5.5 长期记忆管理与持久化#
在前面几节内容中我们介绍了短期记忆的底层机制以及消息列表的管理策略。从本节开始,我们将把目光转向长期记忆——它解决的是一个短期记忆根本无法触及的问题——如何让 Agent 在不同的对话会话之间也能记住用户。为了能更加深刻地理解长期记忆,下面我们先来看人类是如何描述长期记忆的。
5.5.1 人类的长期记忆模式#
人类的记忆像是一个包罗万象的信息库,自然而然描述记忆的方式就多种多样。尽管研究者们对不同记忆类型的描述并非总是相同,但一些关键概念已经逐渐形成共识。在日常生活中各种形式的记忆有时会相互重叠,因此也被归纳为几大类。持续时间很短的记忆可以称为短期记忆,这个我们在前面的内容中已经介绍过,而任何被保存下来以便日后回忆的信息都可以称为长期记忆。对于人类的长期记忆来说,主要可以分为如下3个类别:
(1)情景记忆
当一个人回忆起过去经历的某个特定事件(或“片段”)时,这就是情景记忆(Episodic Memory)。这种长期记忆能够唤起人们对各种细节的关注,从小时候的特殊经历到二十分钟前与人交谈时的感受等等,它可以是近期发生的也可以是几十年前的。
(2)语义记忆
语义记忆(Semantic Memory)是人们长期储存知识的一种方,它由各种信息组成,例如在学校学到的事实、概念的含义及其相互关系或者某个特定词语的定义等,例如现在是哪一年、中国的首都是哪里、“机器学习”的含义是什么。
(3)程序性记忆
程序性记忆(Procedural Memory)指的是对如何做事(包括生理和心理方面)的长期记忆,它参与了技能学习的过程,包括从习以为常的基本技能到需要大量练习才能掌握的技能。例如多年未骑自行车后,再次坐上车却能立刻想起该怎么做,这就是程序性记忆的典型例子。
5.5.2 智能体认知架构#
与短期记忆按 thread_id 隔离不同,长期记忆存储在自定义命名空间下,它可以跨任意会话被读取和写入。不过,长期记忆的设计没有放之四海而皆准的标准答案,所以,在动手实现之前通常需要先回答两个问题,即“要存什么类型的记忆?” 和“什么时候写入记忆? ”。这两个问题的答案决定了整个长期记忆系统的架构设计。
LangGraph 在设计 Agent 的记忆系统时,借鉴了心理学对人类记忆的分类方式。根据存储内容的不同,长期记忆可以分为3种类型,如表5-1所示。
| 记忆类型 | 存储内容 | 人类类比 | Agent 应用场景 |
|---|---|---|---|
| 语义记忆 | 事实与知识 | 课堂上学到的知识 | 用户偏好、个人信息、事实陈述等 |
| 情景记忆 | 经历与事件 | 做过的事情 | 过去执行过的操作和案例等 |
| 程序记忆 | 规则与指令 | 骑自行车的肌肉记忆 | Agent 的系统提示词、代码逻辑、模型权重等 |
从表5-1可以看出,语义记忆、情景记忆和程序记忆这样的类型划分方式,恰好也能够满足对于智能体长期记忆的归纳和管理,而采用这样的架构设计也被称之为语言智能体认知架构(Cognitive architectures for language agents, CoALA)[2],如图5-7所示。
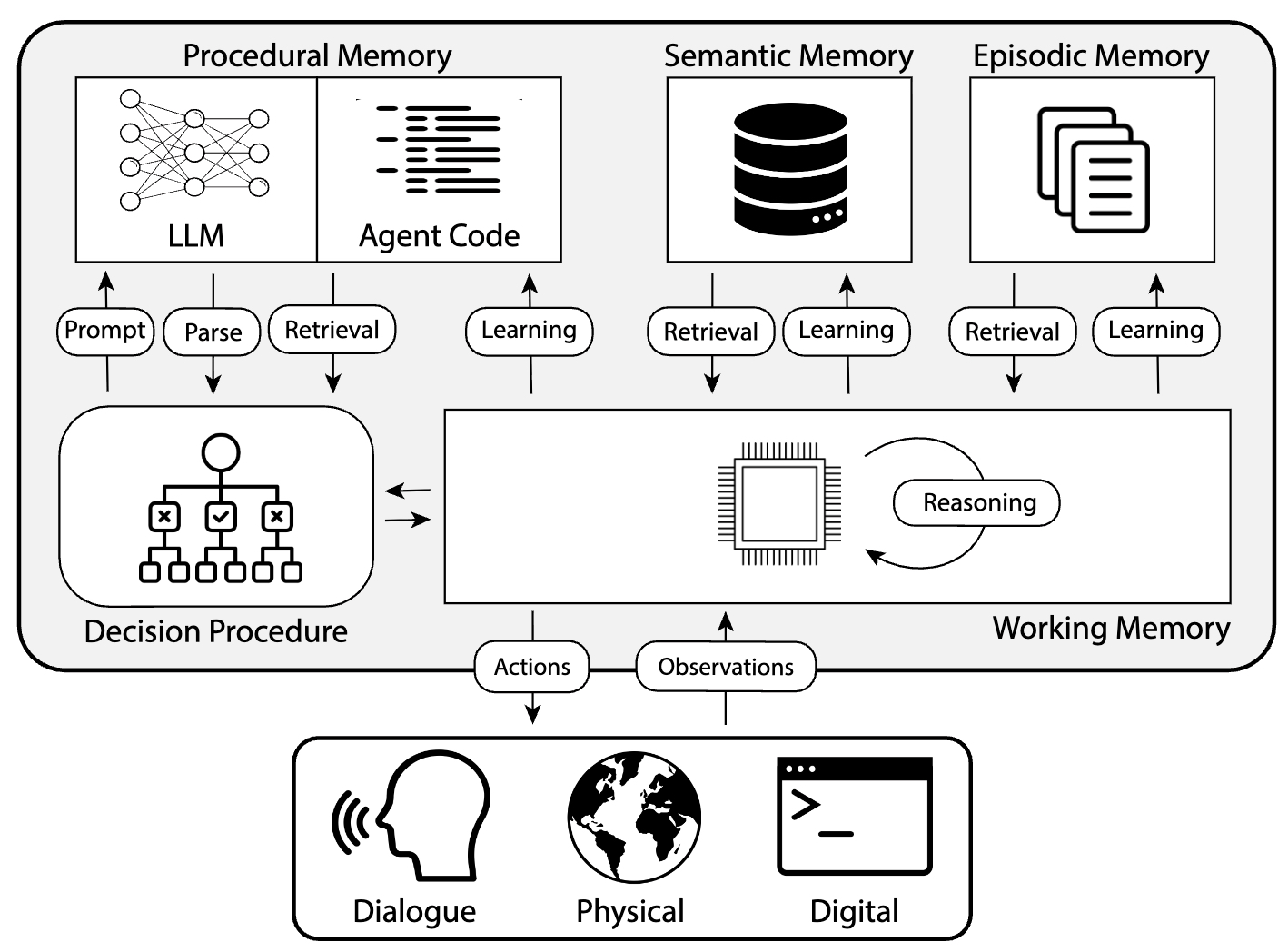
如图5-7所示,它展示了一个典型的智能体记忆系统架构,于2024年由普林斯顿大学所提出。CoALA 借鉴了人类认知科学中的记忆分类方式,将智能体的记忆划分为程序记忆、语义记忆和情景记忆以及工作记忆(短期记忆)4个部分。
在智能体运行过程中,外部环境会持续向智能体提供观察,短期记忆则负责对当前任务的状态进行临时存储与推理,智能体通过检索不同类型的记忆,结合决策过程生成对应动作,并与数字世界、物理世界以及对话场景进行交互。同时,系统还能将新的经验反向写入长期记忆中,从而实现动态学习与持续进化。整个架构体现了现代 AI 智能体从“单次生成”向“具备长期记忆与自主学习能力”的重要演进方向。
5.5.3 语义记忆#
语义记忆用于存储关于用户、组织或其他实体的具体事实、规则和结构化信息,最典型的应用场景就是个性化信息,让 Agent 记住用户的姓名、年龄、偏好、工作等个人信息,从而使智能体具备知识检索与持续学习的能力。
在具体实现上,语义记忆有两种存储方式,用户画像和记忆集合 [4]。
(1)用户画像
用户画像(Profile)把所有需要记住的信息维护成一份可持续更新的 JSON 文档,原理如图5-8所示。
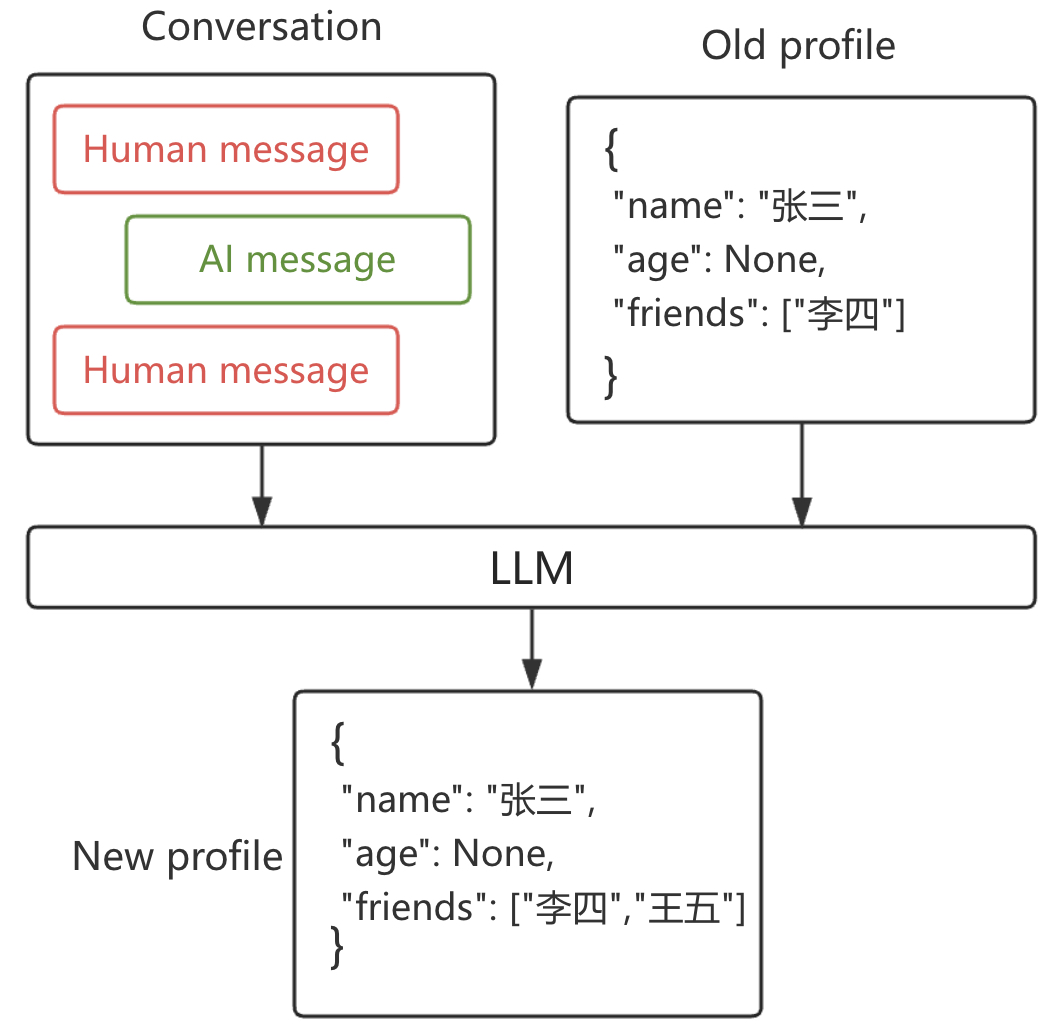
如图5-8所示,当用户和大模型在交互过程中有新的息产生时,旧的用户画像和新的信息将会一同被传给大模型,让模型生成更新后的用户画像。可以看出,这种方法的优点是信息集中、上下文完整;但缺点也很明显,随着画像内容大增加更新过程会很容易出错,也容易丢失细节,可能需要拆分文档或使用严格解码来确保 JSON 格式有效。关于用户画像的详细记忆示例可以参见 Code/Chapter05/profile_memory.json 文件。
(2)记忆集合
记忆集合(Collection)把每条记忆单独存储为一个文档,随着交互不断追加新的文档,原理如图5-9所示。
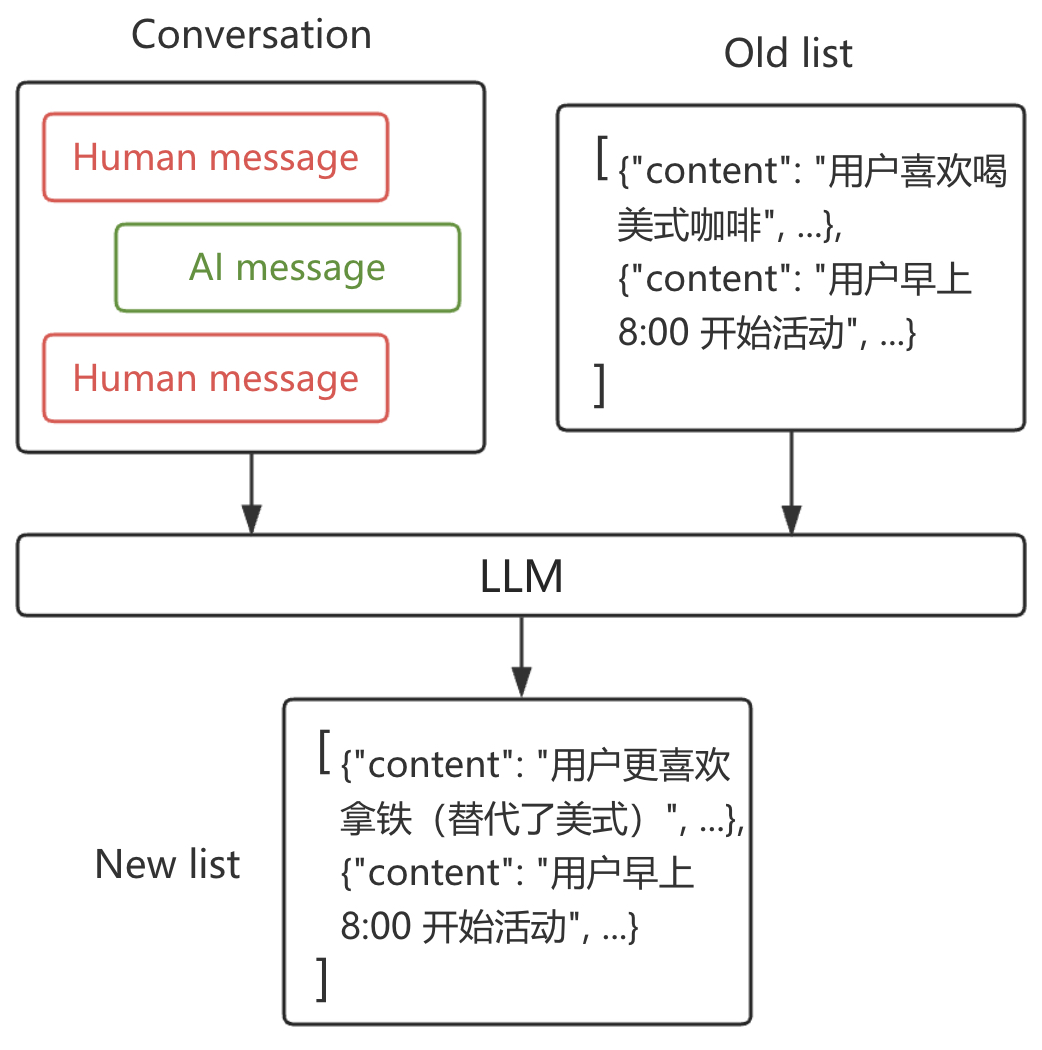
如图5-9所示,记忆集合由多个相互独立的记忆片段组成列表,其优点是每条记忆粒度小、不容易丢信息,如果是新产生的信息则更简单,只需要在列表中新加入一条内容即可;缺点是模型在删除或更新旧条目时会变得复杂(容易发生过度插入或过度更新),此外分散的片段可能导致模型缺乏对记忆之间关系的全局理解。
这里过度插入指模型有可能错判当前信息为新的信息而直接插入导致记忆间出现有冲突;过度更新则是指模型表现过于“积极”,在处理新信息时,会错误地覆盖或修改原本不该变动的现有记忆。对于这类问题,可以借助像 Trustcall [5] 这样的工具包来更精确地管理记忆的增删改查逻辑。关于记忆集合的详细记忆示例可以参见 Code/Chapter05/collection_memory.json 文件。
总结起来就是,如果用户信息相对固定、字段清晰可预设(如偏好语言、常用工具),用户画像是更简洁的选择;如果信息随时间持续积累、难以预设所有字段,记忆集合的扩展性则更好。
5.5.4 情景记忆#
情景记忆中存储的不是事实,而是侧重于 Agent 过去执行任务的经历(操作序列)和结果。情景记忆最常见的实现方式是少样本示例(Few-shot Examples),把历史上成功的输入输出案例存储起来,在新任务到来时检索出最相关的案例放入提示词中来引导大模型模仿预期的行为,使系统能够基于过去经验进行决策优化。
总结起来就是,情境记忆让智能体能够通过看到过去具体成功的案例或交互序列来学习复杂的任务处理模式,从而在面对相似场景时提供更准确、更符合预期的表现。
5.5.5 程序记忆#
程序记忆主要负责保存模型的能力与执行规则,包括大语言模型本身以及智能体的代码逻辑,它决定了智能体执行任务、调用工具以及进行决策的行为方式。在现代 AI 智能体系统中,程序记忆通常由系统提示词、智能体代码以及大模型权重共同构成,其中模型权重中蕴含着通过大规模预训练或微调获得的隐式知识,例如语言理解、推理能力和任务执行模式;而智能体代码、提示词等则包含显式知识,用于定义工作流程、工具调用、检索逻辑以及决策规则等内容。
与语义记忆或情景记忆不同,程序记忆通常需要在系统初始化阶段由开发者预先设定。例如,智能体启动时所加载的提示词、智能体工作流代码以及模型本身,这些都是其程序性记忆的重要组成部分。同时,修改程序记忆往往具有更高的风险,错误的提示词、代码逻辑或模型更新,可能导致智能体行为偏离预期,甚至引发系统漏洞。因此,在工业级 AI 系统中,通常会尽量保持代码层的确定性与稳定性,而将灵活性更多交给大语言模型的推理过程,以平衡系统的可控性与适应能力。
5.5.6 记忆写入方式#
在清楚存什么记忆以后另一个重要的设计决策就是什么时候写入记忆。根据提供的来源或之前的对话,写入记忆在智能体架构中被视为一种学习行为,即将信息从短期记忆或外部观察持久化到长期记忆中。在 LangGraph 等框架中,长期记忆的写入主要有两种方式,其原理示意如图5-10所示。
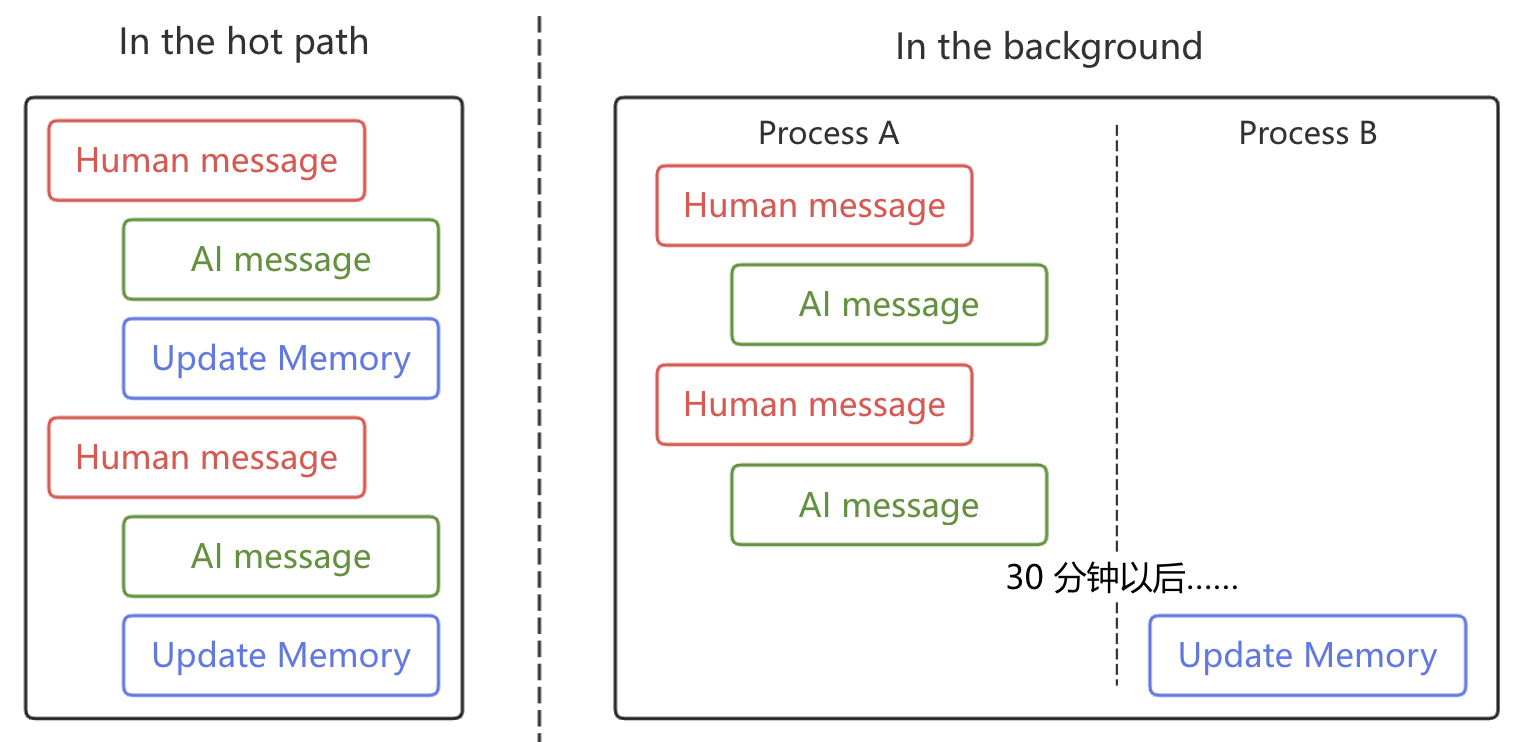
在图5-10中,左右两边分别是热路径写入和后台写入的原理示意图,他们各自具有不同的优缺点和应用场景。
(1)热路径写入
热路径写入 (In the Hot Path)的原理是在智能体运行的过程中实时创建记忆。智能体在响应用户之前,会先通过推理决定哪些信息值得记住,并立即将其写入存储库。热路径写入的优势在于即时性和透明性,新生成的记忆在接下来的下一次交互中立即可用,同时用户也可以清楚地看到智能体正在“记住”某些信息 [3]。例如,如果留心观察的话在使用 ChatGPT 的过程中,网页右侧偶尔就会有一个“记忆已更新”的提示。后续,我们主要用到的也将是热路径写入这种方式。
(2)后台写入
后台写入 (In the Background)的原理是将记忆的保存作为一个独立的异步任务来处理。智能体在对话流程中不负责写入记忆,而是通过定时任务、特定触发器或在会话结束后,由另一个专门的服务来梳理对话历史并提取记忆 [4]。后台写入的优势在于性能优越和逻辑分离,消除了主进程的延迟让智能体可以仅服务于当前任务,同时将应用逻辑与记忆管理逻辑完全解耦易于维护;但是不足在于如果更新频率太低,其他并行的会话线程可能无法及时获取最新的上下文信息。
5.5.7 长期记忆持久化#
在清楚了长期记忆的基本原理以后,我们再来看如何将其持久化保存。如果是以 Json 文件的形式直接保存到本地,那么直接使用 json.dumps() 然后写入到文件即可,在下一节内容中也将详细介绍这部分内容。如果是通过 LangGraph 保存到数据库中,则可以使用 PostgresStore 来完成,注意区分保存短期记忆时使用的是 PostgresSaver。以下完整示例代码参见 Code/Chapter05/C08_long_memory_store.py 文件。
首先定义一个函数来获取命名空间,示例代码如下:
1 def get_namespace(memory_root=MEMORY_ROOT,
2 urer_id: str = USER_ID) -> tuple[str, str]:
3 return memory_root, urer_id需要注意的是,命名空间可以由任意多个字段构成,例如这里指定了一个根标识和用户 ID。后续,在数据库中将会以 memory_root. urer_id 来标识每个用户对应的所有记忆。
其次,通过 PostgresStore 中的 put 方法来向数据库写入记忆,示例代码如下:
1 def save_normal_memory(store: PostgresStore, namespace: tuple[str, ...]):
2 store.put(namespace, key=str(uuid.uuid4()),
3 value={"memory_type": "语义记忆",
4 "created_at": datetime.now().isoformat(timespec="seconds"),
5 "text": "用户最喜欢的编程语言是 Python。"})
6 store.put(namespace, key=str(uuid.uuid4()),
7 value={"memory_type": "情景记忆",
8 "created_at": datetime.now().isoformat(timespec="seconds"),
9 "text": "2026-01-31,用户完成了一次 RAG 检索结果为空的排查。"})
10 print("新保存记忆结束2(条)\n")在上述代码中,一共写入了2条记忆,其中 put() 方法中最核心的3个参数 namespace、key 和 value 分别表示将记忆存储到哪个命名空间中,对应的记忆 ID 是什么以及记忆内容是什么。需要注意的是, value 是一个字典形式,可以携带任何需要的内容,将作为一个字段被保存到数据库中。
进一步,在记忆入库保存后,可以通过 store.delete(namespace, key) 和 store.get(namespace, key) 分别根据记忆ID来删除和获取对应命名空间下的记忆内容,当然获取记忆来说更常见的场景是根据用户提问检索相关记忆,这部分内容将在后续小节中进行介绍。
最后,可以通过如下方式来运行上述代码:
1 if __name__ == "__main__":
2 namespace = get_namespace()
3 with PostgresStore.from_conn_string(DB_URI) as store:
4 store.setup()
5 clear(store, namespace)
6 save_normal_memory(store, namespace)
7 print_search_result(store, namespace)在上述代码,第3~4行是连接数据库并初始化环境,此时数据库中将会自动创建 store 和 store_migrations 这两张表,其中记忆的文本内容便是保存在 store表中的。第5~7行则分别是情况当前命名空间下的所有以及、写入记忆以及输出当前命名空间中的记忆。
上述代码运行结束以后,将会看到类似如下内容:
01. key=078e620b-15e2-4e30-b39c-f214e04f8527
value={'text': '2026-01-31,用户完成了一次 RAG 检索结果为空的排查。', 'created_at': '2026-06-11T20:21:42', 'memory_type': '情景记忆'}
02. key=34de62ff-dc0e-4d25-ad3b-f7732784595f
value={'text': '用户最喜欢的编程语言是 Python。', 'created_at': '2026-06-11T20:21:42', 'memory_type': '语义记忆'}同时,在数据库中 store 表里将会出类似如下内容:
prefix | key | value |created_at|updated_at|expires_at|ttl_minutes
-----------+------+-------------------------+----------+----------+----------+-----------
memory.user|ea7...|{"text": "用户最...", ...}|2026-06...|2026-06...| NULL | NULL
memory.user|9d5...|{"text": "2026-...", ...}|2026-06...|2026-06...| NULL | NULL在上述结果中,prefix、key 和 value 分别对应上吗 store.put(namespace, key, value) 中的这3个参数;created_at 和 updated_at 是 LangGraph 框架自动填写的内容;expires_at 和 ttl_minutes 则是设置记忆的过期时效,后续内容将会介绍。
到此,我们就把长期记忆的原理及持久化方法介绍完了。在下一节内容中将会结合代码,介绍如何在实际应用中把短期记忆和长期记忆结合起来,构建一个能跨会话记住用户信息的完整系统。
引用#
[1] https://docs.langchain.com/oss/python/concepts/memory.md
[2] Sumers T, Yao S, Narasimhan K R, et al. Cognitive architectures for language agents[J]. Transactions on Machine Learning Research, 2023. https://arxiv.org/pdf/2309.02427
[3] ChatGPT 的记忆功能和新控件 https://openai.com/zh-Hans-CN/index/memory-and-new-controls-for-chatgpt/