《跟我一起学深度学习》第1版勘误#
印刷版次:第1次#
NO. 1001
P53,标题 3) 测试PyTorch下,将 “如下脚来测试” 改为 “如下脚本来测试”
NO. 1002
P68,公式(3-3)下,将"$y^{(i)}$表示第$i$个房屋的预测价格" 改为 “$\color{red}{\hat{y}}^{(i)}$表示第$i$个房屋的预测价格”
NO. 1003
P188,第4.6.4小结下,将 “VGG11模型进行了测试” 改为 “VGG16模型进行了测试”
NO. 1004
P190,标题 2.前向传播下,将第10行代码中 “nn.ReLU(inplace=True), " 删除
NO. 1005
P168,第4.3.7小结下,将 “及其左右” 改为 “及其作用”
NO. 1006
P168,第4.4.1小节第2行末尾,将 “感知机卷积” 改为 “感知机",即去掉"卷积”
NO. 1007
P134,标题 2.惩罚系数下 第3行头,将 “环境模型” 改为 “缓解模型”
NO. 1008
P460,公式(10-8)下,将 “$W^K_i\in R$, $W^O\in R$” 改为 “$W^K_i\in R^{\color{red}{d\times d_k}}$,$W^O\in R^{\color{red}{hd_v\times d}}$”
NO. 1009
P136,标题 3.模型训练下第1段文字,将 “第211行” 改为 “第210行” , 将 “第12行” 改为 “第11行”
NO. 1010
P143,公式(3-121)中,将 “$-\gamma$” 改为 “$\color{red}{\gamma}$” ,将 “其导数为$-\gamma$” 改为 “其导数为$\color{red}{\gamma}$",将页末处 “激活值$-\gamma$” 改为 “激活值$\color{red}{\gamma}$”
NO. 1011
P146,公式(3-125)下,将 “$n$表示样本总数” 改为 “$\color{red}{m}$表示样本总数”
NO. 1012
P441,标题2. 改造前向传播方法下,将第14行代码 “query = decoder_state[0]” 改为 “query = decoder_state[-1]” ;将下方第8行文字中 “tgt_in 的形状为 [batch_size, 1, embedding_size]” 改为 “tgt_in 的形状为 [batch_size, embedding_size]";将 “用于压缩维度,将变成[batch_size, embedding_size]” 改为 “用于扩张维度,将变成[batch_size, 1, embedding_size]”
NO. 1013
P160,倒数第6行中,将 “单通道卷积核多通道” 改为 “单通道卷积和多通道”
NO. 1014
P165,公式(4-6)下,将 “[14,14,64]” 改为 “[16,16,64]”
NO. 1015
P176,表4-2下第3行,将 “倒数第1个” 改为 “第1个”
NO. 1016
P182,标题4.6.2VGG结构下,将 “第1例” 改为 “第1列”
NO. 1017
P57,标题 2.使用 Jupyter Notebook 下, 将 “通过 –prot” 改为 “通过 –port”
NO. 1018
P82,将公式(3-20)
$$ \begin{aligned} \frac{\partial J}{\partial w^1_{11}}&=\frac{\partial J}{\partial a^3_{1}}\frac{\partial a^3_{1}}{\partial z^3_{1}}\frac{\partial z^3_{1}}{\partial a^2_1}\frac{\partial a^2}{\partial z^2_1}\frac{\partial z^2_1}{\partial w^1_{11}}+\frac{\partial J}{\partial a^3_{2}}\frac{\partial a^3_{2}}{\partial z^3_{2}}\frac{\partial z^3_{2}}{\partial a^2_1}\frac{\partial a^2}{\partial z^2_1}\frac{\partial z^2_1}{\partial w^1_{11}}\\[3ex] \frac{\partial J}{\partial w^1_{12}}&=\frac{\partial J}{\partial a^3_{1}}\frac{\partial a^3_{1}}{\partial z^3_{1}}\frac{\partial z^3_{1}}{\partial a^2_1}\frac{\partial a^2}{\partial z^2_1}\frac{\partial z^2_1}{\partial w^1_{12}}+\frac{\partial J}{\partial a^3_{2}}\frac{\partial a^3_{2}}{\partial z^3_{2}}\frac{\partial z^3_{2}}{\partial a^2_1}\frac{\partial a^2}{\partial z^2_1}\frac{\partial z^2_1}{\partial w^1_{12}}\\ &\vdots\\ \frac{\partial J}{\partial w^2_{22}}&=\frac{\partial J}{\partial a^3_2}\frac{\partial a^3_2}{\partial z^3_2}\frac{\partial z^3_2}{\partial w^2_{22}} \end{aligned}\tag{3-20} $$改为
$$ \begin{aligned} \frac{\partial J}{\partial w^1_{11}}&=\frac{\partial J}{\partial a^3_{1}}\frac{\partial a^3_{1}}{\partial z^3_{1}}\frac{\partial z^3_{1}}{\partial a^2_1}\frac{\partial \color{red}{a^2_{1}}}{\partial z^2_1}\frac{\partial z^2_1}{\partial w^1_{11}}+\frac{\partial J}{\partial a^3_{2}}\frac{\partial a^3_{2}}{\partial z^3_{2}}\frac{\partial z^3_{2}}{\partial a^2_1}\frac{\partial \color{red}{a^2_{1}}}{\partial z^2_1}\frac{\partial z^2_1}{\partial w^1_{11}}\\[3ex] \frac{\partial J}{\partial w^1_{12}}&=\frac{\partial J}{\partial a^3_{1}}\frac{\partial a^3_{1}}{\partial z^3_{1}}\frac{\partial z^3_{1}}{\partial a^2_1}\frac{\partial \color{red}{a^2_{1}}}{\partial z^2_1}\frac{\partial z^2_1}{\partial w^1_{12}}+\frac{\partial J}{\partial a^3_{2}}\frac{\partial a^3_{2}}{\partial z^3_{2}}\frac{\partial z^3_{2}}{\partial a^2_1}\frac{\partial \color{red}{a^2_{1}}}{\partial z^2_1}\frac{\partial z^2_1}{\partial w^1_{12}}\\ &\vdots\\ \frac{\partial J}{\partial w^2_{22}}&=\frac{\partial J}{\partial a^3_2}\frac{\partial a^3_2}{\partial z^3_2}\frac{\partial z^3_2}{\partial w^2_{22}} \end{aligned}\tag{3-20} $$NO. 1019
P86,第1段第2行,将 “导出了” 改为 “推导出了”
NO. 1020
P96,最后1行,将 “(例如素)” 改为 “(例如像素)”
NO. 1021
P90,将第1段文字第2行中 “带预测” 改为 “待预测”;将第3段文字第2行中 “带预测” 改为 “待预测”;将3.4.3节下第2行中 “内容导出” 改为 “内容推导出”
NO. 1022
P130,最后1段倒数第3行,将 “$1-p=2.5$” 改为 “$\color{red}{x/(1-p)}=2.5$”
NO. 1023
P131,将公式(3-113)整体修改为
$$ E(o^{\prime}_i)=p\cdot\frac{0}{1-p}o_i+(1-p)\cdot\frac{1}{1-p}o_i=\frac{1-p}{1-p}o_i=o_i\tag{3-113} $$NO. 1024
P46页,小标题 2.Python安装环境上,代码第1行中,将 “xedu” 改为 “edu”
NO. 1025
P303页,第7.1.8节小结下,第3行,将"介绍了RNM” 改为"介绍了RNN”
NO. 1026
P308页,下方倒数第2个代码块中,将第3行 “b=torch.tensor([1,0,1])” 改为 “b=torch.tensor([1,5,1])”
NO. 1027
P599页,图10-65中,上面应是t=5,下面应是t=6,如下所示。
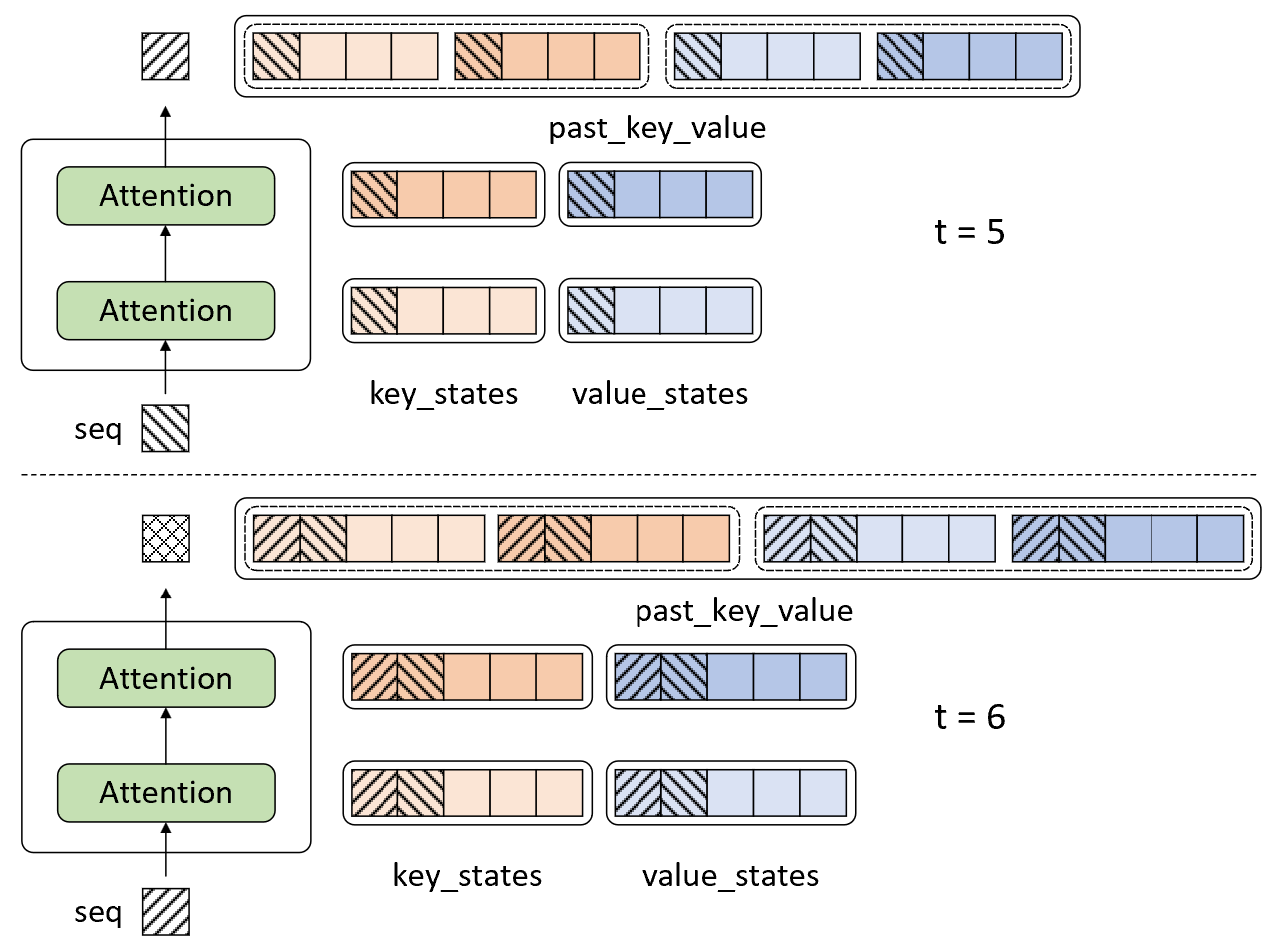
NO. 1028
P103页,图3-31中,将第一层神经元个数由768改为 784,即替换为下图
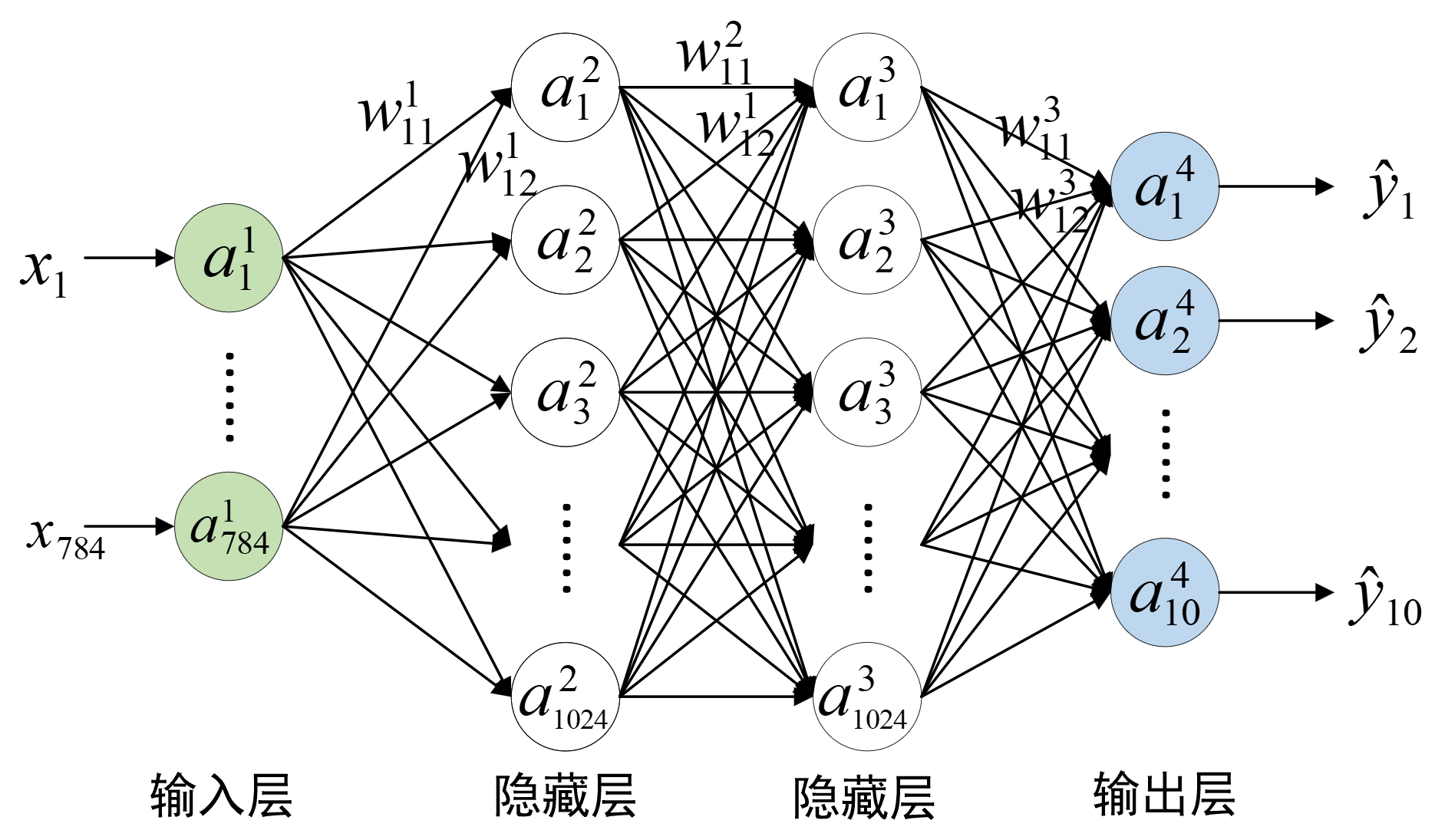
NO. 1029
P332页,上面第2个代码块,第4~5行代码,将"朝辞仙子去,…… 临池水岸间。“这两行改为”朝辞白帝彩云间,万仞山阴独未还。燕子入时寒食好,玉杯销尽百年心。”
NO. 1030
P549页上面第二段,第5行,将"……更新的上下文情境学习(In-Context Learning)或少样本学习(Few-Shot Learning)方法。“改为”……更新的上下文情境学习(In-Context Learning)方法。"
NO. 1031
P51页标题4. PyTorch安装下,将"pip install torch==2.0.1" 改为"pip install torch==2.0.1 –index-url https://download.pytorch.org/whl/cpu"
NO. 1032
P104页,公式(3-63),最前面将 $\delta^{L}_i$ 改为 $\color{red}{\delta^{L}_j}$
以上错误在第2次印刷中已经纠正。
印刷版次:第2次#
NO. 1033
P611页,标题“10.19.6 模型解码过程”上面,将“第8~12行用于……的解码输出。”这句话改为
第8行取原始输出的 logits 值。第9行是对模型输出的原始 logits 做约束和过滤,例如禁止某些词元生成,不过这里 logits_processor 内部默认没有进行任何处理。第10行是对 logits 做概率调整,它会影响生成的随机性,本质与10.15.2节中的 top_k_top_p_filtering 函数一致。第11~12行则是根据采样的策略来得到当前时刻的解码输出。
NO. 1034
P553页,标题“10.15.2 生成结果筛选”改为“10.15.2 生成结果采样”
将10.15.2节下第2段“生成结果筛选的原理……根据采样策略得到预测值。”替换为:
虽然根据模型的输出 logits 便可以采样得到当前时刻的预测输出,但此时却可能输出一些极不合理的词元,因为低概率的词元同样可能被采样到,因此就需要通过某种策略来滤掉这些"不靠谱"的候选词,而这就是 Top-K 和 Top-P 采样的由来,如图10-44所示便是整个生成结果采样的原理示意图。
Top-K 采样的思路很直接,它只保留概率最高的前 K 个词元,把其余所有词元 的 logits 设为负无穷,然后在这 K 个候选里进行采样。尽管 Top-K 策略在一定程度上解决了候选词"不靠谱"这个问题,但是还没有完全解决,的问题在于 K 是一个固定值,假如词表一共上万个词,那 K 是取 30、50、还是 100 并不好确定,因为当模型非常"自信"时概率只会高度集中在少数几个词上,此时 K 无论取前面哪个值依旧可能会引入很多不必要的噪声;而当模型比较"困惑"时概率分布很很分散,K 太小又可能过于保守,错过一些合理的候选词。
进一步,Top-P 的做法是将所有词元按概率从高到低排列逐个累加,直到累积概率达到阈值 P 为止,保留这个集合内的所有词元,其余置为负无穷。可以看出,Top-P 采样不再固定候选词的数量,而是固定候选词的累积概率。
P554页,将本页最后一段“在上述代码中,第2行用于……多样和随机的文本。”替换为:
在上述代码中,第2行是检查top_k取值是否超过了序列长度,是则直接取序列长度。第3~5行便是图10-44中第①步处理后的结果,即据预测得到的logits取前Top_k为候选结果,并将剩余部分置为负无穷大。第6~13行则是图10-44中第②步中的处理过程。第7行表示对原始logits进行排序并得到排序后的结果以及在原始logits中的索引。第8~9行是对排序后的sorted_logits进行归一化处理并计算累积概率,同时得到大于top_p的位置标记。第10~11行是为了避免当top_p设置过小导致所有结果都被忽略所考虑的情况,所以需要将sorted_indx_to_remove 中的结果整体向后移动一位并将第1个位置直接置为F(表示一定会有一个筛选结果剩下)。第12~13行是根据indices_to_remove将logits中满足条件的值忽略,设置为负无穷大。从这里可以看出,通过调整阈值top_p可以在不同的生成效果之间找到平衡,较小的阈值将导致模型生成更加集中和确定性的文本,而较大的阈值将产生更加多样和随机的文本。