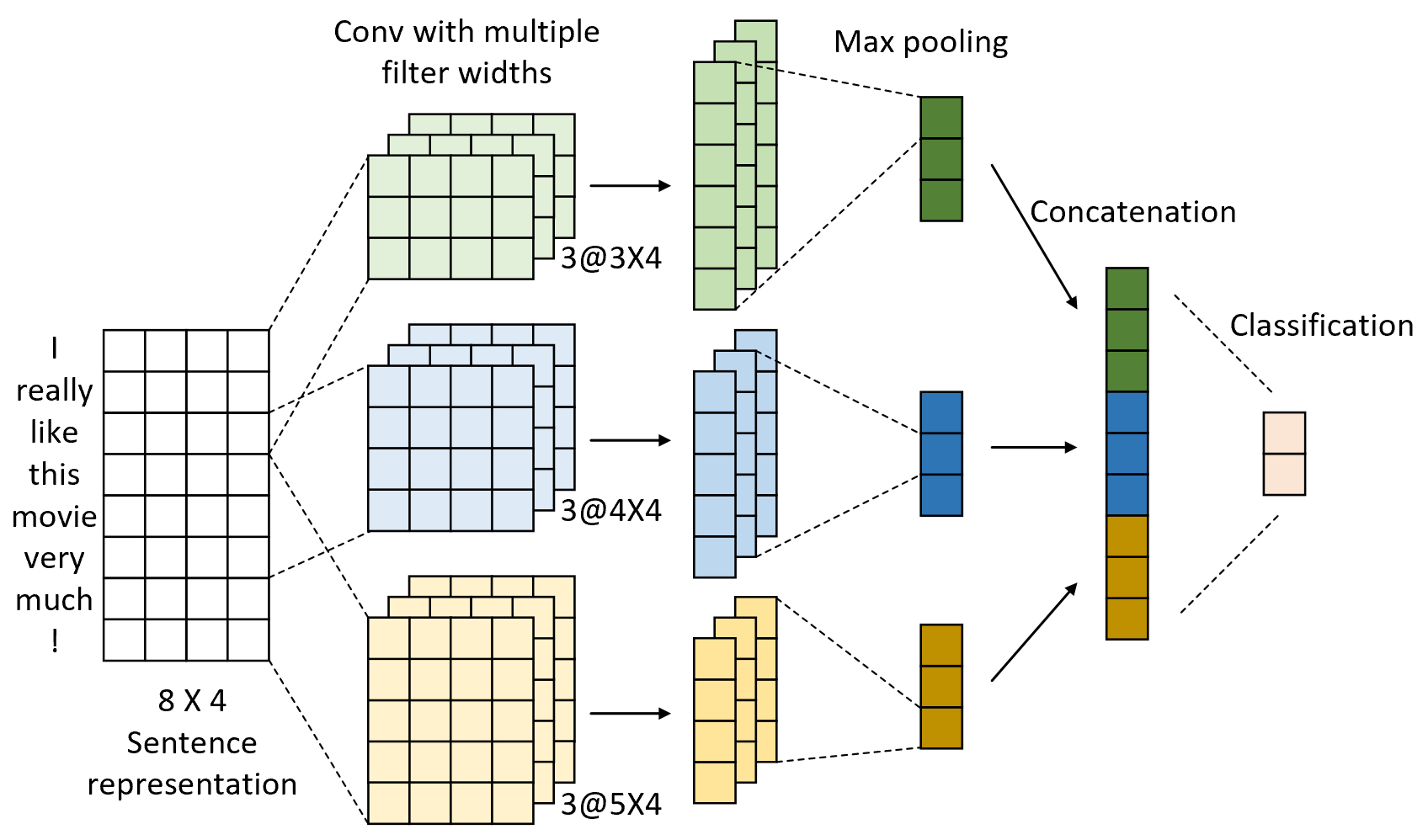
在图8-1中,最左侧为一个$8\times4$的特征矩阵,其中每一行均为一个4维向量,每个向量表示词表中固定的一个词。基于这样的表示方法,对于任意文本来说我们都可以将其表示成一个固定宽度特征矩阵,并且此时我们可以将其看做是一个单通道的特征图。进一步,TextCNN采用了3个不同窗口长度(分别为3、4、和5)的卷积核进行卷积处理。此时,由于卷积核的宽度同特征图的宽度一致,因此卷积结束后得到的便是一个一维的向量。可以看出,基于这样的卷积操作本质上也可以看作是在对文本的局部序列信息进行特征提取,其长度便依赖于卷积核的窗口长度。
在完成卷积操作完成之后,再通过最大化池化操作对每个特征图进行特征提取,此时的每个通道将会变成一个标量值。最后,再将所有结果拼接起来得到一个向量作为文本的特征表示,并追加一个分类层完成后续的分类任务。虽然TextCNN网络结构看似比较简单,但是在实际运用中往往都能取得较好的结果,并且训练速度快不容易过拟合。
8.1.2 文本分词#
在7.6节内容中我们使用了以单个字为粒度再加上一个词嵌入层的方式来表示文本,接下来我们再来看如何以词为粒度加词嵌入层来表示文本。当然,如果是英文语料的话就不存在字和词的差异了。
所谓分词指的是将一句话以中文语义的角度来对其进行分割,然后得到一个小词元。例如对于如下文本来说
《活着》是余华的小说,描绘了中国农民的苦难与坚韧。通过主人公福贵的生活经历,展现了战乱、饥饿和政治运动对人民的摧残,同时传递了关于家庭、希望和人性的深刻思考。
其分词后的结果为
《/活着/》/是/余华/的/小说/,/描绘/了/中国/农民/的/苦难/与/坚韧/。/通过/主人公/福贵/的/生活/经历/,/展现/了/战乱/、/饥饿/和/政治/运动/对/人民/的/摧残/,/同时/传递/了/关于/家庭/、/希望/和/人性/的/深刻/思考/。
然后再以词为单位进行词频统计构造词表并对文本进行向量化。
在文本处理中,jieba是一款常用的开源分词工具[3],可以通过命令pip install jieba进行安装。同时,jieba库分别提供了两种分词模式来应对不同场景下的中文分词,下面分别进行介绍。
1. 普通分词模式
普通分词模式指的是按照常规的分词方法,将一个句子分割成由多个词语组成的形式,示例代码如下:
1 import jieba
2 if __name__ == '__main__':
3 sen = "今天天气晴朗,阳光明媚,微风轻拂着脸庞,我独自漫步在河边的小径上。"
4 segs = jieba.cut(sen)
5 result = "/".join(segs)在上述代码中,第4行便是对原始文本进行分词处理并返回一个迭代器。第5行则是格式化处理后的结果,如下所示。
今天/天气晴朗/,/阳光明媚/,/微风/轻拂/着/脸庞/,/我/独自/漫步/在/河边/的/小径/上/。2. 全分词模型
虽然通过上述方式可以完成句子在词粒度层面的分割,但是对于有的词语来讲可以有不同的分词方法。此时,可以通过在上面的cut函数中指定全分词模式,即jieba.cut(sen, cut_all=True)来得到所有可能的分词结果。例如在开启全分词模式后,上述分词后的结果为
今天/今天天气/天天/天气/天气晴朗/晴朗/,/阳光/阳光明媚/光明/明媚/,/微风/轻拂/着/脸庞/,/我/独自/漫步/在/河边/的/小径/上/。在实际运用中可以根据情况来选择不同的模式。当然,jieba除了可以做分词处理之外,还提供了关键词抽取、词性标注和新词发现等功能,有需要的读者可以自行查阅学习。
8.1.3 TextCNN实现#
在清楚TextCNN模型的相关原理后,我们再来看如何借助PyTorch快速实现该模型。 以下完整示例代码可以参见Code/Chapter08/C01_TextCNN/TextCNN.py文件。
1. 前向传播
首先需要实现模型的整个前向传播过程。从图8-1可知,整个模型整体分为词嵌入层、卷积层、池化层和全连接4个部分,实现代码如下所示:
1 class TextCNN(nn.Module):
2 def __init__(self, vocab_size=2000, embedding_size=512,
3 window_size=None, out_channels=2, fc_hidden_size=128, num_classes=10):
4 super(TextCNN, self).__init__()
5 if window_size is None:
6 window_size = [3, 4, 5]
7 self.vocab_size = vocab_size
8 self.embedding_size = embedding_size
9 self.window_size = window_size
10 self.out_channels = out_channels
11 self.fc_hidden_size = fc_hidden_size
12 self.num_classes = num_classes
13 self.token_embedding = nn.Embedding(self.vocab_size, self.embedding_size)
14 self.convs = [nn.Conv2d(1, out_channels,
15 kernel_size=(k, embedding_size)) for k in window_size]
16 self.max_pool = nn.AdaptiveMaxPool2d((1, 1))
17 self.classifier = nn.Sequential(
18 nn.Linear(len(self.window_size) * self.out_channels, self.num_classes))在上述代码中,第5~12行是初始化相关模型超参数。第13行是实例化一个词嵌入层,即一个二维权重矩阵,其中每一行均为词表中每个词对应的唯一向量表示。第14~15行则是根据不同卷积窗口长度实例化多个卷积层。第16行是实例化一个自适应的最大池化层,其输出形状为[1,1],并且由于池化层没有参数所以多个卷积层可以共享同一个池化层。第17~18行是实例化一个分类层,其输入维度为卷积层的个数乘以每个卷积层输出的特征图通道数。
进一步,整个前向传播计算过程的示例代码如下所示:
1 def forward(self, x, labels=None):
2 x = self.token_embedding(x)
3 x = torch.unsqueeze(x, dim=1)
4 features = []
5 for conv in self.convs:
6 feature = self.max_pool(conv(x))
7 features.append(feature.squeeze(-1).squeeze(-1))
8 features = torch.cat(features, dim=1)
9 logits = self.classifier(features)
10 if labels is not None:
11 loss_fct = nn.CrossEntropyLoss(reduction='mean')
12 loss = loss_fct(logits, labels)
13 return loss, logits
14 else:
15 return logits在上述代码中,第1行x为每个句子分词后在词表里的索引表示,形状为[batch_size, src_len]。第2行为经过词嵌入层处理后的结果,输出形状为[batch_size, src_len, embedding_size]。第3行表示对x在第1个维度上进行维度扩充,处理后的形状为[batch_size, 1, src_len, embedding_size]。第4~7行为多尺度的卷积操作,其中第6行卷积和池化后的结果形状为[batch_size, out_channels, 1, 1],第7行是进行维度压缩至[batch_size, out_channels]并存放在列表中。第8行是将所有特征组合到一起,形状为[batch_size, out_channels*len(window_size)]。第9行是最后的分类层。第10~15行则是根据条件返回对应的处理结果。
最后,可以通过如下方式来进行使用:
1 if __name__ == '__main__':
2 x = torch.tensor([[1, 2, 3, 2, 0, 1],
3 [2, 2, 2, 1, 3, 1]])
4 labels = torch.tensor([0, 3])
5 model = TextCNN(vocab_size=5, embedding_size=3, fc_hidden_size=6)
6 loss, logits = model(x, labels)
7 print(logits.shape)输出结果为:
1 torch.Size([2, 10])2. 构造数据集
在这里,我们依旧使用7.2.4节中内容中所介绍的头条15分类数据集,只是需要将之前的字粒度改变为词粒度即可。具体地,我们需要在7.2.4节中介绍的TouTiaoNews模块中为tokenize函数再添加一种分词的处理逻辑,示例代码如下所示:
1 def tokenize(text, cut_words=False):
2 if cut_words:
3 text = jieba.cut(text)
4 words = " ".join(text).split()
5 return words在上述代码中,第2~3行便是新增的分词处理逻辑。
进一步,我们只需要在TouTiaoNews中使用到tokenize函数的地方传入cut_words参数即可以词粒度来构建数据集,具体示例代码可以直接查看源码。向量化后的样本类似如下结果:
1 ## 原始输入样本为: 去云南旅行会不会出现高原反应,应如何预防?
2 ## 分割后的样本为: ['去', '云南', '旅行', '会', '不会', '出现', '高原', '反应', ',', '应', '如何', '预防', '?']
3 ## 向量化后样本为: [60, 1220, 391, 29, 196, 317, 0, 2368, 2, 1343, 15, 0, 3]最终,我们在实例化TouTiaoNews时只需要同时传入cut_words=True即可:
1 if __name__ == '__main__':
2 toutiao_news = TouTiaoNews(top_k=4000,batch_size=12,cut_words=True)
3 test_iter = toutiao_news.load_train_val_test_data(is_train=False)
4 for x,y in test_iter:
5 print(x,y)3. 模型训练
由于这部分代码在之前也已经多次介绍过程,因此这里也不再赘述,各位读者直接参考源码即可。最后,在对网络模型进行训练时将会得到类似如下的输出结果:
1 Epochs[1/50]--batch[0/2093]--Acc: 0.0469--loss: 2.775
2 Epochs[1/50]--batch[50/2093]--Acc: 0.2109--loss: 2.4728
3 Epochs[1/50]--batch[100/2093]--Acc: 0.3203--loss: 2.229
4 Epochs[1/50]--batch[150/2093]--Acc: 0.4453--loss: 1.7122
5 Epochs[1/50]--batch[200/2093]--Acc: 0.5156--loss: 1.5143
6 Epochs[1/50]--batch[250/2093]--Acc: 0.5547--loss: 1.2475
7 Epochs[1/50]--batch[300/2093]--Acc: 0.5859--loss: 1.5477
8 Epochs[1/50]--batch[350/2093]--Acc: 0.6172--loss: 1.2619
9 Epochs[1/50]--batch[400/2093]--Acc: 0.6953--loss: 1.146
10 Epochs[1/50]--Acc on val 0.73118.1.4 小结#
在本节内容中,我们首先详细介绍了TextCNN的原理,其本质上可以看作是利用卷积操作来对序列数据进行局部特征提取的方法;然后简单介绍了分词的工具jieba的使用方法;最后介绍了如何一步一步实现TextCNN模型并在头条数据集上进行了测试。在下一节内容中,我们将会介绍基于RNN的TextRNN模型来进行文本分类。
引用#
[1] Kim Y. 2014. Convolutional Neural Networks for Sentence Classification [C]. In Proceedings of the 2014 Conference on EMNLP, pages 1746–1751.
[2] Zhang Y, Wallace B. A sensitivity analysis of (and practitioners’ guide to) convolutional neural networks for sentence classification[J]. arXiv preprint, 2015, arXiv:1510.03820.