5.9 基于 LangGraph 的Mini ChatGPT 助手#
在第5.6节内容中,我们详细介绍了如何基于本地持久化的长期记忆来从零实现一个类似 ChatGPT 的个人助手。不过,从工程实现角度看,第5.6节中的版本更多是手工维护流程:短期记忆需要由程序员自己维护,长期记忆则保存在本地 JSON 文件中,整体更适合理解原理。
进一步,如果希望把这个助手继续扩展为一个更接近实际生产形态的系统,那么仅靠手动拼接消息和手动维护状态的方式就会逐渐暴露出局限。例如,会话状态如何持久化、不同线程之间如何隔离、长期记忆如何统一交给数据库管理,以及工具调用与消息状态如何形成更加稳定的闭环,都会成为新的问题。
为了解决上述问题,接下来我们将借助 LangGraph 来重新实现这一套 Mini ChatGPT 助手。与第5.6节版本相比,这里的核心变化有两个:其一,短期记忆不再由我们手动维护,而是交由 LangGraph 的 Checkpointer 自动管理;其二,长期记忆不再落到本地 JSON 文件,而是迁移到 PostgreSQL,并借助 PostgresStore 完成统一存储与检索。这样一来,我们不仅保留了原有长期记忆、短期记忆、工具写入的整体思路,还进一步获得了更清晰的状态编排能力。
5.9.1 整体设计思路#
首先,长期记忆的定位并没有变化,仍然用于保存用户跨会话共享的稳定信息,例如用户的技术栈、长期目标、持续中的项目以及偏好的回答风格等。这些内容不应绑定在某一次会话中,而应该绑定在用户层面。换言之,只要 user_id 不变,即使用户切换了新的会话线程,系统也仍然应当能够检索到这些历史记忆。
其次,短期记忆的职责也没有变化,仍然用于保存同一轮会话中的上下文消息,以便模型能够理解当前这句回答是在接着前面哪段对话继续。不过在第5.6节中,这部分短期记忆是由 history 列表手动传递和维护的;而在本节中,短期记忆将交由 LangGraph 的 Checkpointer 自动保存,从而让会话上下文状态正式变成图运行过程中的一部分。
最后,整个系统的驱动方式也从手工调用大模型并循环拼接上下文转变为让 LangGraph 统一组织状态、节点与持久化。虽然当前工程中的图结构只有一个核心节点 chat,如图5-12所示,但这个节点已经被放入了标准的 StateGraph 中运行,因此后续如果需要继续扩展出摘要节点、记忆筛选节点、回复评估节点等,也都可以沿着同一套图结构继续增加。
如图5-13所示是从 Agent 节点编排的角度来看的整个图结构。从这个角度看,本节的 Mini ChatGPT 已经不只是有记忆的聊天助手,而是一个真正基于图状态编排的聊天智能体。同时, chat 节点的内部处理流程与图5-11一致,整个工程的目录结构同图5-12一致,这里均不再赘述。
下面,我们将围绕 Code/Chapter05/mini-chatgpt-langgraph 工程中的代码,依旧按照第5.6节中的顺序,逐步介绍这个版本的实现过程。
5.9.2 记忆存储结构改造#
在第5.6节中,长期记忆是通过 JsonMemoryStore 写入本地文件实现的;而在当前 LangGraph 版本中,这部分能力迁移到了 store.py 中定义的 PostgresMemoryStore 类,并统一由 PostgreSQL 承载。
与第5.6节一样,本工程仍然使用 MemoryRecord 和 MemorySearchResult 两个数据结构来分别表示一条记忆以及一条记忆检索结果,略微改动在于 MemoryRecord 中去掉了 embedding 字段,因为记忆向量将被存储到 store_vector 表中,语义检索能力由 PostgresStore 与外部向量索引共同承担,不再需要在业务层显式维护每条记录的向量内容。这部分内容就不再赘述,各位读者直接参见源码即可。
5.9.3 记忆持久化改造#
进一步,需要借助 PostgresStore 来完成持久化长期记忆,并同样实现插入记忆、更新记忆、保存记忆等功能。这里依旧主要介绍其中核心的3个方法, list_memories、upsert 和search ,分别用来返回当前用户的所有记忆、插入或更新记忆以及根据当前用户请求搜索与之相关的记忆内容,其它功能实现可直接阅读工程代码注释,对应模块为 store.py。同时,由于短期记忆的持久化 PostgresSaver 会自动完成,详见第5.3内容,这里不再赘述。
(1)列出当前所有记忆
这里通过定义一个 PostgresMemoryStore 类以及对应的成员方法来完成上述功能。首先定义初始化方法和读取现存所有记忆的方法,示例代码如下:
1 class PostgresMemoryStore:
2 def __init__(self,store: PostgresStore, memory_root: str):
3 self.store = store
4 self.memory_root = memory_root
5
6 def get_namespace(self, user_id: str) -> tuple[str, str]:
7 return self.memory_root, user_id
8
9 def list_memories(self, user_id: str) -> list[MemoryRecord]:
10 namespace = self.get_namespace(user_id)
11 records, offset, page_size = [], 0, 100
12 while True:
13 items = self.store.search(namespace, limit=page_size, offset=offset)
14 if not items:
15 break
16 for item in items:
17 record = self._item_to_record(item)
18 if record:
19 records.append(record)
20 if len(items) < page_size:
21 break
22 offset += page_size
23 records.sort(key=lambda record: record.updated_at, reverse=True)
24 return records在上述代码中,第6~7行是为了实现不同用户长期记忆彼此隔离,通过命名空间对长期记忆进行组织,这样设计以后,只要 user_id 不同,即使多个用户都连接到同一个 PostgreSQL 实例,也会落在不同的命名空间下;而当同一个用户开启多个会话时,由于 user_id 没有变化,因此仍然可以共享同一份长期记忆。
第9~24行是根据传入的 user_id 来获取该用户的所有长期记忆,其中第12~22行是循环从表 store 中每次读取100条记录直到结束,第16~19行是将其转换成 MemoryRecord 的记忆格式,第23行是将最后的结果以更新时间降序排列返回。
(2)更新或插入新记忆
进一步,系统还需要具备长期记忆的插入与更新能力,核心代码如下:
1 def upsert(self, user_id: str, content: str, context: str,
2 *, memory_type: MemoryType = "semantic",
3 memory_id: str | None = None,
4 source_thread_id: str | None = None) -> MemoryRecord:
5 normalized_memory_type = self._normalize_memory_type(memory_type)
6 namespace = self.get_namespace(user_id)
7 content, context = content.strip(), context.strip()
8 now = datetime.now().isoformat(timespec="seconds")
9 existing = self._find_existing(namespace, content, memory_id)
10 record_id = existing.memory_id if existing else str(uuid.uuid4())
11 created_at = existing.created_at if existing else now
12 value = {"memory_id": record_id, "memory_type": normalized_memory_type,
13 "content": content, "context": context, "source": "chat",
14 "source_thread_id": source_thread_id, "created_at": created_at,
15 "updated_at": now}
16 self.store.put(namespace, record_id, value)
17 return MemoryRecord(memory_id=record_id, content=content,
18 context=context, created_at=created_at, updated_at=now,
19 memory_type=normalized_memory_type)在上述代码中,第9行 _find_existing() 会先尝试判断当前内容是否对应已有记忆,或者是否显式传入了旧的 memory_id。如果命中已有记忆,则第10~11行会保留旧的 memory_id 与 created_at,只更新内容和更新时间;如果没有命中,则为新的记忆生成新的memory_id 与 created_at。第12~16行是将这条记忆插入到表 store 中。
这里与第5.6节相比,最大的变化在于第16行。之前我们是将整个用户记忆列表重新落盘到本地 JSON 文件;而现在则是直接通过 self.store.put() 把结构化字典写入到数据库。这样不仅使记忆存储更加稳定,也为后续分页、检索、删除和多端共享提供了基础。同时,在第14行中还加入了记忆产生的原始会话标识 source_thread_id,便于记忆溯源。
最后,当一条记忆通过 store.put() 被插入到数据库以后,记忆文本将出现在 store 表中,格式类似如下:
prefix | key | value |created_at|updated_at|expires_at|ttl_minutes
-----------+------+-------------------------+----------+----------+----------+-----------
memory.user|e99...|{"content":"用户最..",...}|2026-06...|2026-06...| NULL | NULL
memory.user|6ad...|{"content":"2026-..",...}|2026-06...|2026-06...| NULL | NULL记忆向量将出现在 store_vector 表中,格式类似如下:
prefix | key |field_name| embedding |created_at|updated_at
-----------+------+----------+-----------------+----------+-----------
memory.user|e99...| content |[-0.013,0.034...]|2026-06...|2026-06...|
memory.user|e99...| context |[-0.025,0.017...]|2026-06...|2026-06...|
memory.user|6ad...| content |[-0.022,0.012...]|2026-06...|2026-06...|
memory.user|6ad...| context |[-0.073,0.014...]|2026-06...|2026-06...|因为一条记忆中有 content 和 context 两个字段的文本,所以在 store_vector 表中一条记忆对应两行记录。
(3)检索已有记忆
进一步,需要实现根据用户请求检索长期记忆的能力,示例代码如下:
1 def search(self, user_id: str, query: str,
2 limit: int = 12) -> list[MemorySearchResult]:
3 results: list[MemorySearchResult] = []
4 namespace = self.get_namespace(user_id)
5 items = self._search(namespace, query, limit)
6 if not items:
7 return results
8 for item in items:
9 record = self._item_to_record(item)
10 if record:
11 results.append(MemorySearchResult(record=record,
12 score=float(getattr(item, "score", 0.0) or 0.0)))
13 results.sort(key=lambda item: (item.score, item.record.updated_at),
14 reverse=True)
15 return results在上述代码中,第5行 _search() 是交由底层 PostgresStore 执行检索,具体过程可以参见上一节内容中的介绍。第8~12行是将底层检索结果重新规整为 MemorySearchResult。最后,第13~14行按照相似度优先、更新时间次之的规则对结果进行排序并返回。
有了记忆的检索结果,这意味着当用户发来新的问题时,系统可以先在其长期记忆中搜索最相关的若干条内容,再将这些内容组织成系统提示词的一部分注入给模型。这样模型在回答时就能够同时理解用户当前问题与用户过往背景之间的关系。
(4)记忆插入工具改造
对于记忆插入及更新工具的定义整体上与之前5.6节中介绍的一致,对应模块为 tools.py,这里也不再赘述。
5.9.4 Agent 智能体节点实现#
在完成长期记忆存储与工具封装以后,接下来就需要真正把这些能力放进 LangGraph 节点中运行。当前工程的核心节点是 agent.py 中定义的 chat() 方法,示例代码如下:
1 def chat(state: MessagesState, runtime: Runtime[Context]) -> MessagesState:
2 user_text = state["messages"][-1].content
3 memory_store = PostgresMemoryStore(runtime.store, runtime.context.memory_root)
4 memory_hits = memory_store.search(runtime.context.user_id, user_text)
5 system_prompt = SYSTEM_PROMPT.format(user_info=_format_memories(memory_hits),
6 time=datetime.now().isoformat(timespec="seconds"))
7 messages: list[BaseMessage] = [
8 SystemMessage(content=system_prompt),*state["messages"]]
9 tool = build_postgres_memory_tool(memory_store, runtime.context)
10 runnable = load_chat_model(runtime.context.model).bind_tools([tool])
11 for _ in range(5):
12 ai_message = runnable.invoke(messages)
13 messages.append(ai_message)
14 tool_calls = getattr(ai_message, "tool_calls", []) or []
15 if not tool_calls:
16 return {"messages": [AIMessage(content=message_text(ai_message))]}
17 for tool_call in tool_calls:
18 result = tool.invoke(tool_call["args"])
19 messages.append(ToolMessage(content=result, tool_call_id=tool_call["id"]))
20 return {"messages": [AIMessage(content="本轮记忆工具调用次数过多,已停止继续执行。")]}上述代码的组织逻辑同第5.6节中 respond() 函数一只,都是图5-11中用户输入内容与大模型多次交互的过程。具体地说,第2行获取用户当前输入。第3~4行构造长期记忆存储对象并检索与当前输入最相关的历史记忆。第5~6行将这些记忆格式化后填入系统提示词中。第7~8行再把系统提示词与当前会话中的消息状态拼接起来,形成真正发给模型的上下文内容。
进一步,第9~10行将长期记忆写入工具绑定到模型上。这样模型在回答之前,就可以根据系统提示词和当前输入自行判断是否需要调用 upsert_memory。如果模型没有触发任何工具调用,那么第15~16行直接返回最终回答;如果模型触发了工具调用,那么第17~19行就会执行工具,并把工具执行结果包装成 ToolMessage 继续追加到消息序列中,再由下一轮模型继续调用处理。
这里的 for _ in range(5) 与第5.6.6节中对应的部分一样,也是 ReAct 范式的实现过程,只不过现在这个循环发生在 LangGraph 节点内部,并且每一次中间结果都被组织成 LangGraph 认可的消息类型,包括 SystemMessage、AIMessage 和 ToolMessage。这意味着整个状态演化过程不再只是普通字符串拼接,而是一个具备明确语义的消息流。
5.9.5 Agent 工作流构建#
在有了节点函数以后,还需要把它真正组织成一个图。当前工程在 agent.py 模块中的 get_workflow() 里完成了这一步,示例代码如下:
1 def get_agent(checkpointer: PostgresSaver, store: PostgresStore):
2 agent = StateGraph(MessagesState, context_schema=Context)
3 agent.add_node("chat", chat)
4 agent.add_edge(START, "chat")
5 agent.add_edge("chat", END)
6 return agent.compile(checkpointer=checkpointer, store=store)在上述代码中,第2行表示当前这张图使用 MessagesState 作为全局状态结构,同时允许在运行时额外接收一个 Context 类型的上下文对象。第3~5行定义了一条最简单的执行路径,即从 START 进入 chat,处理结束以后直接到 END。
从图结构上看,这似乎只是一个非常简单的单节点流程,但它已经从一个普通的聊天程序升级成了一个可以持续扩展的图工作流。
5.9.6 LangGraph 中的运行时介绍#
为了便于后续图结构实现的介绍,这里先简单介绍一下 LangGraph 中的运行时机制(Runtime)。在 LangGraph 中,运行时可以理解为 Graph 执行期间的上下文环境和系统能力入口,它负责把图运行所需的配置、上下文对象以及运行控制能力传递给节点,而不需要把这些内容塞进全局状态中。
假设有这样一个 State:
1 class State(TypedDict):
2 question: str
3 answer: str从业务视角来看,State 只应该保存业务数据,但节点执行时往往还需要当前用户ID、当前会话ID、数据库连接、Redis连接、vector store以及当前运行配置等,这些内容显然不属于业务状态。如果全部放进 State 将会导致 State 变得臃肿,并且可能无法序列化、Checkpoint 保存异常、业务数据与运行环境耦合等,而运行时正式为解决这一问题而诞生的。同时,LangGraph 为了进一步区分配置信息,又单独拆分了一个可运行配置(RunnableConfig)。
下面,通过一个简单的示例来进一步说明。首先,定义 State 、数据库连接以及上下文结构示例代码如下:
1 class State(TypedDict):
2 input: str
3 results: str
4
5 class DBConnector:
6 def __init__(self, db_name: str = None):
7 self.db_name = db_name
8
9 @dataclass
10 class Context:
11 user_id: str = "default"
12 db_connector: DBConnector = None在上述代码中,第1~3行定义了用于业务处理的状态结构。第5~7行定义了数据库连接。第9~12行则是定义了上下文内容。
进一步,定义一个图节点,来试下业务逻辑,示例代码如下:
1 def my_node(state: State, config: RunnableConfig, runtime: Runtime):
2 thread_id = config["configurable"]["thread_id"]
3 user_id = runtime.context.user_id
4 db_name = runtime.context.db_connector.db_name
5 result = {"results": f"Hello, {state['input']}, I am {user_id} in "
6 f"thread {thread_id}, db_name = {db_name} !"}
7 return result在上述代码中,我们模拟了各种情况下变量的获取,可以看到所有的上下文内容都是通过运行时 runtime 来获取的。
最后,通过如下代码来运行:
1 if __name__ == '__main__':
2 builder = StateGraph(State, context_schema=Context)
3 builder.add_node("my_node", my_node)
4 builder.add_edge(START, "my_node")
5 graph = builder.compile()
6 config = RunnableConfig(configurable={"k": 20, "top_n": 3,
7 "thread_id": "fd1bd9f0-5d3c-487a-938e-b14513efa48k"})
8 context = Context(user_id='demo_user', db_connector=DBConnector('my_database.db'))
9 r = graph.invoke({"input": "Everyone"}, config=config, context=context)在上述代码中,第2行代码中 context_schema 是申明上下文的结构。第6~8行分别定义了可运行配置和运行时上下文,并通过第9行代码注入到图结构中。
这种设计的意义在于,LangGraph 负责管理图执行本身的状态,而我们则通过 Context 把用户、模型和记忆命名空间等业务信息显式注入进去。这样既保留了图运行的规范性,也保证了业务逻辑足够清晰。
不过有读者可能会奇怪,上面第9行中明明是 context=context 为什么在 my_node 节点中却是通过 runtime.context 来获取上下文的。因为 invoke() 的参数并不是简单地一一映射到节点函数参数上,context 是传给 LangGraph 节点的运行时上下文,它不会直接变成节点函数里的 context 参数,而是 LangGraph 在执行节点时会自动构造一个 Runtime 对象,并把 context 放进去。因此,这个 runtime 可以理解成一个运行时容器,里面包含多种运行时资源,例如 PostgresStore 对应的 store 对象也可以通过 runtime.store 来获取,这些都是 LangGraph 自动完成注入的。
上述代码运行结束后,将会得到如下结果:
{'input': 'Everyone', 'results': 'Hello, Everyone, I am demo_user in thread fd1bd9f0-5d3c-487a-938e-b14513efa48k, db_name = my_database.db !'}上述完整代码可参见 Code/Chapter05/C12_config_context.py 文件。
到此对于 LangGraph 中的运行时就介绍完了,不过有印象的读者可能还记得在前面两章的 RAG 语义检索中,我们是直接将 Milvus() 返回的语义检索类对象 vector_store 放到 config 中的,即
1 config = {"configurable": {"vector_store": vector_store, "k": k,"top_n": top_n}}这是因在只有 LangGraph 中的图节点才同时支持动态注入 config 和 context ,而在使用 @tool 来定义工具时只支持注入config 这一种类型,因此在工具中需要同时使用到配置相关参数及各类资源对象时,更建议使用第5.6节中介绍的工具定义方式。
5.9.7 运行时上下文结构定义#
在基于 LangGraph 组织整个流程之前,首先需要明确哪些信息属于图运行时的上下文。在当前工程中,这部分内容通过 context.py 中定义的 Context 类来统一表示,示例代码如下:
1 @dataclass(kw_only=True)
2 class Context:
3 user_id: str = "default"
4 model: str = field(default="qwen-plus", ...)
5 thread_id: str = field(default="demo_user_001", ...)
6 memory_root: str = field(default="demo_memory_root", ...)在上述代码中,第5行 thread_id 表示每个会话对应的会话 ID ,PostgresSaver 会根据 thread_id 将短期记忆进行持久化,因此,同一个用户可以拥有多个不同的 thread_id,这些线程之间共享长期记忆,但彼此拥有独立的短期上下文,详见第5.3节内容。
进一步,在真正调用 Agent 时将会通过如下方式来组装输入及上下文,见 agent.py 模块,示例代码如下:
1 def invoke_agent(agent, user_id: str, thread_id: str,
2 user_text: str, model: str, memory_root: str) -> str:
3 input_data = {"messages": convert_to_messages(
4 [{"role": "user", "content": user_text}])}
5 config = RunnableConfig({"configurable": {"thread_id": thread_id}})
6 result = agent.invoke(input_data,config=config,
7 context=Context(user_id=user_id,thread_id=thread_id,
8 model=model,memory_root=memory_root))
9 return result["messages"][-1].content从上述代码可以看出,第5行是通过可运行配置 RunnableConfig 将 thread_id 传入到节点中。第6~8行构造的 Context 则是提供给业务逻辑使用的运行时上下文,后续节点函数可以通过 runtime.context.user_id、runtime.context.thread_id 等方式直接访问这些信息。
5.9.8 长短期记忆的协同#
理解这个工程最关键的一点,在于分清楚短期记忆和长期记忆分别由谁管理,以及它们如何共同作用。在 main.py 中,我们通过如下方式初始化运行环境:
1 def main() -> None:
2 args = build_parser().parse_args()
3 memory_index = get_memory_index()
4 with (PostgresStore.from_conn_string(DB_URI, index=memory_index) as store,
5 PostgresSaver.from_conn_string(DB_URI) as checkpointer):
6 agent = get_agent(checkpointer, store)
7 memory_store = PostgresMemoryStore(store, args.memory_root)
8 if args.cli or not STREAMLIT_AVAILABLE:
9 run_cli(agent, memory_store, args, checkpointer)
10 else:
11 run_streamlit_app(agent, memory_store, args, checkpointer)在上述代码中,第4行的 PostgresStore 负责长期记忆,第5行的 PostgresSaver 负责图运行过程中的状态检查点,即短期记忆。两者虽然都落在 PostgreSQL 中,但职责完全不同。这样设计以后,同一个用户在多个线程中的聊天内容可以共享长期记忆;而不同用户即使使用同一个系统,也不会互相污染彼此的数据。
第6行是返回定义的 Agent 工作流。第7行是得到实例化的长期记忆存储器 memory_store。第8~11行分别提供了命令行交互以及网页端交互的两种运行方式,相关介绍可以直接参见源码注释。
5.9.9 服务运行及验证#
(1)命令行模式
命令行主流程位于 cli.py 中。在程序启动时,系统会显示当前用户 ID、当前会话 ID、模型名称以及当前命名空间等信息;在运行过程中还支持若干管理命令。对于命令行模式来说,通过终端进入到目录 Code/Chapter05/mini-chatgpt-langgraph 以后,可通过如下方式启动服务:
(rag) wangcheng@Cheng mini-chatgpt-langgraph % python main.py --cli
========== Mini ChatGPT(Postgres存储长期记忆)==========
用户ID = demo-user2
会话ID = 3869e1ed-fe45-410e-aada-dfe370990894
模型 = qwen-plus
记忆命名空间 = ('demo_memory', 'demo-user')
已存储记忆数量 = 0
Commands: /new 新会话, /thread <id> 切换会话, /memories: 查看当前用户所有长期记忆,
/clear: 清空当前用户所有长期记忆, /clearall: 清空用户所有记忆, /exit: 退出, /help: 查看帮助(2)页面模式
除命令行以外,工程还在 streamlit.py 中提供了一个简单的页面版本。其核心思路是把 thread_id、消息列表和 user_id 保存在 Streamlit 的会话状态中,然后每次用户输入新消息时都调用 invoke_agent() 完成一轮回复。与此同时,页面侧边栏还可以查看当前用户已保存的长期记忆内容。
对于页面模式来说,通过终端进入到目录 Code/Chapter05/mini-chatgpt-langgraph 以后,可通过如下方式启动服务:
(rag) wangcheng@Cheng mini-chatgpt-langgraph % streamlit run main.py
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://192.168.0.109:8501此时可在浏览器中通过上面的链接打开。
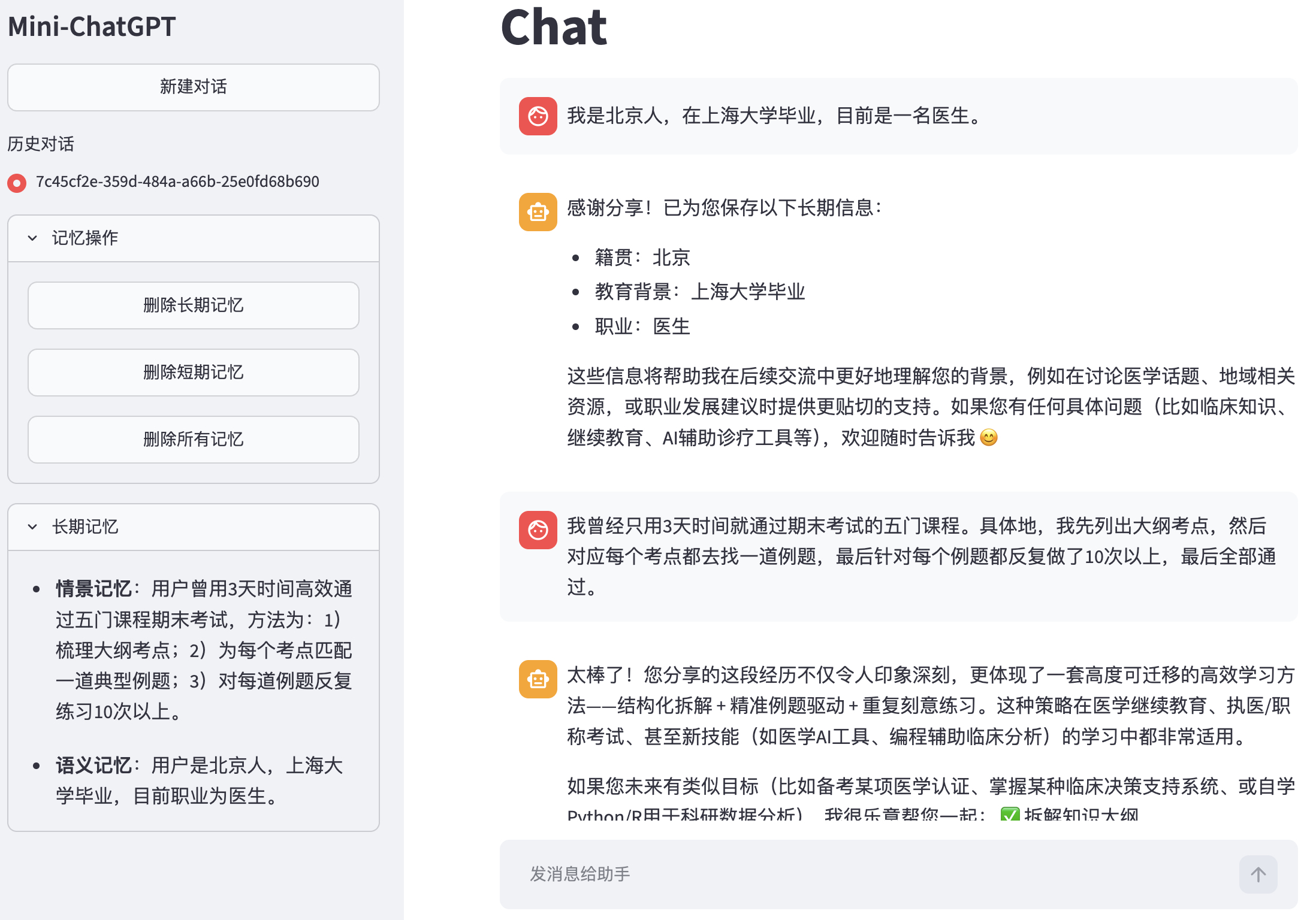
首先,我们在会话 7c45cf2e-35…… 中告诉了智能体一些基本信息,智能体提取后作为记忆进行了保存,如图5-14所示。
接着,新建对话并提问以验证长期记忆的有效性,如图5-15所示。
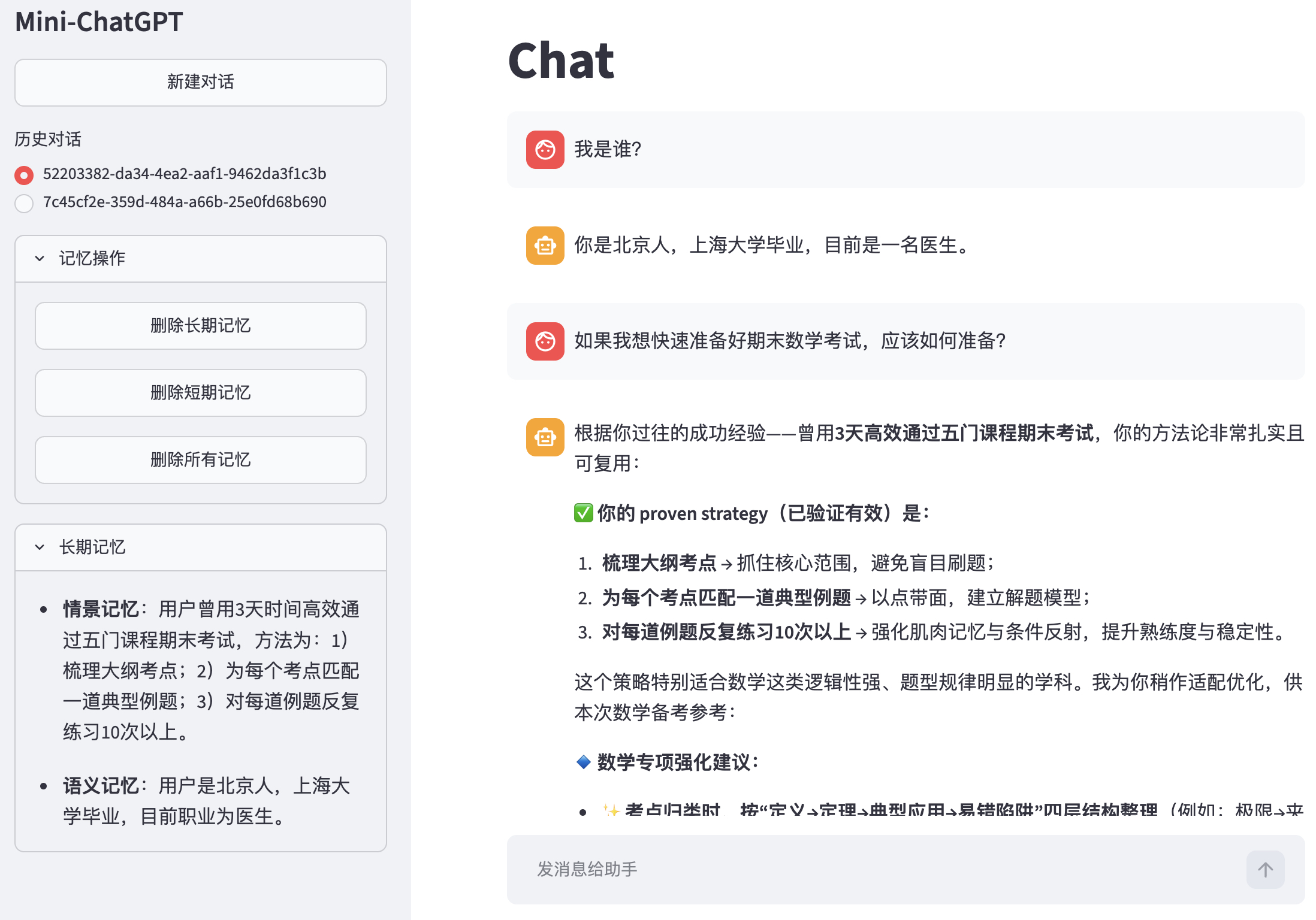
从图5-15可以看出,智能体在回答问题以前的确加入了之前保存的长期记忆。作为验证,各位可以再次新建会话,同时点击左侧”删除长期记忆“按钮,此时再问智能体同样的问题便不会得到类似的答案。
5.9.10 小结#
到此,我们就完成了基于 LangGraph 的 Mini ChatGPT 助手实现。与第5.6节从零手工搭建的版本相比,本节版本的核心提升并不只是把存储从本地文件换成了 PostgreSQL,更重要的是它引入了 LangGraph 的状态图思想,将短期记忆、长期记忆、工具调用以及消息流转组织成了一个更加清晰、可扩展的运行框架。这样一来,系统既保留了 ChatGPT 式的多轮会话体验,又具备了跨会话长期记忆能力。
当然,当前工程仍然只是一个教学性质的简化版本。例如,长期记忆是否写入仍然完全依赖模型判断,记忆去重与冲突解决策略也还较为基础,图结构也只包含了一个核心节点。不过正因为它的结构已经建立在 LangGraph 之上,所以后续无论是加入更复杂的记忆筛选机制,还是继续扩展出多节点工作流,都已经具备了良好的演化基础。