5.4 拥有短期记忆的 RAG Agent#
在上一节内容中详细介绍了短期记忆管理的3种方式,删除、修剪和总结。在本节内容中,我们将基于第4.10节的内容实现一个类似 ChatGPT 的 RAG 问答工具,做到每次回答完用户问题后都判断是否需要对历史消息进行一次总结,并同步将会话消息实时保存到数据库,使得每次启动程序时都能恢复历史会话。
5.4.1 流程构建思路#
为了实现上述目的,需要在图4-13的图结构之上再添加一个条件判断边和一个节点,来判断是否需要对历史记忆进行总结以及如何总结,整个流程如图5-6所示。
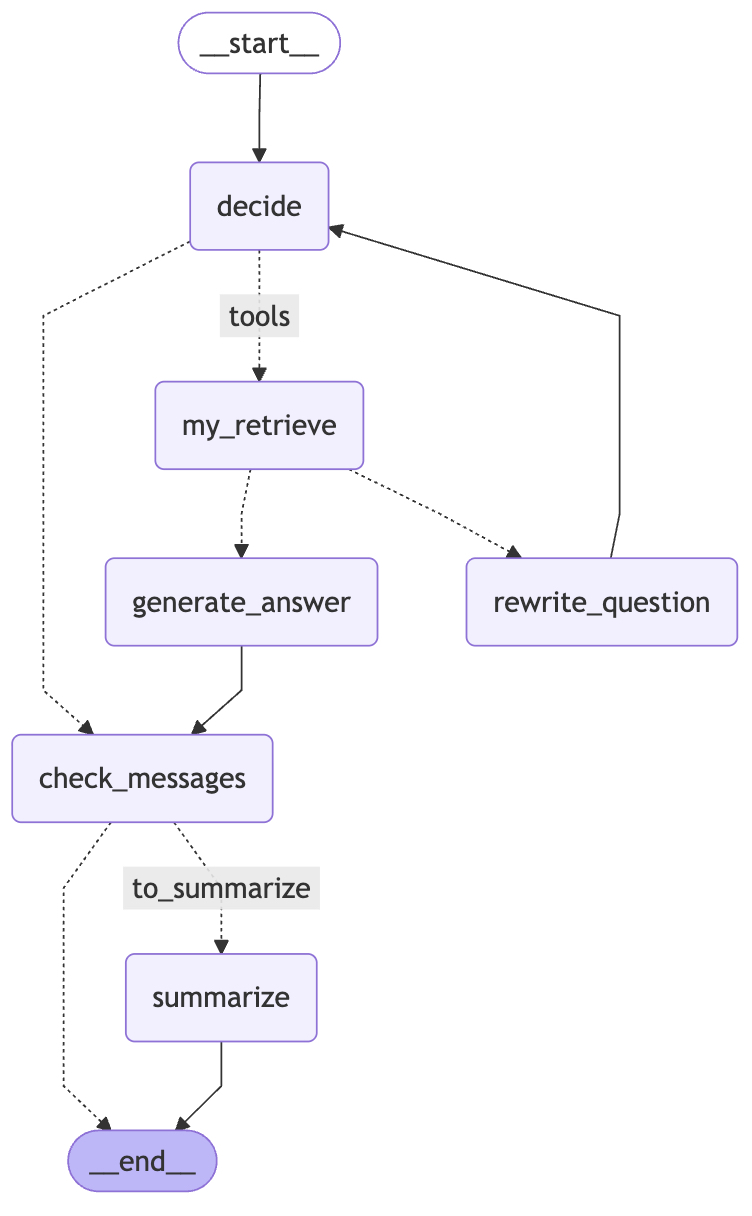
从图5-6可以看出,在每一轮回答结束以后两个分支都会统一汇集到 check_messages 节点,然后再通过条件分支判断是否需要进行历史消息总结。下面逐一对这部分内容进行介绍。
5.4.2 分支汇集与条件判断#
由于 decide 这条边已经用 tools_condition 在做“是否调用工具”的分流,即 add_conditional_edges("decide",tools_condition, {"tools": "my_retrieve", END: END}),而 tools_condition 的映射是静态的,没法在左侧的 END 分支里再动态判断一次是否应该进行记忆总结,所以需要添加一个空节点来做汇集,即图5-6中的 check_messages,其对应的实现为:
1 def passthrough(state: MyState) -> MyState:
2 return {}在上述代码中,第2行 return {} 表示更新内容为空,即不对传入的 state 做任何修改。
进一步,实现是否需要进行总结的条件判断,示例代码如下:
1 def count_messages(state: MyState) -> Literal[END, "to_summarize"]:
2 messages = state["messages"]
3 threshold = 5
4 if len(messages) > threshold:
5 return "to_summarize"
6 else:
7 return END在上述代码中,我们简单地使用消息条数来进行判断,当然也可以是其它策略。第4~7行是根据条件判断流向 to_summarize 节点或直接结束。
5.4.3 历史记忆总结#
接着,在第5.2.4节实现的 summarize_conversation 基础之上,再来对内部进行一些改造,使得能够更加灵活的总结和删除对应的历史记忆,示例代码如下:
1 def summarize_conversation(state: MyState) -> MyState:
2 ......
3 trimmed = trim_messages(state["messages"], max_tokens=5, strategy="last",
4 token_counter=len, start_on="human", end_on=("human", "ai"))
5 trimmed_msg_ids = [msg.id for msg in trimmed] # 保留下来的消息
6 delete_messages, summary_messages = [], []
7 for msg in state["messages"]:
8 if msg.id not in trimmed_msg_ids:
9 delete_messages.append(RemoveMessage(id=msg.id))
10 if msg.type != 'tool':
11 summary_messages.append(msg)
12 summary_messages += [HumanMessage(content=summary_message)]
13 response = get_llm_model().invoke(summary_messages)
14 return {"summary": response.content, "messages": delete_messages}在上述代码中,第3~4行中先使用 trim_messages 函数来对需要保留的消息记录做一次条件筛选,最多保留最后的5条消息,这样能够使得保留下来的消息更上下文更加完整。第5行是得到待保留消息的 ID,第7~11行是遍历原始状态中的每一条消息,然后标记待删除的消息,以及根据消息类型筛选待总结的消息,因为工具返回的内容篇幅通常很长,而且不一定都有用,所以去掉这部分内容。
5.4.4 搭建完整流程#
在完成上述节点定义以后,最后来完成整个图的构建过程,示例代码如下:
1 def get_workflow(checkpointer: PostgresSaver):
2 workflow = StateGraph(MyState)
3 ...
4 workflow.add_node("check_messages", passthrough)
5 workflow.add_node("summarize", summarize_conversation)
6 workflow.add_edge(START, "decide")
7 workflow.add_conditional_edges("decide",tools_condition,
8 {"tools": "my_retrieve", END: "check_messages"})
9 workflow.add_conditional_edges("my_retrieve", grade_documents)
10 workflow.add_edge("generate_answer", "check_messages")
11 workflow.add_conditional_edges("check_messages", count_messages,
12 {"to_summarize": "summarize", END: END})
13 workflow.add_edge("summarize", END)
14 workflow.add_edge("rewrite_question", "decide")
15 graph = workflow.compile(checkpointer=checkpointer)
16 return graph在上述代码中,第4~5行为新注册的两个节点,分别用来做汇集和记忆总结。第7~8行是添加 “decide” 节点到到工具调用的条件边,这里 END 边的指向由先前的 END:END 变为了 END: "check_messages",如图5-6所示。第10行是添加节点 generate_answer 到节点 check_messages 的变,此时所有下一步需要判断是否进行记忆总结的边就汇集到一起了,这样逻辑更集中避免了在多个地方重复写同一套判断逻辑。第11~12行是在节点 check_messages 上添加一个条件边,将根据 count_messages 的返回值来选择下一步走向的节点,即 summarize 或 END。
5.4.5 结果分析#
在完成上述实现以后,进一步可通过如下方式来运行整个工程,示例代码如下:
1 if __name__ == '__main__':
2 with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
3 agent = get_workflow(checkpointer)
4 vector_store = get_vector_store()
5 config = RunnableConfig(configurable={"vector_store": vector_store,
6 "k": 20, "top_n": 3, "thread_id": "fd1bd9f0-5d3c-487a-938e-b14513efa48k"},
callbacks=[ConsoleCallbackHandler()])
7 print(f"#服务启动成功!")
8 print_memory(agent, config)
9 print(f"\n{'-' * 30}历史记录已恢复,继续用户会话{'-' * 30}")
10 while True:
11 print(f"\t\t\t\t{'-' * 20}开始新的提问{'-' * 20}")
12 question = input()
13 user = {"messages":convert_to_messages([{"role":"user","content":question}])}
14 for event in agent.stream(user, config=config):
15 for node, update in event.items():
16 if not update or "messages" not in update or not update["messages"]:
17 continue
18 msg = update["messages"][-1]
19 if msg.type == "ai":
20 msg.pretty_print()在上述代码中,第6行 thread_id 指定了一个唯一会话ID,这样每次重启本工程都能够恢复到之前退出时的历史状态,同时这里指定了callbacks 用于输出详细信息。第8行是输出历史记录。第10~20行是开始循环迭代根据用户提问进行回答,其中第12行表示从终端接收输入作为用户提问。
下面,我们先从一个新的会话开始在触发一次消息总结以后退出,然后再次运行程序进行提问来观察整个结果的变化。首先,初次运行上述代码并进行提问,可以得到类似如下结果:
#服务启动成功!
thread_id=fd1bd9f0-5d3c-487a-938e-b14513efa48k 暂无已持久化的短期记忆
------------------------------历史记录已恢复,继续用户会话------------------------------
--------------------开始新的提问--------------------
郭靖和杨康是什么关系?
#### 节点 decide 处理完毕
================================== Ai Message ==================================
#### 节点 my_retrieve 处理完毕
#### 节点 generate_answer 处理完毕
================================== Ai Message ==================================
郭靖和杨康是结义兄弟。两人在郭啸天的灵前对拜八拜,正式结为兄弟,郭靖年长一个月,为兄,杨康为弟。
--------------------开始新的提问--------------------
他们两个谁大?
#### 节点 decide 处理完毕
================================== Ai Message ==================================
郭靖比杨康大一个月,因此郭靖是兄长,杨康是弟弟。
消息数大于5, 开始总结
#### 节点 check_messages 处理完毕
全部内容: [HumanMessage(content='郭靖和杨康是什么关系?', id='56b89363-1530-45fe'), AIMessage(content='', id='lc_run--019e622c-79e3-7002', tool_calls=[{'name': 'retrieve_context', 'args': {'query': '郭靖和杨康的关系'}}], ToolMessage(content='杨康边哭边说,涕泪滂沱,断断续续地道:“我是郭靖的结义兄弟,郭大哥给人用这铁枪的枪头刺死了。......', name='retrieve_context', id='6e355c8b-b840-4be6',......), AIMessage(content='郭靖和杨康是结义兄弟。两人在郭啸天的灵前对拜八拜,正式结为兄弟,郭靖年长一个月,为兄,杨康为弟。', id='lc_run--019e622c-89be-7a12', ), HumanMessage(content='他们两个谁大?', id='4bde66a9-19fc-495d'), AIMessage(content='郭靖比杨康大一个月,因此郭靖是兄长,杨康是弟弟。',id='lc_run--019e622c-ae28-7362')]
总结内容: [HumanMessage(content='郭靖和杨康是什么关系?', id='56b89363-1530-45fe'), AIMessage(content='', id='lc_run--019e622c-79e3-7002', tool_calls=[{'name': 'retrieve_context', 'args': {'query': '郭靖和杨康的关系'}}]), AIMessage(content='郭靖和杨康是结义兄弟。两人在郭啸天的灵前对拜八拜,正式结为兄弟,郭靖年长一个月,为兄,杨康为弟。', id='lc_run--019e622c-89be-7a12')]
删除内容: [RemoveMessage(content='',id='56b89363-1530-45fe'), RemoveMessage(content='', id='lc_run--019e622c-79e3-7002'), RemoveMessage(content='', id='6e355c8b-b840-4be6'), RemoveMessage(content='', id='lc_run--019e622c-89be-7a12')]
历史记忆总结完毕:
该对话围绕“郭靖和杨康的关系”展开。用户提问后,系统调用工具检索上下文,确认二人关系;最终回答明确指出:郭靖与杨康是结义兄弟,曾在郭啸天灵前对拜八拜,郭靖年长一月,为兄,杨康为弟。
#### 节点 summarize 处理完毕
--------------------开始新的提问--------------------从上述输出结果可以看出清晰地看出图5-6中每一个节点的执行情况,在两轮交互以后消息数达到了6条(输出结果中的HumanMessage、AIMessage、ToolMessage、AIMessage、HumanMessage 和AIMessage),触发记忆总结节点并得到了总结后的记忆。这里需要注意的是,总结时忽略了工具检索的信息,同时最终输入到大模型中的内容为:
"prompts": ["Human: 郭靖和杨康是什么关系?\nAI: [{'name': 'retrieve_context', 'args': {'query': '郭靖和杨康的关系'}, 'id': 'call_2b276a0c05c246aca725db', }]\nAI: 郭靖和杨康是结义兄弟。两人在郭啸天的灵前对拜八拜,正式结为兄弟,郭靖年长一个月,为兄,杨康为弟。\nHuman: \n请对上方的对话内容生成一段摘要:"]进一步,当我们再次启动程序时并保持 thread_id 不变,此时会输出如下结果:
#服务启动成功!
当前全局记忆状态为:StateSnapshot(values={'messages': [HumanMessage(content='他们两个谁大?', additional_kwargs={}, response_metadata={}, id='4bde66a9-19fc-495d'), AIMessage(content='郭靖比杨康大一个月,因此郭靖是兄长,杨康是弟弟。', 'model_provider': 'openai', 'model_name': 'qwen-plus', 'system_fingerprint': None, 'id': 'chatcmpl-935189c5-c863-90ef', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--019e622c-ae28-7362')], 'summary': '该对话围绕“郭靖和杨康的关系”展开。用户提问后,系统调用工具检索上下文,确认二人关系;最终回答明确指出:郭靖与杨康是结义兄弟,曾在郭啸天灵前对拜八拜,郭靖年长一月,为兄,杨康为弟。'}, next=(), config={'configurable': {'thread_id': 'fd1bd9f0-5d3c-487a-938e-b14513efa48k', 'checkpoint_ns': '', 'checkpoint_id': '1f158ad0-6be5-6466'}}, metadata={'k': 20, 'step': 9, 'top_n': 3, 'source': 'loop', 'parents': {}}, created_at='2026-05-24T02:45:59.091896+00:00', parent_config={'configurable': {'thread_id': 'fd1bd9f0-5d3c-487a-938e-b14513efa48k', 'checkpoint_ns': '', 'checkpoint_id': '1f158ad0-5850-6996'}})
读取到 thread_id=fd1bd9f0-5d3c-487a-938e-b14513efa48k 的短期记忆,共 2 条消息:
01. human: 他们两个谁大?
02. ai: 郭靖比杨康大一个月,因此郭靖是兄长,杨康是弟弟。
------------------------------历史记录已恢复,继续用户会话------------------------------
--------------------开始新的提问--------------------从上述结果可以看出,程序再次运行时首先打印了数据库中保存的最新快照,里面包含了总结后的内容已经余下的两条消息内容。同时,基于此我们还可以再次在这个会话中发起提问。
以上就是拥有短期记忆的 RAG Agent 内容的全部介绍,完整示例代码 Code/Chapter05/C07_custom_rag_agent_memory.py文件,同时强烈建议大家在学习过程中打开 callbacks=[ConsoleCallbackHandler()] ,这样便能够清晰地看到在每一个节点中大模型的输入输出到底是如何拼接的。上面演示过程的输出结果也可参见 Code/Chapter05/C07_custom_rag_agent_memory_output_log.txt 文件。
引用#
[1] https://docs.langchain.com/oss/python/langgraph/add-memory