我相信你肯定注意到每次在使用 ChatGPT 或 Claude 的时候,第一个 Token 出现的时间明显更长,随后其余的 Token 几乎瞬间就会输出。
在这背后,是一个被称为 KV 缓存的精心设计,其目的便是让大语言模型(LLM)推理速度更快。
在深入探讨这个技术的细节之前,我们可以来看一下有无 KV 缓存时大语言模型推理的速度对比情况
可以明显看到,有 KV 缓存时的推理速度要远远快于没有 KV 缓存时的推理速度,前者约9秒,而后者则需要39秒。
现在让我们从第一性原理出发,来看看 KV 缓存它到底是如何工作的。
1. 大语言模型如何生成 Token#
Transformer 在处理所有输入的 Token 时将会为每个 Token 生成一个隐藏状态,然后这些隐藏状态将会被投影到词表空间并生成对数概率(词表中每个词对应一个分数)。
并且,我们在预测下一个输出 Token 时,只会用到输出结果的最后一个 Token 对应的概率值。最后,我们将从这些对数概率中采样,得到下一个 Token ,将其追加到输入中,然后重复这个过程。
注意,非常重要的一点是:要生成下一个 Token ,你只需要最后一个 Token 的隐藏状态即可, 其他所有隐藏状态都是中间副产品。
2. 注意力机制计算过程#
在每个 Transformer 层中,每个 Token 都将会计算得到3个向量:查询向量(Q)、键向量(K)和值向量(V)。注意力机制将查询Q与键K相乘得到的注意力权重对 V 进行加权计算,如图下图所示。
此时只需要关注最后一个 Token ,如下图。
可以看到,对于 $QK^T$ 的最后一行来说,它的输入为:
- 最后一个 Token 的查询向量 $Q$(这里是 $Q_4$)
- 以及整个序列中的所有 $K$ 向量($K_1,...,K_4$)
同时,对于自注意力输出结果的最后一行来说,它的输入为:
- 最后一个 Token 的查询向量 $Q$ (这里是 $Q_4$)
- 以及整个序列中的对应的所有 $K$(这里是 $K_1,...,K_4$)和 $V$ (这里是 $V_1,...,V_4$)。
因此,为了计算我们所需的唯一隐藏状态,每个注意力层只需要新的 $Q$,以及序列对应的所有 $K$ 和 $V$。
3. 计算冗余#
到此,我们清楚了 LLM 逐时刻生成下一个 Token 的机制,但是这其中却存在着计算冗余的地方。
例如,在生成第 50 个 Token 时需要第1个 Token 到第 50 个 Token 对应的 $K$ 和 $V$ 向量。同理生成第 51 个 Token 时需要第1个 Token 到第 51 个 Token 对应的 $K$ 和 $V$ 向量
然而,对于第1个 Token 到第 49 个 Token 来说它们的 $K$ 和 $V$ 向量已经计算过了,并且没有改变。因为只要输入相同那么输出也一定是相同的。但是模型在整个过程中每一次生成下一个 Token 的时候都要从头重新计算它们。
每一步都有 $O(n)$ 的冗余工作。在整个迭代中,会有$O(n^2)$的计算被浪费。
4. 解决方法#
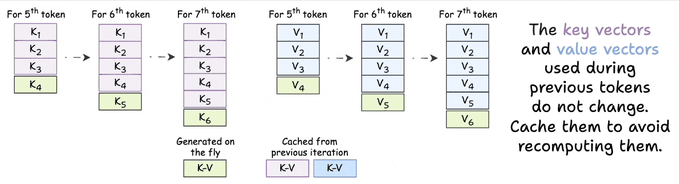
与其在每一步都重新计算所有的K和V向量,不如将它们存储起来。此时,对于每个新 Token 的生成:
- 仅需要为最新的 Token 计算 $Q$、$K$ 和 $V$ 。
- 然后,将新的 K 和 V 追加到缓存中。
- 接着,从缓存中检索所有先前的 $K$ 和 $V$ 向量。
- 使用新的 $Q$ 对完整缓存的 $K$ 和 $V$ 运用注意力机制。
这就是KV缓存,它通过将当前时刻计算得到的新的 $K$ 和 $V$ (这里便是 $K_{\text{cluster}}$ 和 $V_{\text{cluster}}$)与先前所有时刻缓存的 $K$ cache 和 $V$ cache 拼接得到完整的 $K$ 和 $V$ ,最后与 $Q_{\text{cluster}}$ 完成整个注意力机制的计算。
此时注意力计算仍然与序列长度成正比(因为我们需要关注所有的 $K$ 和 $V$),但生成 $K$ 和 $V$ 的计算开销却得到了极大的降低,因为每个 Token 只进行一次计算,而不是每一步都计算。
5. 生成第1个 Token 所耗费的时间#
现在你可能已经明白为什么第1个 Token 处理速度慢了。
因为当你发送提示词时,模型会在第一次前向传播中处理整个输入,为每个 Token 计算并缓存 $K$ 和 $$ V向量,所以将会有大量的计算过程,这也是预填充阶段。
一旦缓存预热完成,后续生成的每一个 Token 仅需对当前时刻一个 Token 进行前向传播计算,所以推理速度将会大幅提升。
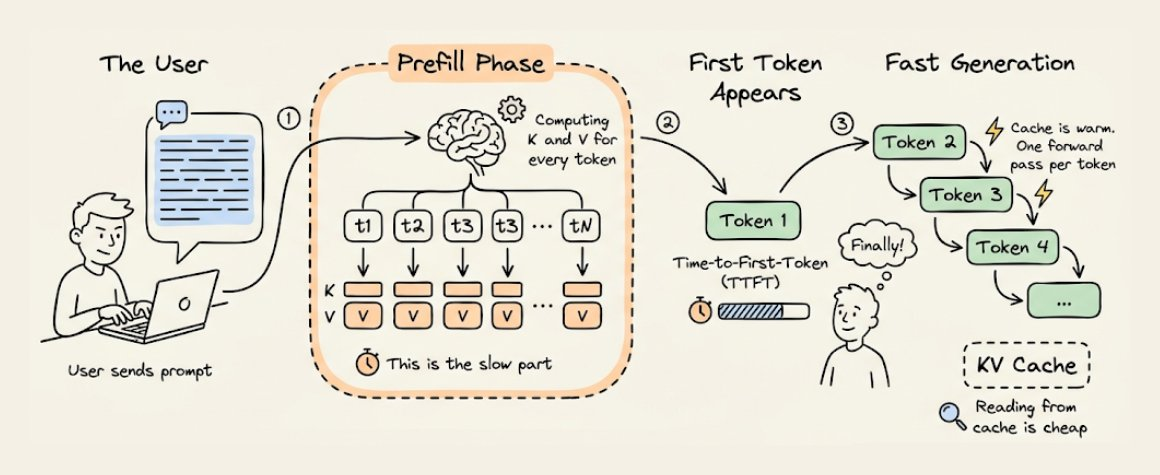
这种初始延迟被称为首次 Token 时间(Time-To-First-Token, TTFT)。更长的提示词意味着更长的预填充,也就意味着更长的等待时间。优化 TTFT(分块预填充、推测性解码、提示缓存)本身就是一个深奥的话题,但其中的原理始终相同:即构建缓存成本高昂,而读取缓存则成本低廉。
6. 时间与空间的权衡#
KV 缓存以计算换取内存。 由于每一个注意力层都会为每个 Token 缓存 $K$ 和 $V$ 向量,例如对于Qwen 2.5 72B(80层、32K上下文、模型维度 8192)来说,单个请求的 $KV$ 缓存可能就会消耗几GB 的 GPU 显存,在数百个并发请求的情况下,其占用的显存常常会超过模型权重本身。
所以,这就是分组查询注意力(GQA)和多查询注意力(MQA)存在的原因:在查询头之间共享键/值头,减少内存占用,同时将质量损失降至最低。
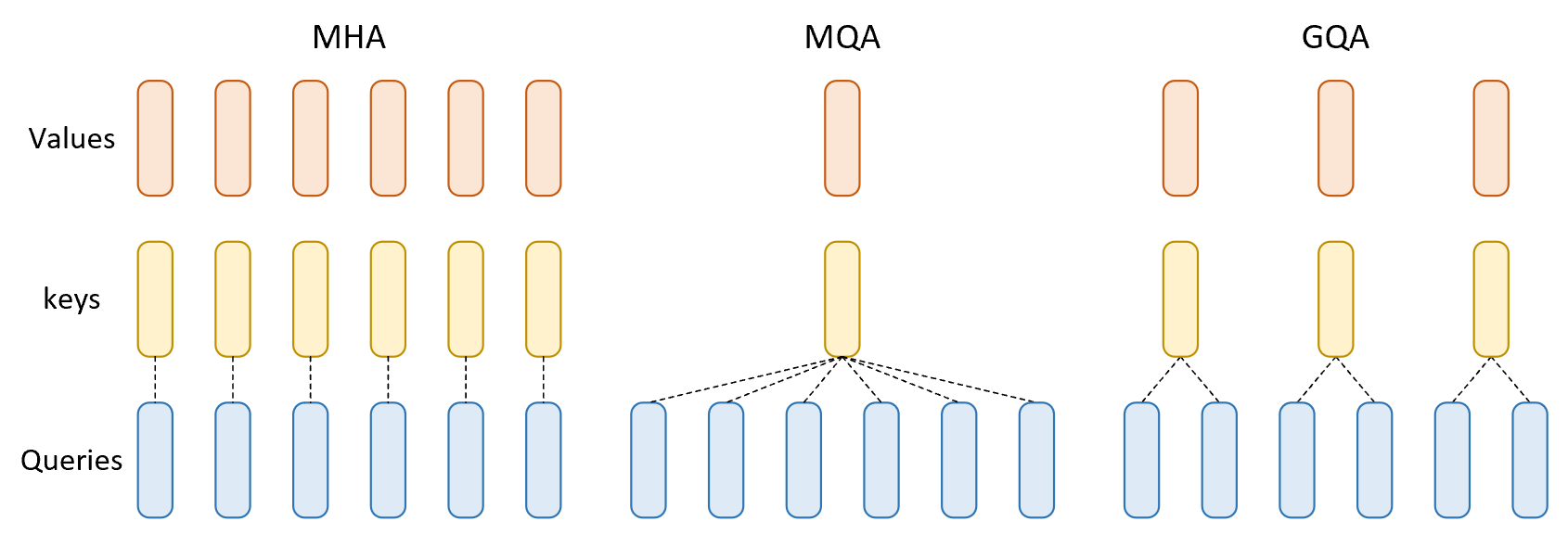
这同样也是为什么将上下文长度加倍很困难的原因,因为窗口加倍,每个请求的 KV 缓存也会加倍,并发用户就会减少。
KV 缓存消除了自回归生成过程中的冗余计算。 由于之前的 Token 总是产生相同的 $K$ 和 $V$ 向量,因此只需在第一次计算时缓存它们,后续每个新 Token 只需要自己的 $Q$、$K$ 和 $V$,然后注意力机制在完整的缓存上进行计算即可。
在前面实践中,虽然 KV 缓存实现了5倍的加速,但代价是 GPU 显存的增加。所以在大规模应用时,它便成为了关键的限制因素。
本文为翻译内容,原作者:@_avichawla