5.6 从零实现 Mini ChatGPT 助手#
在上一节内容中,我们详细介绍了长期记忆的模式、管理和持久化,为了能够更加清晰地理解记忆的运行机制,接下来将会详细介绍如何基于本地持久化的长期记忆来从零构建一个类似 ChatGPT 一样具有用户隔离以及记忆功能的个人助手。
5.6.1 Mini ChatGPT 结构设计#
为了实现和 ChatGPT 类似的效果,我们需要设计长期记忆以实现同一用户的跨会话使用;其次需要加入短期记忆来保证同一会话中的用户上下文不会丢失;最后需要构造一个工具来插入或更新记忆内容。对于整个状态扭转过程中的详细情况,我们可以通过图5-11表示。
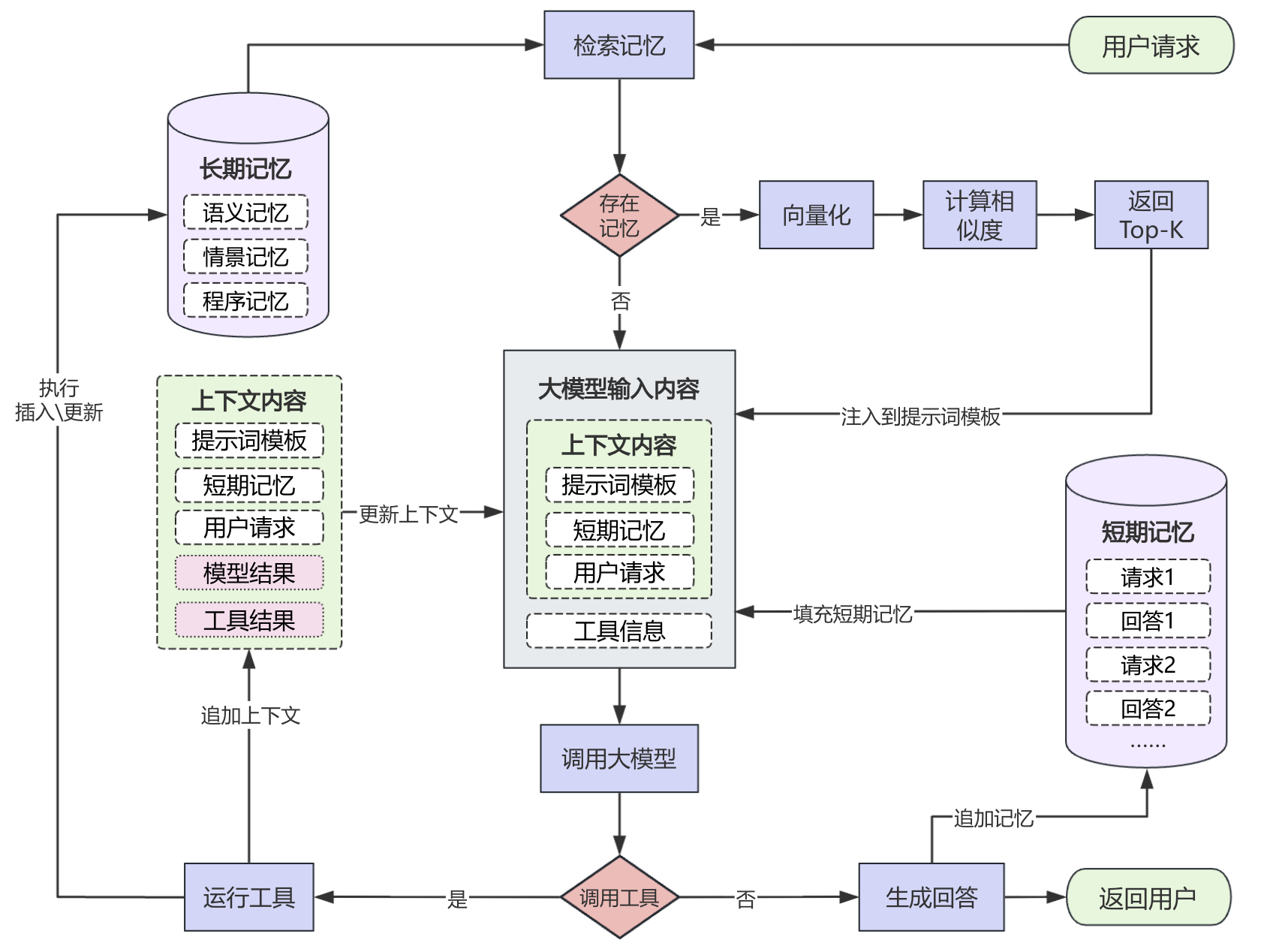
如图5-11所示,左上角和右下角分别对应的是长期记忆和短期记忆,分别作用于不同用户间和同一会话内。当用户发起一个请求后,系统将会判断长期记忆中是否存在该用户的相关记忆,如果存在则根据相似度搜索并返回前 Top-K 的相关记忆,如果不存在则直接进入下一步。进一步,系统会将检索到的用户长期记忆、短期记忆(如果有)以及用户请求内容拼接形成上下问内容,并连同工具信息一起输入到大模型中。最后,系统会根据大模型的返回结果判断是否需要调用工具。如果不需要则直接根据大模型返回内容生成回答并将用户问题和回答追加到短期记忆中;如果需要调用工具则根据大模型提取的参数运行工具,同步更新旧记忆或插入新记忆,再将大模型返回内容和工具运行结果追加到旧的上下文内容中形成新的上下文内容,然后再次发起大模型调用。
5.6.2 工程目录介绍#
下面,根据图5-11所示的过程,来逐一实现。为了使下面的介绍更为清晰,先来简单介绍一个整个工程目录结构,以下完整示例代码可参见 Code/Chapter05/mini-chatgpt 工程。

在图5-12中,main.py 是整个项目的主函数入口,通过 python main.py 启动;cli.py 中定义了整个命令行与用户之间的交互逻辑;agent.py 中定义了用户请求与大模型之间的交互逻辑,即图5-11中间部分;store.py 中定义的记忆的存储结构;tools.py 中定义了工具的逻辑;context.py 和 qwen.py 中分别定义了上下文的字段结构和大模型的加载模块。
5.6.3 记忆存储结构实现#
首先需要定义长期记忆的存储结构以及不同处理情况下的组织结构,这里通过2个类来实现,即 MemoryRecord和MemorySearchResult 分别用来表示一条记忆以及记忆的搜索结果,对应模块为 store.py。
(1)记忆存储结构
1 MemoryType = Literal["episodic", "semantic", "procedural"]
2 @dataclass
3 class MemoryRecord:
4 memory_id: str
5 content: str
6 context: str
7 created_at: str
8 updated_at: str
9 memory_type: MemoryType = "semantic"
10 embedding: list[float] | None = None
11
12 @property
13 def text(self) -> str:
14 return f"{self.memory_type}\n{self.content}\n{self.context}".strip()在上述代码中,第4行 memory_id 表示每一条记忆对应的唯一 ID。第6~7行分别用来记录这条记忆的核心内容以及对应的补充上下文说明。第7~8行分别用来记录这条记忆的创建时间以及后续的更新时间。第9行用来标识长期记忆的类型。第10行用来记录这条记录的词嵌入表示,便于后续对记忆进行检索。第12~14行定义了一个 text 属性,便于后续直接取记忆对应文本内容。
值得一提的是,记忆通常会使用 content 和 context 这两个字段描述,这意味着系统并不是只根据记忆正文做召回,也会综合考虑“这条记忆为什么被记录下来、它的使用背景是什么。这种做法的优点在于,长期记忆的可检索性不再只依赖一句孤立文本,而是让记忆同时带有一定的语境信息。
如下所示,便是一条记忆内容的示例结果:
{"memory_id": "65864dd6-cc5f-4804-8b4d-11f3b3b35548",
"content": "用户住在上海",
"context": "地理位置信息,可能影响后续示例的本地化(如时区、日期格式、生活场景举例等)",
"created_at": "2026-05-31T16:18:04",
"updated_at": "2026-05-31T16:18:04",
"memory_type": "semantic",
"embedding": [-0.0667203739285469, 0.025669077411293983....]}(2)记忆搜索结果结构
进一步,实现搜索记忆时的结果返回类,需包含记忆本身以及与用户请求的相似度值,示例代码如下:
1 @dataclass
2 class MemorySearchResult:
3 record: MemoryRecord
4 score: float在上述代码中,第3行对应一条用户记忆。第4行表示用户请求内容与当前这条用户数据的相似度值。
5.6.4 记忆持久化实现#
在完成单条记忆的结构化实现以后,还需要再实现一个 Json 对象来持久化保存每一个用户的所有长期记忆,以及实现插入记忆、更新记忆、保存记忆以及相似度值计算等功能,对应模块为 store.py。这里主要介绍其中核心的3个方法, list_memories、upsert 和search ,分别用来返回当前用户的所有记忆、插入或更新记忆以及根据当前用户请求搜索与之相关的记忆内容,其它功能实现可直接阅读工程代码注释。同时,为了方便处理短期记忆本示例暂不做本地持久化。
(1)列出当前所有记忆
这里通过定义一个 JsonMemoryStore 类以及对应的成员方法来完成上述功能。首先定义初始化方法和读取现存所有记忆的方法,示例代码如下:
1 class JsonMemoryStore:
2 def __init__(self, base_dir: str | Path, embeddings_model: Any | None = None):
3 self.base_dir = Path(base_dir)
4 self.base_dir.mkdir(parents=True, exist_ok=True)
5 self.embeddings_model = embeddings_model
6
7 def list_memories(self, user_id: str) -> list[MemoryRecord]:
8 path = self._memory_file(user_id)
9 if not path.exists():
10 return []
11 raw = json.loads(path.read_text(encoding="utf-8"))
12 records = []
13 for item in raw:
14 item.setdefault("memory_type", "semantic")
15 item["memory_type"] = self._normalize_memory_type(item["memory_type"])
16 records.append(MemoryRecord(**item))
17 return records在上述代码,第2~3行是指定记忆的存储目录,如果不存在则根据传入的路径 base_dir 创建该目录。第5行是指定后续用到的词嵌入模型。第7行方法 list_memories 便是用来根据传入的 user_id 载入当前用户保存在本地的所有记忆内容。第8行是根据用户ID拼接得到记忆文件的路径。第11~17行是载入当前用户对应的记忆文件(每个用户对应一个),并返回一个列表,其中每个元素则是一条 MemoryRecord 结构的记忆内容。
(2)更新或插入新记忆
进一步,定义记忆的更新或插入方法,示例代码如下:
1 def upsert(self, user_id: str, content: str, context: str, *, memory_type: MemoryType,
2 memory_id: str | None = None) -> MemoryRecord:
3 records = self.list_memories(user_id)
4 now = datetime.now().isoformat(timespec="seconds")
5 record_id = memory_id or str(uuid.uuid4())
6 normalized_memory_type = self._normalize_memory_type(memory_type)
7 embedding = self._embed(f"{content}\n{context}")
8 updated_record = None
9 for index, record in enumerate(records):
10 if record.memory_id != record_id:
11 continue
12 updated_record = MemoryRecord(memory_id=record.memory_id, content=content,
13 context=context, created_at=record.created_at, updated_at=now,
14 memory_type=normalized_memory_type, embedding=embedding)
15 records[index] = updated_record
16 break
17 if updated_record is None:
18 updated_record = MemoryRecord(memory_id=record_id,
19 content=content, context=context, created_at=now, updated_at=now,
20 memory_type=normalized_memory_type, embedding=embedding)
21 records.append(updated_record)
22 self._save(user_id, records)
23 return updated_record在上述代码中,第1行 upsert 方法时根据 user_id 及记忆内容来更新已有记忆或者插入一条新的记忆。第3行是根据 user_id 获取当前用户的所有本地记忆。第5行判断 memory_id 是否为 None,如果为 None 则接下来直接将传入记忆内容作为新的记忆插入;如果不为 None 则表示对以后记忆内容进行更新。第6行是校验得到记忆类型,因为这个记忆类型是模型返回的所以需要校验。第7行得到记忆内容对应的词嵌入表示,需要注意的是这里是将 content 和 context 拼接起来转换成向量的,在后续使用 PostgresStore 时其默认是将两个字段分开处理的。
第9~16行是遍历当前用户所有记忆内容,如果传入的 memory_id 命中已有记忆的 record.memory_id 则通过第12~14行对已有记忆进行更新,并保持 record.memory_id 和 record.created_at 不变。第17~21行判断是否有记忆更新操作,如果没有则作为新记忆插入。第22行是将整个记忆重新保存到本地,最终在 memory-agent 目录下将会生成一个 .memory 的文件夹来保存每个用户的记忆文件。
例如对于 demo-user 用户来说,当与大模型交互多次以后,便会在 .memory 文件夹中生成一个名为 demo-user.json 的记忆文件,内容形式为:
[
{
"memory_id": "65864dd6-cc5f-4804-8b4d-11f3b3b35548",
"content": "用户住在上海",
"context": "地理位置信息,可能影响后续示例的本地化(如时区、日期格式、生活场景举例等)",
"created_at": "2026-05-31T16:18:04",
"updated_at": "2026-05-31T16:18:04",
"memory_type": "semantic",
"embedding": [
-0.0667203739285469,
0.025669077411293983...
},
{
"memory_id": "13903326-25f3-4724-b21e-35b8a143352e",
"content": "有一个好朋友叫张三",
"context": "人际关系信息,可能用于后续个性化举例、故事化解释或社交场景模拟(如协作开发、技术分享、职业建议等)",
"created_at": "2026-05-31T16:26:19",
"updated_at": "2026-05-31T16:26:19",
"memory_type": "semantic",
"embedding": [
-0.05820561200380325,
0.003316354937851429,
}
](3)检索已有记忆
对于本地已有的记忆,我们希望模型在回答用户问题时能够参考,因此实现一个 search 方法来根据用户请求返回与之相关的记忆内容,示例代码如下:
1 def search(self, user_id: str, query: str, limit: int = 5) -> list[MemorySearchResult]:
2 records = self.list_memories(user_id)
3 if not records:
4 return []
5 query_embedding = self._embed(query)
6 scored = [MemorySearchResult(record=record,
7 score=self._score(record, query, query_embedding))
8 for record in records]
9 scored.sort(key=lambda item: item.score, reverse=True)
10 return scored[:limit]在上述代码中,第5行是将用户请求 query 转换为词向量。第6~8行是遍历每一条本地记忆,然后分别计算其与 query_embedding 之间的相似度,其中第7行 _score 方法便是用来计算相似度而之所以还要传入原 query 是当无词嵌入模型使用时则通过比较两段文本之间重复的词元来计算相似度,是一种保底方案。第9~10行则是将记忆内容按相似度由高到低排序并返回前 limit 条记忆内容。
5.6.5 记忆插入工具实现#
在 JsonMemoryStore 中我们实现了记忆的更新或插入方法 upsert,进一步需要将其封装成一个工具来供大模型使用,后续大模型将自动判断是否有新记忆插入或对已存在的记忆更新,对应模块为 tools.py。具体地,示例代码如下所示:
1 def build_upsert_memory_tool(store: JsonMemoryStore,
2 user_id: str) -> StructuredTool:
3 def _upsert_memory(content: str, context: str,
4 memory_type: MemoryType, memory_id: str | None) -> str:
5 record = store.upsert(user_id=user_id, content=content,context=context,
6 memory_type=memory_type,memory_id=memory_id)
7 return f"记忆已经完成存储 {record.memory_id}"
8
9 return StructuredTool.from_function(func=_upsert_memory,
10 name="upsert_memory",description=MEMORY_TOOL_DESCRIPTION,
11 args_schema=UpsertMemoryInput)在上述代码中,build_upsert_memory_tool 便是最后封装得到的工具,其中第10行 MEMORY_TOOL_DESCRIPTION 为工具的描述内容,第11行 UpsertMemoryInput 为工具参数的描述内容。不过上述定义与第4.3节中介绍的方法有很大差异,如果使用 @tool 修饰器来实现,则示例代码如下:
1 @tool(args_schema=UpsertMemoryInput)
2 def upsert_memory(content: str, context: str, memory_type: MemoryType,
3 memory_id: str | None,
4 config: Annotated[RunnableConfig] = None) -> str:
5 """保存或更新用户的长期记忆。仅保存未来仍具有价值的信息,不……"""
6 user_id = config['configurable'].get("user_id")
7 store = config['configurable'].get("store")
8 record = store.upsert(user_id=user_id, content=content, context=context,
9 memory_type=memory_type, memory_id=memory_id)
10 return f"已存储记忆 {record.memory_id}"在上述代码中,由于 store 和 user_id 不是工具参数,所以第7~8行分别通过 config 来进行获取,即第1行的 content、context和 memory_id 才是大模型会解析并传入的3个参数。这种写法也类似于第4.4.3节中定义检索工具 retrieve_context(query: str, config: RunnableConfig) 时的写法。
虽然通过 @tool 也能实现记忆插入工具的封装,但是对于这种运行时才会注入不应该暴露给模型的参数或上下文,更推荐使用上面 build_upsert_memory_tool 这样的封装方式。在使用时,通过 memory_tool = build_upsert_memory_tool(store, context.user_id) 这样的方式来获得工具,然后再绑定到大模型上。
当然,上述两种方式本质上是一样的均可使用,其输出的 tool_schema 并无差异,可运行代码 Code/Chapter05/memory-agent/tests/test_tool.py 进行验证。
5.6.6 Agent 智能体构建#
到此为止我们已经把图5-11中所要用到的核心模块实现完成了,接下来开始构建 Agent 智能体,包括 Agent 响应消息体构建、Agent 响应实现以及 Agent 的创建,对应模块为 agent.py。
(1)响应消息体构建
首先定义一个消息体,它表示每一轮对话的最终产物,示例代码如下:
1 @dataclass
2 class AgentReply:
3 text: str
4 history: list[BaseMessage]
5 used_memories: list[MemorySearchResult]在上述代码,第3行 text 表示最终返回给用户的文本,即回答内容。第4行 history 表示更新后的历史消息(短期记忆),下一轮还会继续用到。第5行 used_memories 表示本轮参与检索并注入给模型的记忆列表(长期记忆)。
(2)Agent 响应实现
进一步,定义类 MemoryAgent 来处理每一轮对话的内部处理流程,包括记忆检索、上下文拼接、多轮交互等。首先定义初始化方法,示例代码如下:
1 class MemoryAgent:
2 def __init__(self, context: Context, store: JsonMemoryStore):
3 self.context = context
4 self.store = store
5 self.llm = load_chat_model(context.model)
6 self.memory_tool = build_upsert_memory_tool(store, context.user_id)在上述代码中,第3行 context 为一个配置类对象,包括 user_id、model、memory_dir 和 system_prompt。第4行 store 为上文定义实现的 JsonMemoryStore 类对象。第5行时载入的大模型。第6行是返回的记忆处理工具。
接着,实现 Agent 最核心的交互部分,核心代码如下:
1 def respond(self, user_message: str, *, history: list[BaseMessage] = None,
2 memory_limit: int = 5, max_loops: int = 5) -> AgentReply:
3 dialogue_history = list(history or [])
4 memory_hits = self.store.search(self.context.user_id,
5 query=user_message, limit=memory_limit)
6 system_prompt = self.context.system_prompt.format(
7 user_info=self._format_memories(memory_hits),
8 time=datetime.now().isoformat(timespec="seconds"))
9 messages: list[BaseMessage] = [SystemMessage(content=system_prompt),
10 *dialogue_history, HumanMessage(content=user_message)]
11 runnable = self.llm.bind_tools([self.memory_tool])
12 for i in range(max_loops):
13 ai_message = runnable.invoke(messages)
14 messages.append(ai_message)
15 tool_calls = getattr(ai_message, "tool_calls", []) or []
16 if not tool_calls:
17 updated_history = [*dialogue_history,
18 HumanMessage(content=user_message),
19 AIMessage(content=self._message_text(ai_message))]
20 return AgentReply(text=self._message_text(ai_message),
21 history=updated_history, used_memories=memory_hits)
22 for tool_call in tool_calls:
23 result = self.memory_tool.invoke(tool_call["args"])
24 messages.append(ToolMessage(content=result, tool_call_id=tool_call["id"]))
25 raise RuntimeError("已达到本轮交互最大次数")在上述代码,第1行 user_message 表示用户当前的输入内容,history 表示交互过程中的会话(短期)记忆初始时为空列表, memory_limit 表示检索用户长期记忆时的最大返回条数,max_loops 表示每一轮对话中与大模型的最大交互次数。第4~8行是根据用户提问检索与之相关的长期记忆,并将其注入到系统提示词中,对应图5-11的右上部分。第9~10行是将系统提示词、短期记忆内容和用户提问拼接在一起形成初始的上下文内容,对应图5-11中间部分。第11行是将记忆检索更新工具绑定到大模型上。
第12行则是开始本轮响应的大模型内部交互过程,因为有些情况下可能需要与大模型交互多次才会得到结果,例如现在大模型对应的思考模式便是这里每一次交互的输出。第13~14行是先根据已有上下文内容发起一次大模型调用,然后将得到的回复追加到上下文中。第15~21行是判断上一次大模型调用是否有触发工具,如果没有则表示本轮响应结束,第17~19行更新得到本轮用户交互后的短期记忆内容,第20~21行是返回本次响应结果。第22~24行是当触发工具时,依次遍历每一个工具取对应参数并运行工具得到结果,并同时将其追加到上下文内容中进入下一次内部交互。整个过程也正是我们在第4.10节介绍的 ReAct 范式的实际体现。
(3)创建 Agent
最后,根据以上实现内容创建 Agent ,示例代码人如下:
1 def create_agent(context: Context) -> MemoryAgent:
2 from .qwen import get_embeddings_model
3 store = JsonMemoryStore(context.memory_dir,
4 embeddings_model=get_embeddings_model())
5 return MemoryAgent(context=context, store=store)在上述代码中,第4行是载入保存长期记忆时的词嵌入模型。第5行是返回 MemoryAgent 实例化类对象。
5.6.7 命令行交互实现#
在完成所有功能模块实现以后,最后再实现一个命令行交互界面通过不同命令完成不同功能,对应模块为 cli.py,示例代码如下:
1 def run_cli() -> None:
2 args = build_parser().parse_args()
3 configure_logging(args.log_level, args.log_file)
4 context = Context(user_id=args.user_id, model=args.model,
5 memory_dir=args.memory_dir)
6 agent = create_agent(context)
7 store = agent.store
8 _print_welcome(context, store)
9 history = []
10 while True:
11 user_text = input("\n[You]: ").strip()
12 if not user_text:
13 continue
14 if user_text == "/exit":
15 break
16 if user_text == "/help":
17 _print_help()
18 continue
19 if user_text == "/memories":
20 _print_memories(store, context.user_id)
21 continue
22 if user_text == "/clear":
23 store.clear(context.user_id)
24 continue
25 reply = agent.respond(user_text, history=history)
26 history = reply.history
27 logger.info(f"[Assistant]:\n {reply.text}")在上述代码,第2行是解析从命令行传入的参数。第3行是配置日志打印模块,如果需要查看每一步的详细信息可将 log_level 设置为 DEBUGE 模式。第4~6行则是根据参数创建一个 Agent 智能体。第10~27行则是循环与用户输入进行交互。
最后,通过命令行进入到目录 Code/Chapter05/mini-chatgpt中,然后通过如下命令启动整个服务:
(rag) wangcheng@Cheng mini-chatgpt % python main.py
========== Mini ChatGPT(本地存储长期记忆)==========
用户ID = demo-user
模型 = qwen-plus
记忆目录 = .memory
已存储记忆数量 = 2
Commands: /help: 查看帮助 /memories: 查看当前用户所有长期记忆 /clear: 清楚当前用户所有长期记忆 /exit: 退出
[You]: 从当前提示可以看到,本地已经储存有两条记忆信息,并且可以通过命令 /memories 查看:
[You]: /memories
已保存记忆:
1. [semantic / 语义记忆] 用户籍贯为四川,当前常居地为上海 | 用户的地理背景信息,可能影响后续对地域相关话题(如饮食、方言、政策等)的交流
2. [episodic / 情景记忆] 用户曾用5天完成聊天机器人搭建,流程包括:梳理逻辑→绘制结构图→编码实现→调试/注释/修bug→发布 | 体现用户的项目执行能力、结构化思维和工程实践习惯,属于具体的一次性项目经历
[You]: 进一步,可直接输入相关内容与其进行交互,如果识别到新的记忆内容,也会进行保存:
[You]: 我有一个朋友叫张三,他是北京人,我们是大学同学。对了,今天北京天气怎么样?
有 1 条记忆插入
[Assistant]:
已为你保存这条语义记忆:
✅ 朋友张三,北京人,与你是大学同学。
这有助于我未来更自然地理解你们之间的关系背景(比如聊到母校、北京生活、学生时代等话题时)😊
至于**今天北京的天气**——虽然我无法实时联网查询......
欢迎告诉我你的偏好~ 🌤️
----------------------------------------------------------------------
[You]: 根据上述内容可以看出,用户的输入包含有记忆相关内容,智能体对其进行了保存,同时也输出了与北京天气相关的内容。此时,可以再次查看当前保存的记忆内容:
[You]: /memories
已保存记忆:
1. [semantic / 语义记忆] 用户籍贯为四川,当前常居地为上海 | 用户的地理背景信息,可能影响后续对地域相关话题(如饮食、方言、政策等)的交流
2. [episodic / 情景记忆] 用户曾用5天完成聊天机器人搭建,流程包括:梳理逻辑→绘制结构图→编码实现→调试/注释/修bug→发布 | 体现用户的项目执行能力、结构化思维和工程实践习惯,属于具体的一次性项目经历
3. [semantic / 语义记忆] 朋友张三,北京人,与用户是大学同学 | 属于用户长期人际关系信息,可能影响后续对话中对共同经历、地域背景或社交场景的理解到此,对于整个 Mini ChatGPT 的实现及使用方法就介绍完了,后续我们将再介绍如何基于 LangGraph 和 Postgres 数据库来实现整个过程。