5.3 短期记忆管理#
理解了短期记忆的底层机制之后,还有一个工程问题不得不面对,那就是对话历史会无限增长但模型的上下文窗口是有限的,这也是我们在第5.2节末尾所提及的问题,也是在实际业务场景中最容易出现的问题。
5.3.1 记忆管理的根源#
在一个对话型应用中,每一轮交互都会产生新的消息——用户说一句,模型回一句,来回往复。最终,这些消息会被依次追加到全局状态的消息列表中,因此随着对话轮次的增加,列表会越来越长。当然,这在短对话中完全不是问题,不过一旦对话持续时间较长,消息列表的词元总量就会持续膨胀,进而带来两类后果。
(1)超出上下文窗口直接报错
每个大模型都有固定的上下文窗口限制(Context Window),例如某些模型是 8K,某些是 128K。当消息列表的总词元数超过这个上限时,模型会直接报错——而且这个错误通常是不可恢复的,只能截断历史或重新开始对话。
(2)即使没超限,效果也会变差
同时,即便模型支持足够长的上下文,随着历史消息越堆越多,模型的实际表现往往会明显下降。原因在于模型容易被早期那些已经过时或与当前问题无关的消息"分散注意力",导致回答质量下降、响应速度变慢,这一点也更隐蔽、更容易被忽视。
总结起来就是,更长的上下文不等于更好的效果,超过一定长度之后冗余的历史消息反而是一种干扰,因此我们需要通过不同的策略来进行处理。在 LangGraph 中提供了3中策略来对短期记忆进行管理,分别是记忆修剪、记忆总结和记忆删除,下面依次进行介绍。
5.3.2 记忆删除#
首先,最简单的一种记忆管理方式就是将历史消息部分或全部删除,只保留一定数量需要的消息内容,如图5-3所示。
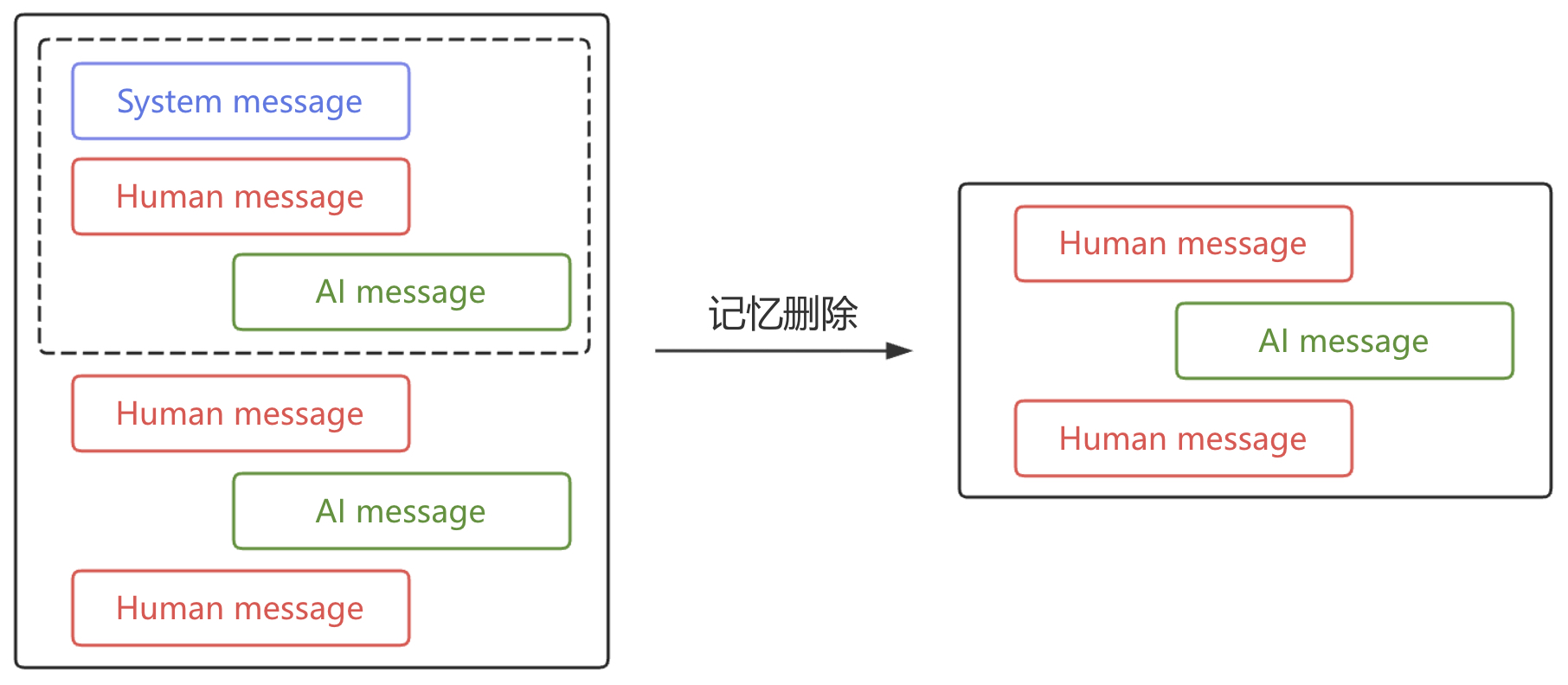
在 LangGraph 中可以通过 RemoveMessage 来根据消息ID将部分或全部记忆进行删除。具体地,先定义一个函数来将待删除的记忆内容置空,示例代码如下:
1 def delete_messages(agent, config: RunnableConfig) -> None:
2 snapshot = agent.get_state(config)
3 messages = snapshot.values.get("messages", []) if snapshot.values else []
4 if len(messages) < 2:
5 print("当前记忆不足 2 条,跳过删除。")
6 return
7 updates = {"messages": [RemoveMessage(id=message.id) for message in messages[:2]]}
8 agent.update_state(config, updates, as_node="generate_answer")
9 print("已删除最前面的两条记忆。")在上述代码中,第3行是获取到快照状态中所有的历史消息。第7行便是构造前两条(最先发生)消息的删除指令。第8行是将待删除的消息更新到状态快照中,即写回 checkpoint 状态里,其中 as_node 的作用是“假装这次更新是由 generate_answer 这个节点产出的”,因为 update_state() 不是单纯改数据库里的一行 JSON,它是按 LangGraph 的图执行模型去改状态的,所以它需要知道要改什么,以及这次修改算哪个节点产生的。
对于 as_node 这个节点的选择没有强制要求,如果不指定则默认会使用图的最后一个节点,但前提是不要有歧义否则会报错。不过建议显示指定图中真实存在的节点名称,例如图4-13中的 decide、my_retrieve、rewrite_question 和 generate_answer。同时,还有一个需要注意的地方是,update_state() 是对 messages 字段进行更新,所以需要选一个本来就返回 {"messages": ...} 的节点,并且从语义上看 generate_answer 更接近“对消息状态做一次人工修正”,所以这里选择了 generate_answer 节点。当然,选择 rewrite_question 也是能正常运行的,但是从执行逻辑上来看最好是 generate_answer 节点,不然状态快照中 next()记录的信息会不符合逻辑。
例如对于如下快照中的6条历史记忆来说:
StateSnapshot(values={'messages': [
HumanMessage(content='郭靖和杨康是什么关系?', , id='31e1f411-8015-4e27'),
AIMessage(content='', id='lc_run--019e2558-e520-7be1', tool_calls=[{'name': 'retrieve_context', 'args': {'query': '郭靖和杨康的关系'}, 'id': 'call_7cdad6b1a9394482846227', 'type': 'tool_call'}]),
ToolMessage(content='杨康边哭边说,涕泪滂沱,断断续续地道:......', name='retrieve_context', id='69d27ef5-2a11-4e2a', tool_call_id='call_7cdad6b1a9394482846227', artifact=),
AIMessage(content='郭靖和杨康是结义兄弟。两人在郭啸天灵前对拜八拜,结为兄弟,郭靖先出世一个月,为兄,杨康为弟。', id='lc_run--019e2558-f1ba-7c42', ),
HumanMessage(content='郭靖比杨康先出生几个月?', , id='e5336c6b-d60f-44bf'),
AIMessage(content='根据提供的文本,郭靖比杨康先出生**一个月**。', id='lc_run--019e2559-4511-7403', )]},
next=(), config={'configurable': {'thread_id': '5', 'checkpoint_ns': '', 'checkpoint_id': '1f14f650-3615-6440'}}, metadata={'k': 20, 'step': 6, 'top_n': 3, 'source': 'loop', 'parents': {}}, created_at='2026-05-17T07:17:49.219715+00:00', parent_config={'configurable': {'thread_id': '5', 'checkpoint_ns': '', 'checkpoint_id': '1f14f650-278b-6c8a'}}, tasks=(), interrupts=())在执行完成 delete_messages 以后将会变成:
StateSnapshot(values={'messages': [
ToolMessage(content='杨康边哭边说,涕泪滂沱,断断续续地道:......', name='retrieve_context', id='69d27ef5-2a11-4e2a', tool_call_id='call_7cdad6b1a9394482846227', artifact=),
AIMessage(content='郭靖和杨康是结义兄弟。两人在郭啸天灵前对拜八拜,结为兄弟,郭靖先出世一个月,为兄,杨康为弟。', id='lc_run--019e2558-f1ba-7c42', ),
HumanMessage(content='郭靖比杨康先出生几个月?', , id='e5336c6b-d60f-44bf'),
AIMessage(content='根据提供的文本,郭靖比杨康先出生**一个月**。', id='lc_run--019e2559-4511-7403', )]}, next=(), config={'configurable': {'thread_id': '5', 'checkpoint_ns': '', 'checkpoint_id': '1f14f650-aa3c-6440'}}, metadata={'k': 20, 'step': 7, 'top_n': 3, 'source': 'update', 'parents': {}}, created_at='2026-05-17T07:18:01.399182+00:00', parent_config={'configurable': {'thread_id': '5', 'checkpoint_ns': '', 'checkpoint_id': '1f14f650-3615-6440'}}, tasks=(), interrupts=())从上述输出结果可以明显看到,前面两条消息已经被删除了。同时,基于此如果用户再次提问“基于当前保留下来的对话记忆,继续回答:郭靖比杨康先出生几个月?” 将会得到回答“郭靖比杨康先出生一个月。”
新一轮对话后的数据库记忆为:
StateSnapshot(values={'messages': [ToolMessage(content='杨康边哭边说,涕泪滂沱,断断续续地道:......', name='retrieve_context', id='69d27ef5-2a11-4e2a', tool_call_id='call_7cdad6b1a9394482846227', artifact=), AIMessage(content='郭靖和杨康是结义兄弟。两人在郭啸天灵前对拜八拜,结为兄弟,郭靖先出世一个月,为兄,杨康为弟。', id='lc_run--019e2558-f1ba-7c42', ), HumanMessage(content='郭靖比杨康先出生几个月?', , id='e5336c6b-d60f-44bf'), AIMessage(content='根据提供的文本,郭靖比杨康先出生**一个月**。', id='lc_run--019e2559-4511-7403', ), HumanMessage(content='基于当前保留下来的对话记忆,继续回答:郭靖比杨康先出生几个月?', , id='c052ef69-9484-4bba'), AIMessage(content='郭靖比杨康先出生**一个月**。', id='lc_run--019e2559-7b45-7282', )]}, next=(), config={'configurable': {'thread_id': '5', 'checkpoint_ns': '', 'checkpoint_id': '1f14f650-bae5-6332'}}, metadata={'k': 20, 'step': 10, 'top_n': 3, 'source': 'loop', 'parents': {}}, created_at='2026-05-17T07:18:03.146080+00:00', parent_config={'configurable': {'thread_id': '5', 'checkpoint_ns': '', 'checkpoint_id': '1f14f650-ab4b-608e'}}, tasks=(), interrupts=())以上完整示例代码可参见 Code/Chapter05/C04_short_memory_delete.py 文件。
5.2.3 记忆修剪#
在介绍完记忆删除这一策略后我们再来看记忆修剪。记忆修剪的思路非常直接,即设定一个数量上限,当消息列表的总 Token 数或者是总消息数接近这个上限时,自动裁剪掉多余的消息,只保留对应的部分。不过虽然可以通过设定 Token 限制来裁剪消息,但是实际上输入模型的 Token 还包括调用工具时的 Schema 信息、Tool ID、Tool Call信息等等,通过 Token 数量来进行记忆修剪并不太直接,因此并更建议使用消息数来进行限制,如图5-4所示。
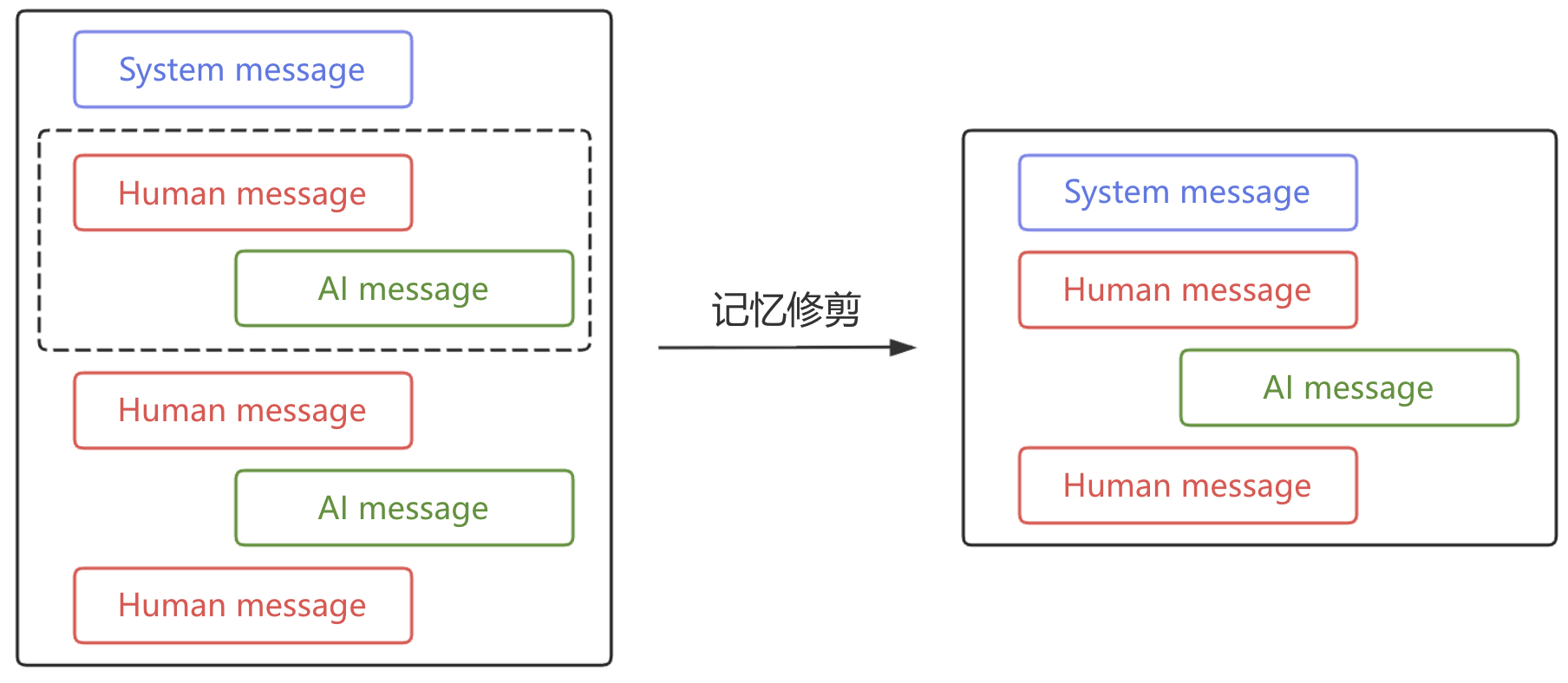
在图5-4中,我们限定了历史消息的数量最多只能保留4条,且系统消息必须始终保留,同时必须以用户请求作为开始。可以看出记忆修剪在一定程度上和记忆删除类似,但是修剪的处理方式显然更加灵活。
在 LangGraph 中可以通过 trim_messages 这个函数来对记忆进行修剪,我们只需要指定两个关键参数,即保留多少的消息数以及保留哪一部分内容即可完成整个过程。下面先来看一段示例代码。
1 if __name__ == '__main__':
2 messages = [
3 SystemMessage(content="你是一个问答助手。"),
4 HumanMessage(content="郭靖是谁?"),
5 AIMessage(content="郭靖是《射雕英雄传》的主角,出生于临安府牛家村。"),
6 HumanMessage(content="他的武功是谁教的?"),
7 AIMessage(content="郭靖先后师从江南七怪和洪七公,后又得到马钰道长的内功传授。"),
8 HumanMessage(content="黄蓉是谁?")]
9 trimmed = trim_messages(messages, max_tokens=4, token_counter=len,
10 strategy="last", start_on="human", end_on=("human", "tool"),
11 include_system=True)
12 for msg in trimmed:
13 print(f"[{msg.type}]: {msg.content}")在上述代码中,第2~8行是模拟的一个交互对话消息列表。第9行trim_messages 便是用于对历史消息进行修剪,其中 max_tokens 用于指定最大 Token 数或历史消息数,取决于参数 token_counter 的设定。例如这里 token_counter=len 时,max_tokens表示最大历史消息数。第10行 strategy="last" 表示修剪时的丢弃策略,有 first 和 last 两种策略,即保留前面 max_tokens 部分还是后面 max_tokens 部分; start_on 和 end_on 分别表示必须以什么样的消息类型开始或结束,为 None 则无此限制。第11行 include_system 表示是否一直保留系统消息,即 SystemMessage。通常来说会将 include_system 设定为 True,因为系统消息中一般会包含固定的指令。
对于上述示例来说一共需要保留4条消息记录,且保留策略为 last,同时除了系统消息外第1条必须为用户提问,因此最终输出结果为:
[system]: 你是一个问答助手。
[human]: 他的武功是谁教的?
[ai]: 郭靖先后师从江南七怪和洪七公,后又得到马钰道长的内功传授。
[human]: 黄蓉是谁?如果此时仅去掉 start_on="human" 的限制,且 max_tokens=2,则输出结果为:
[system]: 你是一个问答助手。
[human]: 黄蓉是谁?以上完整示例代码可参见 Code/Chapter05/C05_shrot_memory_trim.py 文件。
5.2.4 记忆总结#
记忆删除和修剪会直接裁剪掉超出上限的历史消息,这种方式简单直接但也有一个明显的代价,被裁掉的消息就彻底丢失了。如果用户在很早之前提到的信息对当前问题依然重要,模型就再也看不到了,所以需要使用一种更加友好的替代方案,即记忆总结,也叫做消息摘要。
从字面意思可以知道,记忆总结它不是丢弃旧消息,而是把旧消息压缩成一段摘要保留下来,既释放了上下文空间,又没有完全丢失历史信息,它的基本逻辑是当消息列表积累到一定数量时触发一次摘要操作,让模型把当前的历史对话概括成一段文字存入全局状态中,然后删除大部分旧消息,只保留最近若干条内容,如图5-5所示。
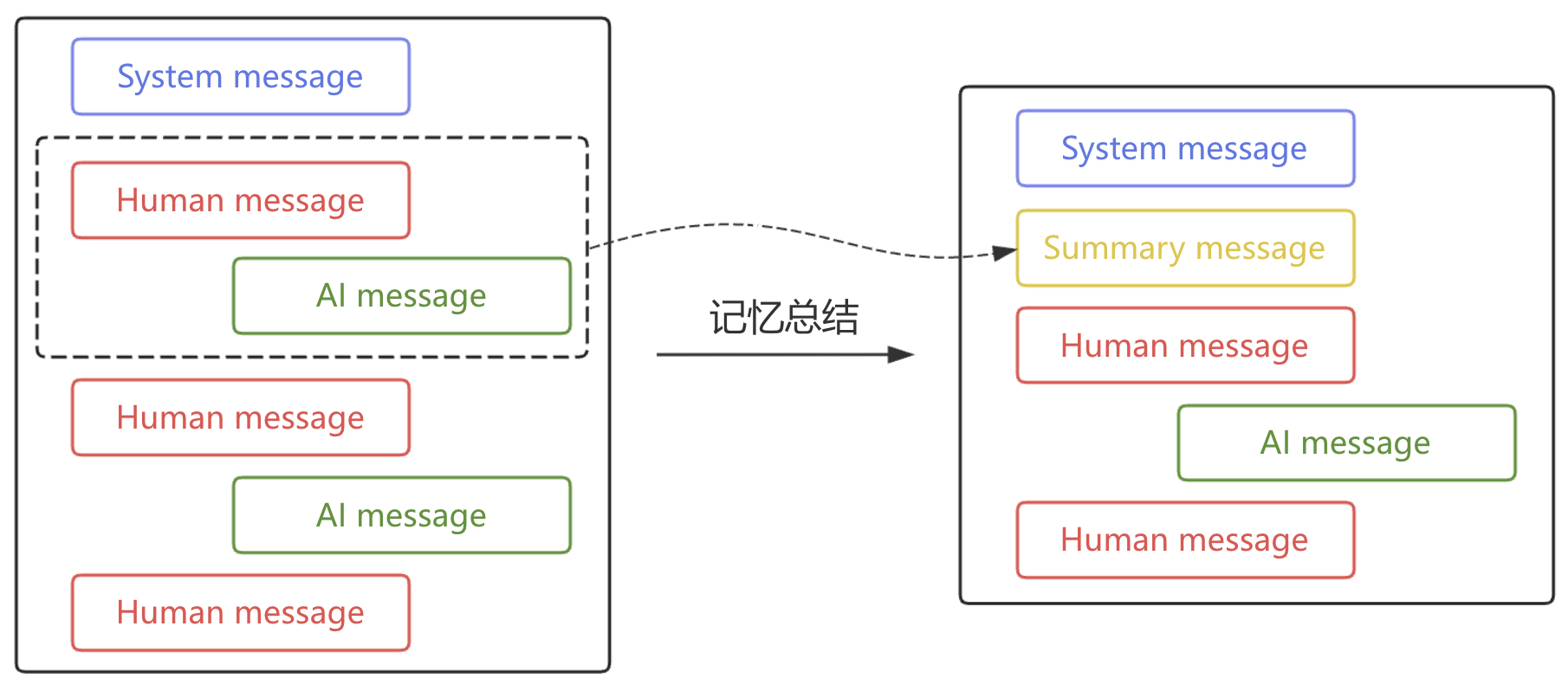
具体地,需要先在全局消息状态 MessagesState 中增加一个 summary 字段,用于保存历史消息的摘要总结,示例代码如下:
1 class State(MessagesState):
2 summary: str # 在 MessagesState 基础上新增摘要字段进一步,专门定义一个图节点来完成记忆总结这部分内容,代码如下:
1 def summarize_conversation(state: State):
2 summary = state.get("summary", "")
3 if summary:
4 summary_message = (
5 f"以下是目前为止对话的摘要:{summary}\n\n"
6 "请结合上方新的对话内容,对摘要进行补充和更新:")
7 else:
8 summary_message = "\n请对上方的对话内容生成一段摘要:"
9 messages = state["messages"][:-2] + [HumanMessage(content=summary_message)]
10 response = get_llm_model().invoke(messages)
11 delete_messages = [RemoveMessage(id=message.id) for message in state["messages"][:-2]]
12 return {"summary": response.content, "messages": delete_messages}在上述代码中,第2行用于取当前节点之前的历史总结内容。第3~8行是根据不同的情况构造提示词。第9~10行是只保留最后两条消息,然后对其余消息进行总结,可以发现每次触发总结时,都会把上一次的总结作为上下文,让模型在此基础上继续扩展,而不是从头重新总结,这种"滚动总结"的设计保证了历史信息不会彻底丢失,同时消息列表的长度始终保持在可控范围内。第11行是标记已经被总结的待删除记忆内容。
接着,可以通过如下方式来测试并验证,代码如下:
1 if __name__ == '__main__':
2 with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
3 ......
4 messages = [
5 SystemMessage(content="你是一个问答助手。"),
6 HumanMessage(content="郭靖是谁?"),
7 AIMessage(content="郭靖是《射雕英雄传》的主角,出生于临安府牛家村。"),
8 HumanMessage(content="他的武功是谁教的?"),
9 AIMessage(content="郭靖先后师从江南七怪和洪七公,后又得到马钰道长的内功传授。"),
10 HumanMessage(content="黄蓉是谁?")]
11 inputs = {"messages": messages}
12 for event in agent.stream(inputs, config=config):
13 for node, update in event.items():
14 print(f"#### 节点 {node} 处理完毕")
15 snapshot = agent.get_state(config)
16 print(f"========== 当前摘要 ==========\n{snapshot.values.get('summary', '')}")
17 print_memory(agent, config, "========== 总结并删除后的数据库记忆 ==========")根据 summarize_conversation 节点中的设定,上面前4条消息会被总结,然后保留最后两条消息在全局状态中。最终,上述代码运行后的出处结果类似如下:
#### 节点 summarize 处理完毕
========== 当前摘要 ==========
对话中,用户首先询问“郭靖是谁”,回答指出他是金庸武侠小说《射雕英雄传》的主角,出生于临安府牛家村;随后用户追问“他的武功是谁教的”,但该问题尚未得到回答。当前对话仅完成前两轮,信息停留在郭靖的身份介绍层面。
========== 总结并删除后的数据库记忆 ==========
snapshot: StateSnapshot(values={'messages': [AIMessage(content='郭靖先后师从江南七怪和洪七公,后又得到马钰道长的内功传授。', id='1e9a444a-ac01-4904'), HumanMessage(content='黄蓉是谁?', id='bfdaca1a-7a7a-44c6')], 'summary': '对话中,用户首先询问“郭靖是谁”...介绍层面。'})
读取到 thread_id=20260519 的短期记忆,共 2 条消息:
01. ai: 郭靖先后师从江南七怪和洪七公,后又得到马钰道长的内功传授。
02. human: 黄蓉是谁?从上述输出结果可以看出,summarize_conversation 节点确实只对前面4条消息进行了总结,同时在全局状态中完整的保留了最近的两条消息记录,以上完整示例代码可参见 Code/Chapter05/C06_shrot_memory_summary.py 文件。
到此,关于短期记忆管理的内容就介绍完了,在下一节内容中将会通过一个完整的示例进行介绍。
引用#
[1] https://docs.langchain.com/oss/python/langgraph/add-memory