9.10 注意力机制#
在9.9节内容中,解码器在解码时我们直接取了编码器最后一个时刻的输出进行循环解码,然而随着输入序列长度的增加这样的处理方式将会成为一种信息瓶颈( Information Bottleneck)[1] [2] [3],即使得解码器无法记住和区分源序列中各个时刻的编码信息。在本节内容中,我们将会学习到一种新的深度学习技术——注意力机制(Attention Mechanism)——来解决类似问题。
9.10.1 注意力的起源#
关于对人类注意力机制的研究最早大致可以追溯至19世纪下半叶。有着世纪之交最有影响力心理学家之称的威廉·詹姆斯在他的主要作品《心理学原理》中说到[4]:每个人都知道什么是注意力,注意力其实就是大脑以一种清晰生动的方式在多个同时存在的对象中选择占据其中一个的过程,即意识的集中和聚焦。所以,注意力也被形象的描述为根据有限认知处理和分配大脑资源的过程[5]。
例如在视觉注意力( Visual Attention )中,人类的视觉系统在处理视觉信息时会根据特定任务或环境选择性地集中关注某些区域,从而提高对这些区域的感知,使得我们能够在复杂的视觉场景中更有效地捕获重要信息[6]。

如图9-23所示,当我们注视于湖边的这只白鹭时,我们的大脑便会将更多的注意力分配到这只白鹭身上而减少对其周边环境的注意力。
正是受到人类注意力机制的启发,研究人员开始将这一思想运用于深度学习领域中。2014年姆尼赫等人[8]开始将注意力机制运用在基于循环神经网络的图像和视频分类模型中;2014年巴赫达瑙等人[1]第一次将注意力运用于机器翻译模型中;进一步,注意力机制的应用也开始出现在语音识别、图像描述、图像描述、摘要总结和文本分类等领域[9]。
9.10.2 注意力机制思想#
在Seq2Seq任务中,源输入序列的不同部分通常都具有不同的重要性,然而传统Encoder-Decoder模型在处理这一过程时并没有考虑到这种情况,因为它仅仅只是依靠上一个时刻的解码输出来对当前时刻进行解码。所以通过将源序列编码压缩得到一个固定维度的中间向量并直接进行解码的做法并不能有效地区分源序列中每个时刻的重要性,进而准确地预测每个时刻的输出结果。理想情况下,解码器在对不同时刻的输出进行解码时都应该将关注点放在编码器对应的不同时刻上。
例如在图9-22中,当解码器对第3个时刻“是”进行解码时,理论上模型应该更加专注于编码器中第2个时刻“am”对应的位置。同时,实验结果也表明当推理过程中输入序列的长度远大于训练集中的序列长度时,这种影响将会更加明显[1] [2]。
基于这样的动机,巴赫达瑙(Bahdanau)等人[1]在2014年首次提出了一种基于Seq2Seq架构的加法形式(Additive Style)注意力学习机制,其核心思想是对于解码器每个时刻的输出,模型可以对源输入序列的不同部分动态地分配注意力权重,使得模型可以更聚焦于编码序列中与当前输出时间步最相关的部分[3]。进一步,基于巴赫达瑙所提出的注意力框架,卢翁(Luong)等人[10]2015年又提出了一种乘法形式(Multiplicative Style)的注意力机制。
通过引入注意力机制,模型可以根据输入的上下文动态地将注意力权重分配到序列的不同位置上,而这也意味着模型可以更加灵活地关注重要位置上的信息,从而提高模型的预测能力。
9.10.3 注意力计算框架#
根据上面两个小节内容的介绍我们从直观上了解了什么是注意力机制以及注意力机制的主要作用,因此接下来我们需要知道在深度学习中如何表示注意力以及如何设计一个通用的注意力计算框架。由于注意力的本质就是对有限资源的一个分配过程,自然而然我们可以通过一个权重向量来表示注意力的分配情况,权重越大的位置便给予更高的注意力。所以,如何设计一个有效的框架来计算注意力权重向量便成了我们接下来需要解决的问题。
1. 计算框架
在信息检索系统中,通常我们可以根据关键字在数据库中检索得到离我们期望结果最相似的输出结果,而这样一个过程便可以作为注意力计算框架的灵感来源。例如对于一个视频网站来说,用户可以通过关键字(Query)在标题表(Keys)中检索得到与之最为匹配的标题,然后再通过标题从视频库(Values)中检索得到对应视频并返回给用户,整个结构如图9-24所示。
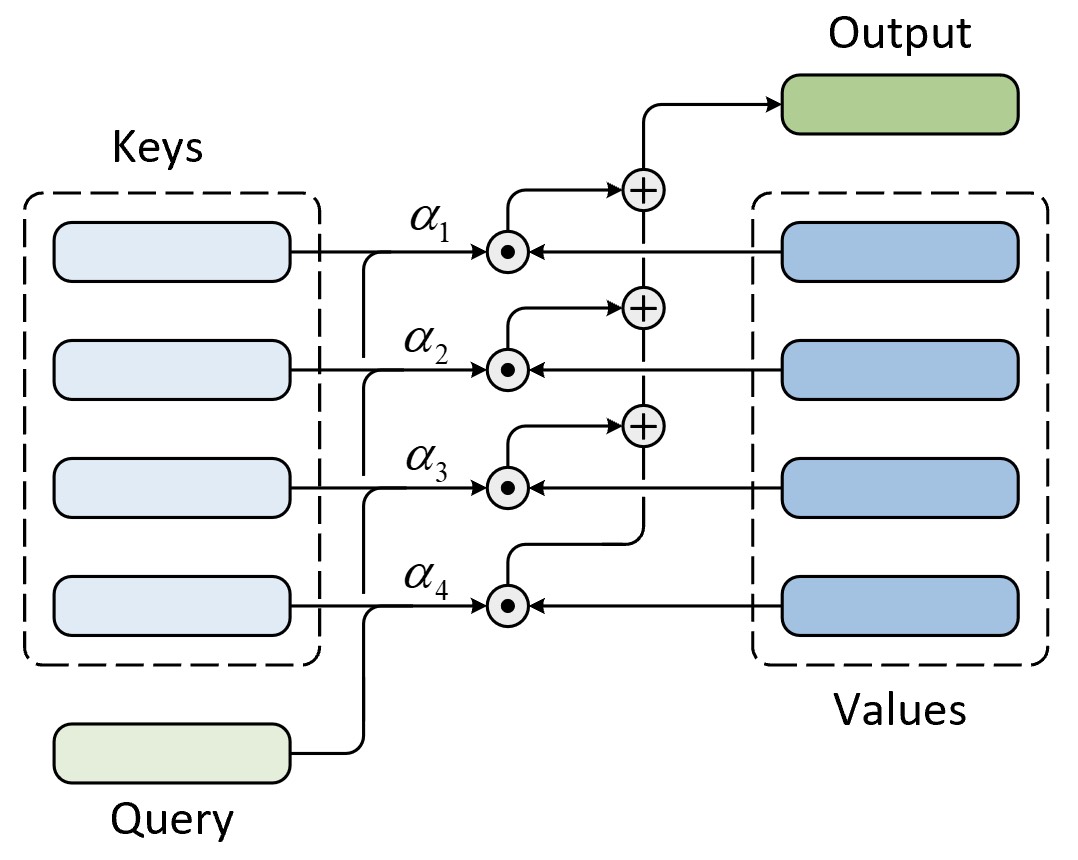
在图9-24中,视频检索系统首先根据用户输入的关键词Query同视频标题Keys中的每个标题进行相似性计算并得到一个权重向量$\alpha$ ,其中$\alpha_i$表示Query与第$i$个标题的相似程度;最后根据$\alpha$便可以从Values中返回相应的视频内容。此时,权重向量$\alpha$便可以理解为当输入关键词为Query时检索系统应该如何将注意力分配到各个视频内容上的度量。进一步,如果将$\alpha$限制为One-hot编码形式则被称之为硬注意力(Hard Attention),此时将只会返回Values中的一个值;通常情况下$\alpha$将会被归一化成一个概率分布称之为软注意力(Soft Attention),此时将会返回所有Values的加权结果。
同时,对于不同的模型来说Query、Keys和Values都不尽相同,并且需要注意的是Keys和Values一一对应出现。例如在Seq2Seq架构中Query通常取自目标序列编码后的隐含状态,Keys和Values则都取自源序列编码后的隐含状态。
2. 计算流程
根据上述注意力计算框架,含有注意力机制的NMT模型在对每个时刻进行解码时,其注意力计算过程可以通过图9-25进行表示 [2] [3] [11]。
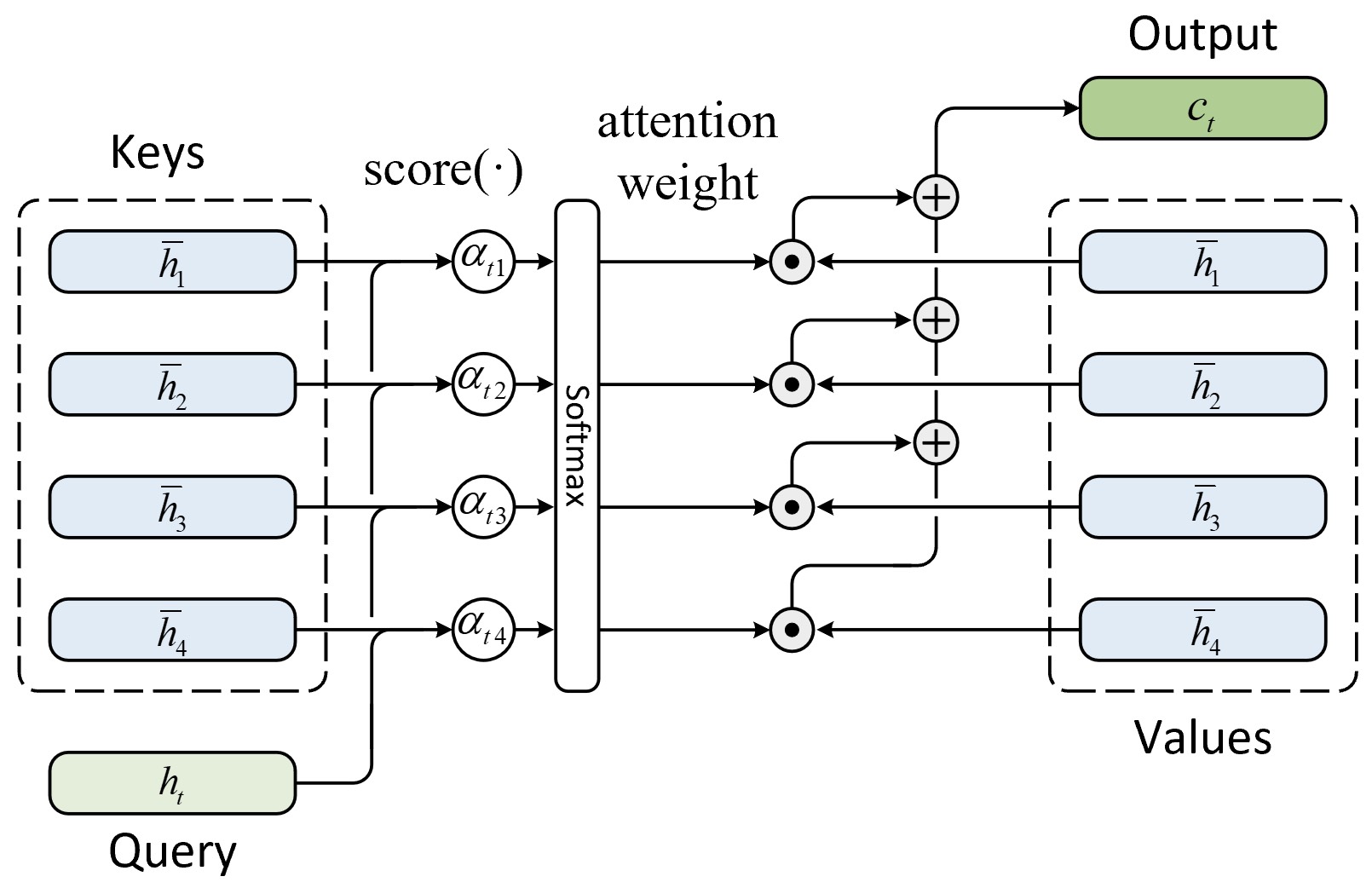
如图9-25所示便是解码器解码时注意力机制的计算原理图,其中Query表示第$t$时刻解码器的隐含状态$h_t$,Keys表示编码器中所有时刻的隐含状态$\overline{h}_1,\overline{h}_2,..\overline{h}_S$,此时Values与Keys相同。进一步,整个含注意力的解码过程可以表示为如下4步。
①将第$t$时刻的隐含状态同编码器中所有时刻的隐含状态进行比较,根据式(9-37)计算得到注意力权重(Attention Weights)。
$$ \alpha_{ts}=\frac{\exp\left(\text{score}(h_t,\overline{h}_s)\right)}{\sum_{s^{\prime}=1}^S\exp\left(\text{score}(h_t,\overline{h}_{s^{\prime}})\right)}\in\mathbb{R}\tag{9-37} $$