更新于
2026年6月28日
朴素贝叶斯算法家族的核心思想都一样,均根据式(1)来进行建模
$$ y=\underset{{{c}_{k}}}{\mathop{\arg \max }}\,P(Y={{c}_{k}})\prod\limits_{j=1}^{n}{P}({{X}^{(j)}}={{x}^{(j)}}|Y={{c}_{k}})\tag{1} $$不同贝叶斯算法间的差异主要在于它们对条件概率 $P(X^{(i)}|Y=c_k)$ 的处理方式不同,这决定了它们分别适用于不同类型的特征数据 。
以下是Categorical(类别型)、Multinomial(多项式) 和 Gaussian(高斯) 朴素贝叶斯的主要区别:
1.类别型贝叶斯 (Categorical NB)#
- 适用特征:主要用于处理类别型取值(Discrete/Categorical)的特征变量 。
- 核心原理:它假设每个特征的取值都是离散的类别 。在计算条件概率时,它通过统计每个特征维度在各个类别下的分布情况(即每种取值出现的次数)来建模 。
- 应用场景:例如不考虑词频的词袋模型,仅记录单词“是否出现” 。
- 限制:如果测试集中出现了训练集中未涵盖的特征取值,模型可能无法取到对应的条件概率,除非使用平滑处理 。
2.多项式贝叶斯 (Multinomial NB)#
- 适用特征:主要用于处理离散计数型特征,特别是包含词频的文本向量表示 。
- 核心原理:它将每个维度的词频在总词频中的占比作为条件概率进行建模 。它考虑的是某个特征在特定类别下出现的频次在所有特征总频次中的占比,这被视为该特征在对应类别下的权重 。
- 应用场景:在文本分类中,它非常适合处理**词袋模型(词频计数)**或 TF-IDF 权重矩阵 。
3.高斯贝叶斯 (Gaussian NB)#
- 适用特征:主要用于处理连续型特征变量(如身高、温度、像素值等) 。
- 核心原理:它假定每个特征维度的条件概率均服从高斯分布(正态分布) 。它通过计算每个类别下每个特征的期望(均值)**和**方差来估算概率密度 。
- 应用场景:在处理数值型连续变量时效果显著,但也常被发现对某些离散型特征(如垃圾邮件分类中的文本特征)也有非常出色的效果 。
4.对比#
| 特性 | Categorical NB | Multinomial NB | Gaussian NB |
|---|---|---|---|
| 特征类型 | 类别/离散型 | 频次/计数型 | 连续/数值型 |
| 概率假设 | 类别分布 | 多项式分布 | 高斯(正态)分布 |
| 计算重点 | 特征取值的分类统计 | 特征频次占总频次的比例 | 均值与方差 |
| 典型应用 | 二值化词袋文本分类 | 词频计数、TF-IDF 文本分类 | 通用数值特征分类 |
进一步,使用垃圾邮件分类数据集,但采用不同特征处理方式,来对这3个模型进行一次交叉对比
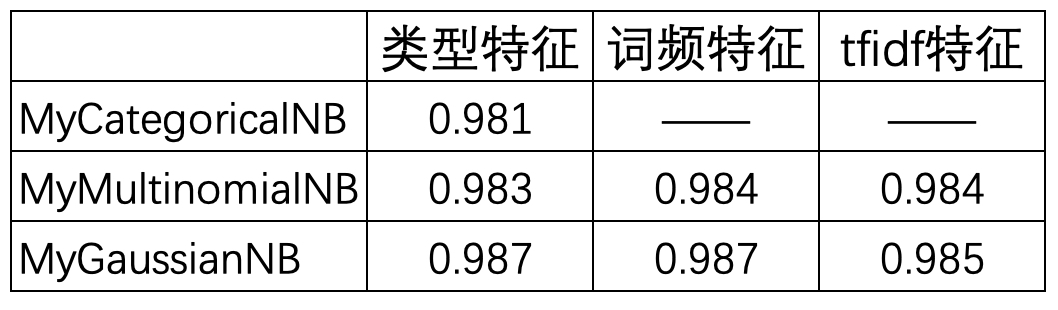
从表中可以看出,对于Categorical NB模型来说只能处理类型特征变量,而对于其它两个模型来说3种特征表示均适用。同时,考虑词频的Multinomial NB模型在效果上要略好于不考虑词频的Categorical NB模型。从模型效果来看,Gaussian NB模型无论是采用哪种特征表示方式,相较于其它两种模型其结果都是最好的,并且在这一数据集上不考虑词频的表示方法在Gaussian NB模型中的结果居然同考虑词频的结果里一致。因此,在实际情况中可以优先考虑使用Gaussian NB模型来进行建模。
5.总结#
在相同的垃圾邮件数据集上,Gaussian NB 通常表现最稳健且准确率最高,无论采用哪种特征表示方式;而 Multinomial NB 在考虑词频时的效果通常优于不考虑词频的 Categorical NB。
- Categorical NB 就像一个分类箱:它记录“红球”出现了几次,“绿球”出现了几次。
- Multinomial NB 就像一个统计员:他计算“红球”在所有球总数中的占比是多少,来判断这袋球的性质。
- Gaussian NB 就像一个测量员:他测量球的“平均重量”和“重量波动(方差)”,看这个球是否符合某种球类的标准正态分布。
阅读
--