在决策树或随机森林中,对于特征重要性的评估核心逻辑在于衡量一个特征在节点划分过程中对不确定性(不纯度)的减少程度。
1. 决策树中的特征重要性计算#
在单棵决策树中,特征重要性是基于该特征在所有节点分裂时所带来的基尼不纯度减少量的加权总和来计算的。
-
计算公式: 对于某个使用特征 $A$ 进行分裂的节点 $t$,其重要性增量计算如下:
$$ \text{importance} = \frac{N_t}{N} \times (\text{impurity} - \frac{N_{tL}}{N_t} \times \text{left\_impurity} - \frac{N_{tR}}{N_t} \times \text{right\_impurity}) $$其中,
- $N$:总样本数。
- $N_t$:当前节点的样本数。
- $\text{impurity}$:当前节点的基尼不纯度。
- $N_{tL}, N_{tR}$:左、右子节点的样本数。
- $\text{left\_impurity}, \text{right\_impurity}$:分别表示左、右子节点的基尼不纯度。
-
核心逻辑:越靠近决策树顶端(根节点)的特征通常越重要,因为它们能对更多类别的样本进行区分,带来的不纯度减少量通常更大。如果一个特征未参与任何节点的划分,其重要性则为 0。
以9.2.2节随机森林里的其中一棵决策树为例,其在每次进行节点划分时的各项信息如图9-3所示。
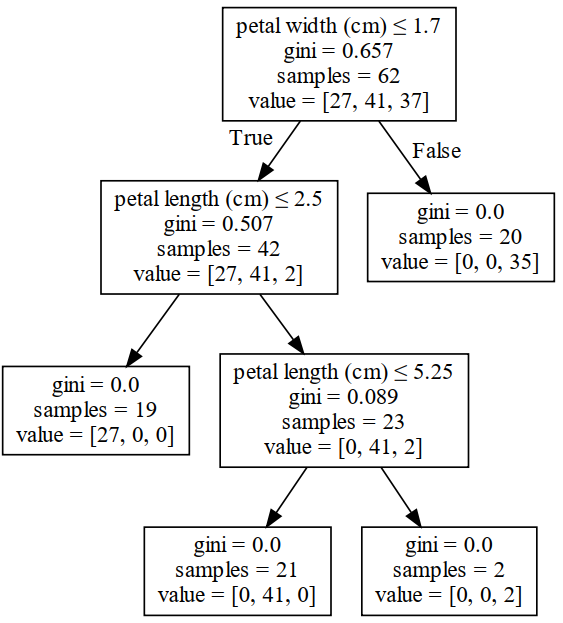
这里有一个细节需要注意,在图9-3中每个节点里samples的数量指的是不重复的样本数(因为采样会有重复),而列表value中的值则包含重复样本。例如在根节点中,samples=62表示一共有62个不同的样本点,但实际上该节点中有105个样本点,即有43个样本点为重复出现的样本点。
此时,对于特征petal width来讲,根据式(9-2)其特征重要性值为
$$ \frac{105}{105}\times \left( 0.657-\frac{70}{105}\times 0.507-\frac{35}{105}\times 0 \right)\approx 0.319\tag{9-3} $$对于特征petal length来讲,由于其在两次节点划分中均有参与,所以它的特征重要性为
$$ \frac{70}{105}\times \left( 0.507-\frac{27}{70}\times 0-\frac{43}{70}\times 0.089 \right)+\frac{43}{105}\times \left( 0.089-0 \right)\approx 0.338\tag{9-4} $$对于另外两个特征sepal length和sepal width来讲,由于两者并没有参与决策树节点的划分,所以其重要性均为0。
2. 随机森林中的特征重要性(MDI)#
随机森林评估特征重要性的主流方法是平均不纯度减少量(Mean Decrease in Impurity, MDI)。
- 计算方式:将森林中所有决策树对该特征计算出的重要性值取平均值。
- 优势:由于随机森林引入了特征采样(Feature Bagging),不同的树会关注不同的特征组合。通过对多棵树的结果求平均,可以更稳健地评估特征的真实贡献,减小单一模型带来的偏差。
对于第9.2.2节中的随机森林,其两棵决策树对应的计算所得到特征重要性(未标准化)如表9-2所示。

在sklearn中,对于决策树计算得到的特征重要性值默认情况下还会进行标准化,即每个维度均会除以所有维度的和。进一步,对于随机森林来讲,其各个特征的重要性值则为所有决策树对应特征重要性的平均值,因此,对于表9-2中的结果来讲最终每个特征重要性值为0、0、0.729和0.271。
3. 标准化处理#
在实际应用中(如 sklearn 框架),计算出的各特征重要性值通常会进行标准化处理,即每个特征的重要性值除以所有特征重要性值的总和,使得所有特征的重要性之和等于 1。这便于直观地比较各特征之间的相对贡献度。
比喻理解: 这就像在一家工厂里评估 “质检员的工作价值” 。如果一位质检员(特征)在分拣零件时,能一次性把混杂的零件堆(高不纯度)清晰地分给后续的生产线,且他处理的零件数量非常多,那么他的贡献就很大。我们将他在所有分拣环节中减少的“混乱程度”累加起来,就能得出他的重要性评分。而在“随机森林”中,这就相当于查看这位质检员在多个不同车间(决策树)里的平均表现。